零基础教你写python爬虫
大家都知道python经常被用来做爬虫,用来在互联网上抓取我们需要的信息。
使用Python做爬虫,需要用到一些包:
requests
urllib
BeautifulSoup
等等,关于python工具的说明,请看这里:Python 爬虫的工具列表今天介绍一个简单的爬虫,网络聊天流行斗图,偶然发现一个网站www.doutula.com.上面的图片挺搞笑的,可以摘下来使用。
我们来抓一下“最新斗图表情”:
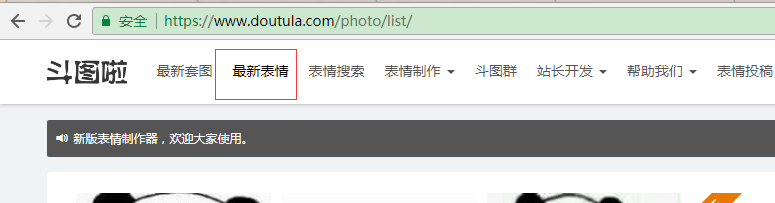
看到下面有分页,分析下他的分页url格式:

不难发现分页的url是:https://www.doutula.com/photo/list/?page=x
一步步来:
先简单抓取第一页上的图片试试:
将抓取的图片重新命名,存储在项目根目录的images目录下:
分析网页上img格式:
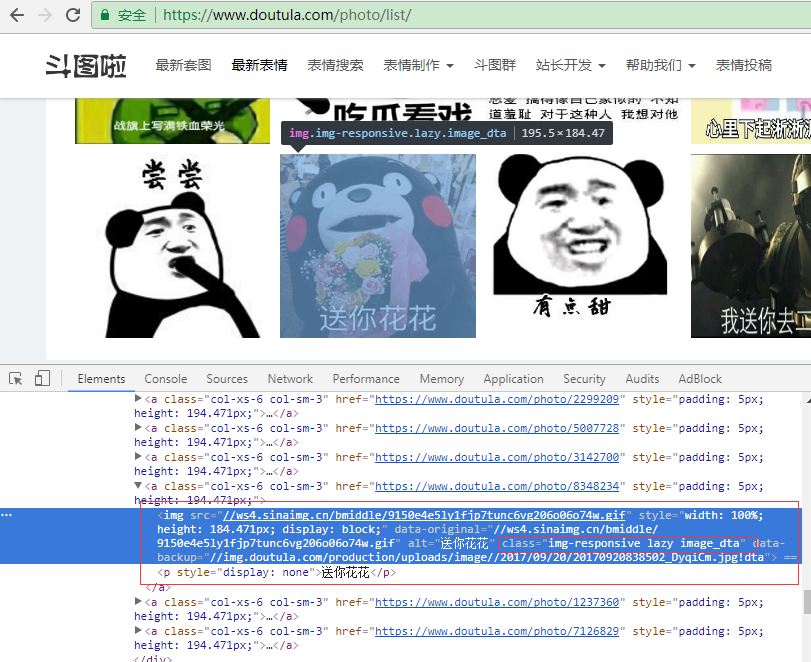
好了,我们开始准备写程序吧:使用pycharm IDE创建项目
我们抓包会用到:requests 和urllib,需要先安装这些包:file->default settings
点击右侧绿色的+号:
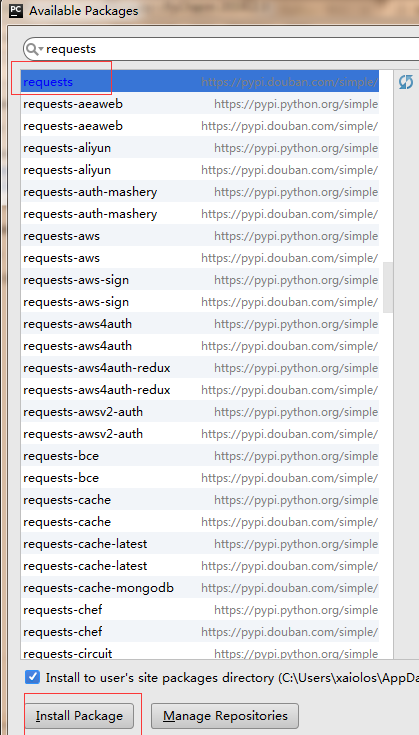
同样的引入:BeautifulSoup,lxml
接下来就可以引入这些包,然后开始开发了:
- import requests
- from bs4 import BeautifulSoup
- import urllib
- import os
- url = 'https://www.doutula.com/photo/list/?page=1'
- response = requests.get(url)
- soup = BeautifulSoup(response.content,'lxml')
- img_list = soup.find_all('img',attrs={'class':'img-responsive lazy image_dta'})
- i=0
- for img in img_list:
- print (img['data-original'])
- src = img['data-original']
- #src = '//ws1.sinaimg.cn/bmiddle/9150e4e5ly1fjlv8kgzr0g20ae08j74p.gif'
- if not src.startswith('http'):
- src= 'http:'+src
- filename = src.split('/').pop()
- fileextra = filename.split('.').pop()
- filestring = i+'.'+fileextra
- path = os.path.join('images',filestring)
- # 下载图片
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
- 'Accept-Encoding': 'gzip, deflate, sdch',
- 'Accept-Language': 'zh-CN,zh;q=0.8',
- 'Connection': 'keep-alive',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
- }
- #urllib.request.urlretrieve(url,path,header)
- req = urllib.request.Request(url=src, headers=headers)
- cont = urllib.request.urlopen(req).read()
- root = r""+path+""
- f=open(root,'wb')
- f.write(cont)
- f.close
- i += 1
注意:
1.请求的时候需要加上header,伪装成浏览器请求,网站大多不允许抓取。
抓完一页的图片,我们试着抓取多页的图片:这里试下抓取第一页和第二页的图片
- import requests
- from bs4 import BeautifulSoup
- import urllib
- import os
- import datetime
- #begin
- print (datetime.datetime.now())
- URL_LIST = []
- base_url = 'https://www.doutula.com/photo/list/?page='
- for x in range(1,3):
- url = base_url+str(x)
- URL_LIST.append(url)
- i = 0
- for page_url in URL_LIST:
- response = requests.get(page_url)
- soup = BeautifulSoup(response.content,'lxml')
- img_list = soup.find_all('img',attrs={'class':'img-responsive lazy image_dta'})
- for img in img_list: #一页上的图片
- print (img['data-original'])
- src = img['data-original']
- if not src.startswith('http'):
- src= 'http:'+src
- filename = src.split('/').pop()
- fileextra = filename.split('.').pop()
- filestring = str(i)+'.'+fileextra
- path = os.path.join('images',filestring)
- # 下载图片
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
- 'Accept-Encoding': 'gzip, deflate, sdch',
- 'Accept-Language': 'zh-CN,zh;q=0.8',
- 'Connection': 'keep-alive',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
- }
- #urllib.request.urlretrieve(url,path,header)
- req = urllib.request.Request(url=src, headers=headers)
- cont = urllib.request.urlopen(req).read()
- root = r""+path+""
- f=open(root,'wb')
- f.write(cont)
- f.close
- i += 1
- #end
- print (datetime.datetime.now())
这样我们就完成了多页图片的抓取,但是貌似有点慢啊,要是抓所有的,那估计得花一点时间了。
python是支持多线程的,我们可以利用多线程来提高速度:
分析一下这是怎么样的一个任务:我们将网页地址全部存储到一个list中,所有的图片地址也存储在一个list中,然后按顺序来取图片地址,再依次下载
这样类似一个:多线程有序操作的过程,就是“消费者生产者模式”,使用list加锁来实现队列(FIFO先进先出)。
一起回忆一下队列的特点吧:
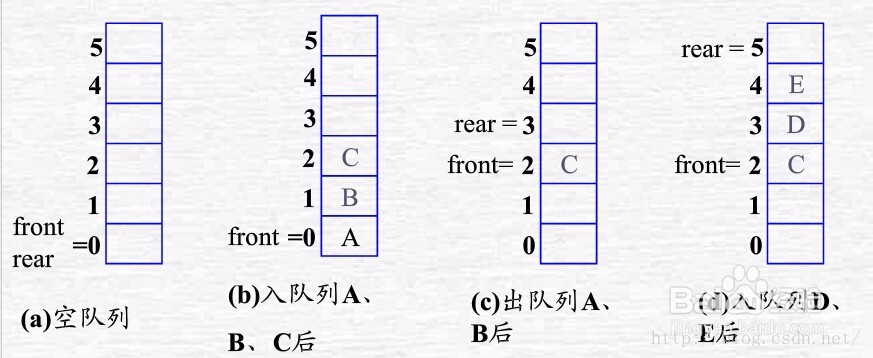
看代码吧:我们下载第一页到第99页的图片
- import requests
- from bs4 import BeautifulSoup
- import urllib
- import os
- import datetime
- import threading
- import time
- i = 0
- FACE_URL_LIST = []
- URL_LIST = []
- base_url = 'https://www.doutula.com/photo/list/?page='
- for x in range(1,100):
- url = base_url+str(x)
- URL_LIST.append(url)
- #初始化锁
- gLock = threading.Lock()
- #生产者,负责从页面中提取表情图片的url
- class producer(threading.Thread):
- def run(self):
- while len(URL_LIST)>0:
- #访问时需要加锁
- gLock.acquire()
- cur_url = URL_LIST.pop()
- #使用完后及时释放锁,方便其他线程使用
- gLock.release()
- response = requests.get(cur_url)
- soup = BeautifulSoup(response.content, 'lxml')
- img_list = soup.find_all('img', attrs={'class': 'img-responsive lazy image_dta'})
- gLock.acquire()
- for img in img_list: # 一页上的图片
- print(img['data-original'])
- src = img['data-original']
- if not src.startswith('http'):
- src = 'http:' + src
- FACE_URL_LIST.append(src)
- gLock.release()
- time.sleep(0.5)
- #消费者,负责从FACE_URL_LIST中取出url,下载图片
- class consumer(threading.Thread):
- def run(self):
- global i
- j=0
- print ('%s is running' % threading.current_thread)
- while True:
- #上锁
- gLock.acquire()
- if len(FACE_URL_LIST) == 0:
- #释放锁
- gLock.release()
- j = j + 1
- if (j > 1):
- break
- continue
- else:
- #从FACE_URL_LIST中取出url,下载图片
- face_url = FACE_URL_LIST.pop()
- gLock.release()
- filename = face_url.split('/').pop()
- fileextra = filename.split('.').pop()
- filestring = str(i) + '.' + fileextra
- path = os.path.join('images', filename)
- #path = os.path.join('images', filestring)
- # 下载图片
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
- 'Accept-Encoding': 'gzip, deflate, sdch',
- 'Accept-Language': 'zh-CN,zh;q=0.8',
- 'Connection': 'keep-alive',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
- }
- # urllib.request.urlretrieve(url,path,header)
- req = urllib.request.Request(url=face_url, headers=headers)
- cont = urllib.request.urlopen(req).read()
- root = r"" + path + ""
- f = open(root, 'wb')
- f.write(cont)
- f.close
- print(i)
- i += 1
- if __name__ == '__main__': #在本文件内运行
- # begin
- print(datetime.datetime.now())
- #2个生产者线程从页面抓取表情链接
- for x in range(2):
- producer().start()
- #5个消费者线程从FACE_URL_LIST中提取下载链接,然后下载
- for x in range(5):
- consumer().start()
- #end
- print (datetime.datetime.now())
看看images文件夹下多了好多图,以后斗图不用愁了!
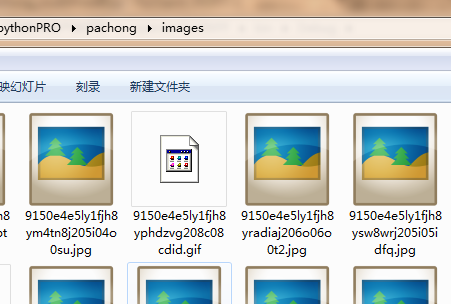
OK,到此算是结束了。最后为python宣传一下。

零基础教你写python爬虫的更多相关文章
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
- [原创]手把手教你写网络爬虫(4):Scrapy入门
手把手教你写网络爬虫(4) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 上期我们理性的分析了为什么要学习Scrapy,理由只有一个,那就是免费,一分钱都不用花! 咦?怎么有人扔西红柿 ...
- [原创]手把手教你写网络爬虫(5):PhantomJS实战
手把手教你写网络爬虫(5) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 大家好!从今天开始,我要与大家一起打造一个属于我们自己的分布式爬虫平台,同时也会对涉及到的技术进行详细介绍.大 ...
- 教你用python爬虫监控教务系统,查成绩快人一步!
教你用python爬虫监控教务系统,查成绩快人一步!这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路:设计思路很简单,首先对已有的成绩 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- 零基础小白怎么用Python做表格?
用Python操作Excel在工作中还是挺常用的,因为毕竟不懂Excel是一个用户庞大的数据管理软件.本文用Python3!在给大家分享之前呢,小编推荐一下一个挺不错的交流宝地,里面都是一群热爱并在学 ...
- [零基础学pythyon]安装python编程环境
不论什么高级语言都是须要一个自己的编程环境的,这就好比写字一样,须要有纸和笔,在计算机上写东西.也须要有文字处理软件,比方各种名称的OFFICE.笔和纸以及office软件,就是写东西的硬件或软件.总 ...
- 致初学者:零基础如何学好,Python这门编程语言?
前言对于很多Python这门编程语言的初学者,往往会面临以下问题: Python2和Python3我该学习哪一个?是否要安装Linux系统学习Python?Python3有各种版本我该安装哪一个?那么 ...
- Python零基础学习系列之三--Python编辑器选择
上一篇文章记录了怎么安装Python环境,同时也成功的在电脑上安装好了Python环境,可以正式开始自己的编程之旅了.但是现在又有头疼的事情,该用什么来写Python程序呢,该用什么来执行Python ...
随机推荐
- Java 多线程笔记
资料来源于网络,仅供参考学习. 1.A Java program ends when all its threads finish (more specifically, when all its ...
- rpc之thrift
rpc之thrift 一.介绍 thrift是一个rpc(remove procedure call)框架,可以实现不同的语言(java.c++.js.python.ruby.c#等)之间的相互调用. ...
- java web 之 AJAX用法
AJAX :Asynchronous JavaScript And XML 指异步 JavaScript 及 XML一种日渐流行的Web编程方式 Better Faster User-Friendly ...
- 设计模式学习(三): 装饰者模式 (附C#实现)
需求 做一个咖啡店的订单系统. 买咖啡时,可以要求加入各种调料,如奶,豆浆,摩卡等.咖啡店会根据调料的不同收取不同的费用.订单系统要考虑这些. 初版设计 然后下面就是所有的咖啡....: cost方法 ...
- centos下卸载OpenJDK 并安装sun的jdk
centos下卸载OpenJDK 并安装sun的jdk 第一步:查看并卸载CentOS自带的OpenJDK 安装好的CentOS会自带OpenJdk,用命令 java -version ,我这里显示下 ...
- windows系统安装securtCRT
说明:securtCRT可以ssh liunx主机,或者网络设备,如路由器,交换机,防火墙等设备,很多新手不会安装,因为正版要钱啊,对于小老百姓,还是用破解的吧 不说废话,开始搞起来. 软件下载链接: ...
- flask-日料网站搭建
引言:想使用python的flask框架搭建一个日料网站,主要包含web架构,静态页面,后台系统,交互. 本节知识:搭建web目录,目前正在copy网站. python环境:python2.7,fla ...
- Spring Boot快速入门(四):使用jpa进行数据库操作
原文地址:https://lierabbit.cn/articles/5 添加依赖 新建项目选择web,JPA,MySQL三个依赖 对于已存在的项目可以在bulid.gradle加入,spring b ...
- spring官方学习地址
1.http://projects.spring.io/spring-framework/ 2.https://github.com/spring-projects/spring-mvc-showca ...
- 应用服务器GC回收常见问题总结
近一段时间多次发现因GC问题造成系统性能问题(应用服务间歇性响应缓慢.应用服务器CPU占用较高等),在此总结一下: 1.代码中直接调用GC.Collect() 2.字符串等操作频繁的内存申请 3.频繁 ...