Day2 基本数据类型
一、python数据类型
1.1数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
1.1.1int(整型)
在32位机器上,整数的位数为32位,取值范围为-2^31~2^31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2^63~2^63-1,即-9223372036854775808~9223372036854775807
1.1.2long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
1.1.3float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
1.1.4complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
1.2布尔值
真或假
1 或 0
1.3 字符串
"hello world"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化输出
1 2 3 4 name ="chuck" print"i am %s "% name #输出: i am chuck
注: 字符串是 %s;整数 %d;浮点数%f
字符串常用功能:
移除空白,分割,长度,索引,切片。
1.4 列表(具体在下一章会有详细的详解)
创建列表:
name_list =['alex','seven','eric'] 或 name_list = list(['alex','seven','eric'])
基本操作
索引,切片,追加,删除,长度,循环,包含
1.5 元组
元组其实就是一种不可变的列表,内容不允许改变。
创建元组
ages =(11,22,33,44,55) 或 ages = tuple((11,22,33,44,55))
常用操作
索引,新增,删除,键值对,循环,长度
二、数据运算
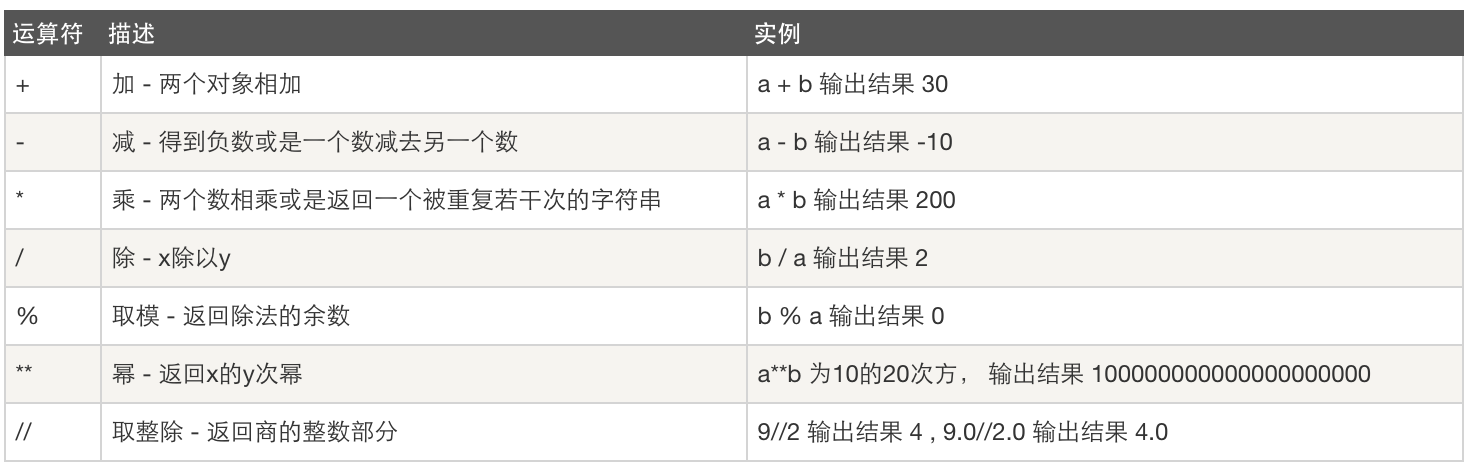
2.1算数运算
2.2比较运算

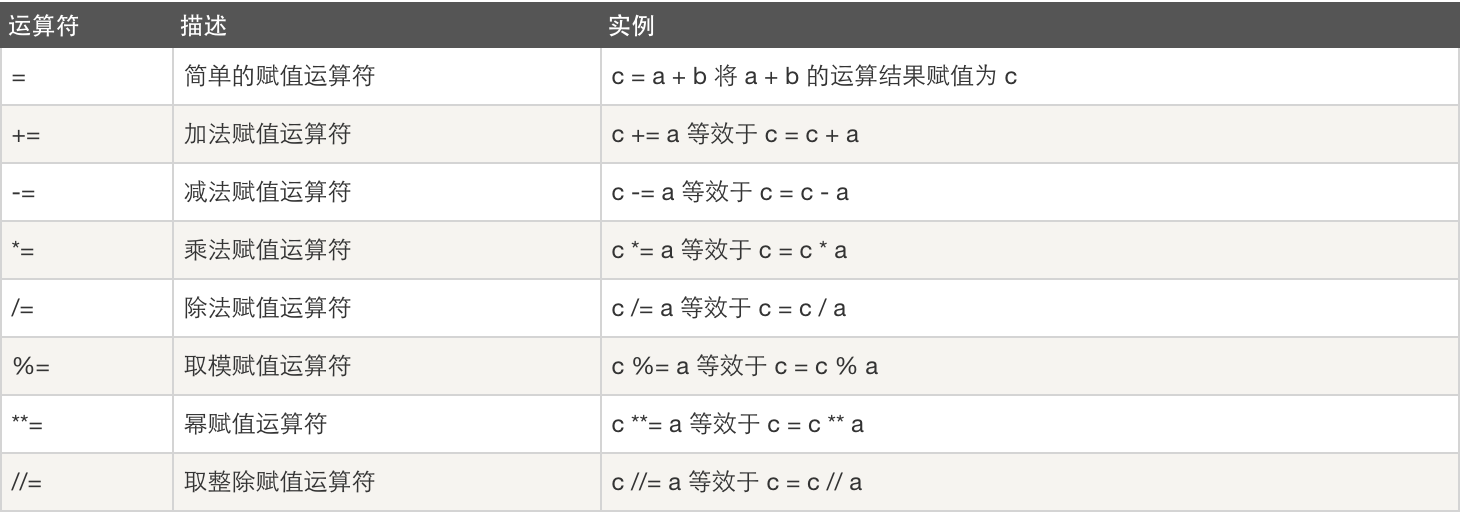
2.3赋值运算
2.4逻辑运算

2.5成员运算

2.6身份运算

2.7位运算
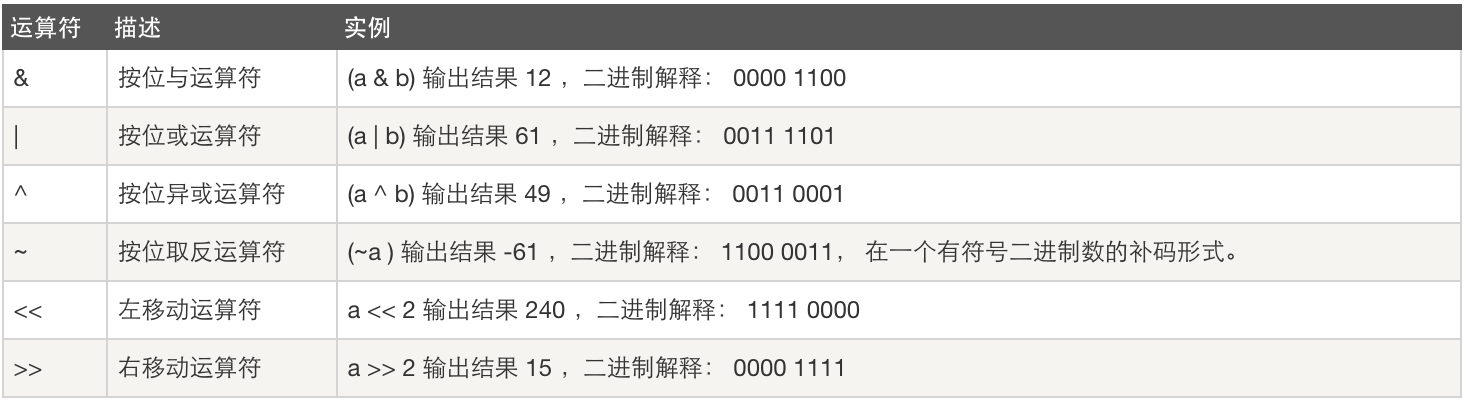
附位运算代码
#!/usr/bin/python a =60# 60 = 0011 1100 b =13# 13 = 0000 1101 c =0 c = a & b;# 12 = 0000 1100 print"Line 1 - Value of c is ", c c = a | b;# 61 = 0011 1101 print"Line 2 - Value of c is ", c c = a ^ b;# 49 = 0011 0001 print"Line 3 - Value of c is ", c c =~a;# -61 = 1100 0011 print"Line 4 - Value of c is ", c c = a <<2;# 240 = 1111 0000 print"Line 5 - Value of c is ", c c = a >>2;# 15 = 0000 1111 print"Line 6 - Value of c is ", c
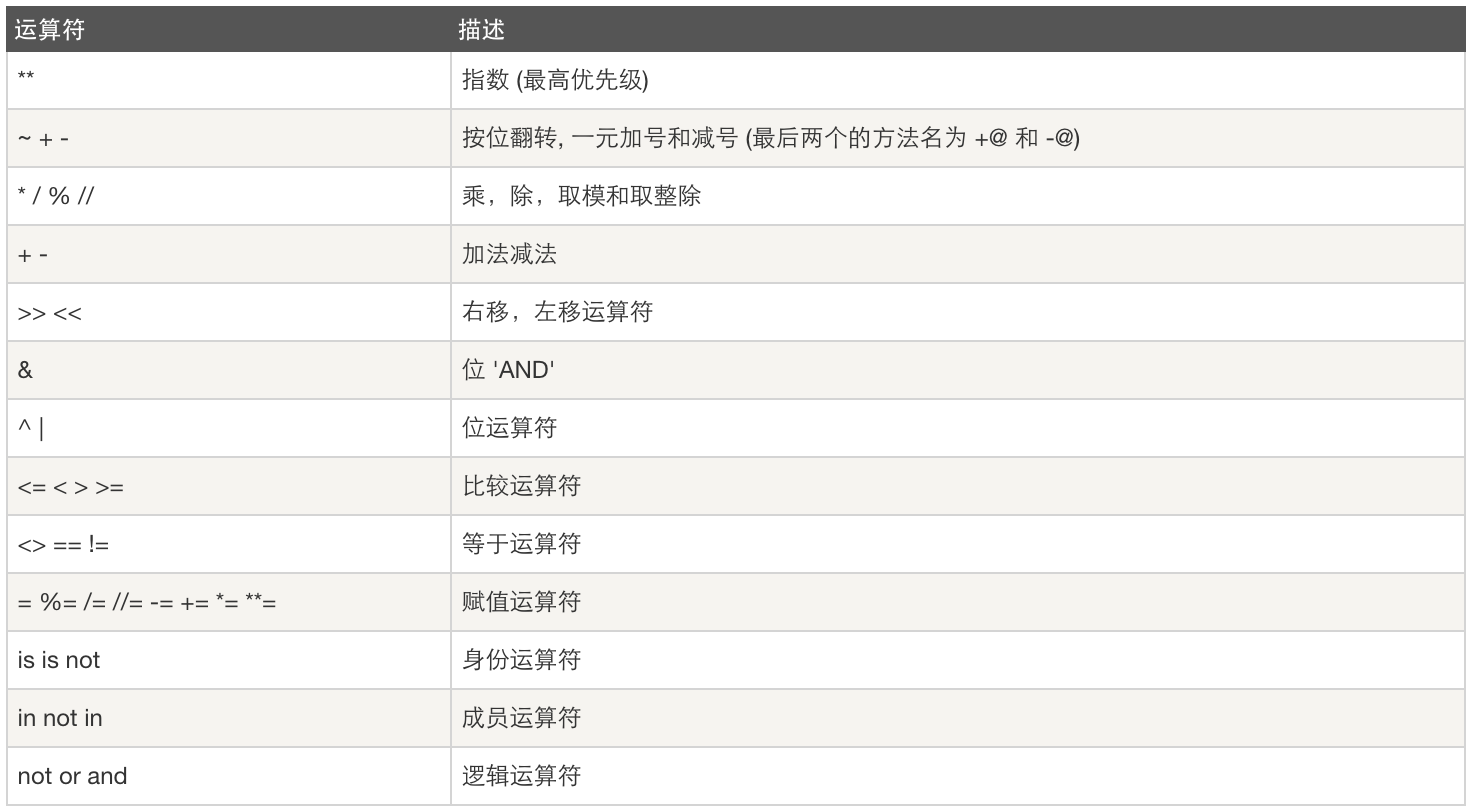
2.8运算符优先级
2.9三元运算
result =值1if条件else值2 如果条件为真:result = 值1 如果条件为假:result = 值2 a,b,c =1,2,3 d = a if a < b else c print(d) d = a if a > b else c print(d)
2.10十六进制
二进制,01 八进制,01234567 十进制,0123456789 十六进制,0123456789ABCDEF二进制到16进制转换
三、python3的bytes和str之别
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然).
3.1string转为二进制(bytes)
有些时候字符串不能处理需要转换为二进制,使用decode
print(b'\xe5\xb8\x85\xe5\x93\xa5'.decode("utf-8"))
chuck ="帅哥"
print(chuck.encode("utf-8").decode("utf-8"))
3.2bytes转为string
在python3中socket传输数据是不可以用string形式传输的,
所以必须将str转换为bytes,使用encode
chuck ="帅哥"
print(chuck.encode("utf-8"))#python3如果encode处不指定utf-8或其他编码,会使用系统默认使用utf-8,python2会默认使用系统的编码
四、列表
实际生产中,如果有需求定义很多变量,肯定不会是一个个去指定,这时候就需要列表登场了,上文也提到了列表的基本操作;下面就开始对列表进行详细的学习。
4.1 打印列表
列表使用大括号定义,每个元素使用逗号隔开
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names) ['zhangsan','lisi','wangerma','maliang','chuck']
从列表中取出zhangsan,计算机是从0开始计算顺序的,所以张三对于names列表处于第0个位置,下标即为0,方法如下:
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names[0]) zhanngsan
从列表中取出maliang
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names[3]) maliang
4.2列表的增删改查
4.2.1列表的切片
从列表中取出lisi和wangerma,切片的宗旨是顾首不顾尾,所以如果想取到wangerma的值就需要向后移一个位置,方法如下:
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names[1:3]) ['lisi','wangerma']
列表中最后一个值可以用-1指定,倒数第二个为-2,以此类推
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names[-1]) chuck
取出最后两个元素,-2后面要省略不写
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names[-2:]) ['maliang','chuck']
取出前三个元素,可以使用以下方法,冒号前面是0可以忽略
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names[:3]) ['zhangsan','lisi','wangerma']
在列表中使用步长跳着切片,从0打印到-1(0和-1可以省略),步长为2
names =["zhangsan","lisi",["zzz","xxx","yyy"],"wangerma","maliang","chuck"]
print(names[0:-1:2]) ['zhangsan',['zzz','xxx','yyy'],'maliang']
4.2.2列表元素的增加
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.append("mayun") print(names) ['zhangsan','lisi','wangerma','maliang','chuck','mayun']
使用insert加入,添加到某个元素的前面,指定该元素的下标插入,方法如下:
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.insert(2,"liuqiangdong")
print(names)
['zhangsan','lisi','liuqiangdong','wangerma','maliang','chuck']
4.2.3列表元素的修改
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names[2]="liyanhong" print(names) ['zhangsan','lisi','liyanhong','maliang','chuck']
4.2.4列表元素的删除
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.remove("lisi") print(names)
使用del方法
names =["zhangsan","lisi","wangerma","maliang","chuck"]
del names[1] print(names) ['zhangsan','wangerma','maliang','chuck']
使用pop方法删除,此方法默认会删除最后一个元素,也可以指定下标删除
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.pop(2) print(names) ['zhangsan','lisi','maliang','chuck']
4.3列表的索引index
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names.index("wangerma")) 2
再将wangerma从索引结果中取出来
names =["zhangsan","lisi","wangerma","maliang","chuck"]
print(names.index("wangerma")) print(names[names.index("wangerma")]) 2 wangerma
4.4统计列表中某个元素的数量
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.insert(3,"zhangsan") names.insert(3,"zhangsan") print(names.count("zhangsan")) 3
4.5clear清空列表
4.6reverse反转列表
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.reverse() print(names) ['chuck','maliang','wangerma','lisi','zhangsan']
4.7使用sort排序
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names.insert(1,"Liudehua") names.insert(3,"23fdsd") names.insert(4,"!^ksdk") names.sort() print(names) ['!^ksdk','23fdsd','Liudehua','chuck','lisi','maliang','wangerma','zhangsan']
4.8使用extend连接两个列表
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names2 =["www","jjj","lll"] names.extend(names2) del names2 print(names) ['zhangsan','lisi','wangerma','maliang','chuck','www','jjj','lll']
4.9使用copy复制一个列表
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names3 = names.copy() print(names) print(names3) ['zhangsan','lisi','wangerma','maliang','chuck'] ['zhangsan','lisi','wangerma','maliang','chuck']
更改names中一个元素,打印names和name3,可以看到names列表变化了,但是names3并没有变化,我们称之为浅copy
names =["zhangsan","lisi","wangerma","maliang","chuck"]
names3 = names.copy() names[2]="hehe" print(names) print(names3) ['zhangsan','lisi','hehe','maliang','chuck'] ['zhangsan','lisi','wangerma','maliang','chuck']
在names列表中加入一个列表,并更改加入列表的元素的内容,再使用copy出一个names3列表,从下面结果可以看出copy只是copy了最外面一层的元素(wagnerma),对列表中列表里的元素不再做copy,所以称之为浅copy。因为列表中的列表属于第二层元素,指向的是固定的一个内存地址,所以只要通过一个列表改动列表中列表的元素,其他的列表也都会改变
names =["zhangsan","lisi",["zzz","xxx","yyy"],"wangerma","maliang","chuck"]
names3 = names.copy() names[3]="hehe" names[2][2]="ttt" print(names) print(names3) ['zhangsan','lisi',['zzz','xxx','ttt'],'hehe','maliang','chuck'] ['zhangsan','lisi',['zzz','xxx','ttt'],'wangerma','maliang','chuck']
如果想对一个列表进行完全的copy,就是所有的内容都不改变,那就要使用深copy,即deecopy,使用deecopy要导入copy模块,从结果中可以看出无论后面names的元素怎么更改,names3都保持了原有的元素内容
import copy
names =["zhangsan","lisi",["zzz","xxx","yyy"],"wangerma","maliang","chuck"] names3 = copy.deepcopy(names) names[3]="hehe" names[2][2]="ttt" print(names) print(names3) ['zhangsan','lisi',['zzz','xxx','ttt'],'hehe','maliang','chuck'] ['zhangsan','lisi',['zzz','xxx','yyy'],'wangerma','maliang','chuck']
4.8在列表中使用for循环
names =["zhangsan","lisi",["zzz","xxx","yyy"],"wangerma","maliang","chuck"]
for i in names: print(i) zhangsan lisi ['zzz','xxx','yyy'] wangerma maliang chuck
五、元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表;元组中适合存一些不可更改的值,例如存放数据库配置连接内容;元组只有两个方法使用,count和index,原理同列表;使用方法如下
names =("alex","jack","eric")
六、字典
字典是一种key-value的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
6.1字典的特性
- 字典是无序的
- key必须是唯一的
- 语法:
info ={
'stu1101':"TengLan Wu",
'stu1102':"LongZe Luola",
'stu1103':"XiaoZe Maliya",
}
6.2字典的取值
- 方法1:通过key直接取值,值存在不报错,值不存在就报错
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
print(info["stu1101"])
zhangsan
- 方法2:取值时建议使用get方法,如果想取到的key不存在也不会报错,会返回None
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
print(info.get("stu1101"))
print(info.get("stu1105"))
zhangsan
None
6.3字典内容的增加
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
print(info)
info["stu1104"]="chuck"
print(info)
{'stu1103':'wangerma','stu1102':'lisi','stu1101':'zhangsan'}
{'stu1103':'wangerma','stu1104':'chuck','stu1102':'lisi','stu1101':'zhangsan'}
6.4字典内容的删除
- 方法1:del指定key
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
del info['stu1101']
print(info)
{'stu1103':'wangerma','stu1102':'lisi'}
- 方法2:pop指定key
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
info.pop("stu1102")
print(info)
{'stu1103':'wangerma','stu1101':'zhangsan'}
- 方法3:popitem,由于字典是无顺序的,所以会随机删除一个,不建议使用
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
info.popitem()
print(info)
{'stu1103':'wangerma','stu1102':'lisi'}
6.5判断一个key是否在字典里
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
print("stu1103"in info)#此方法等同于python2里面的has_key
print("stu1105"in info)
True#存在返回True
False#不存在返回False
6.6多级字典嵌套
av_catalog ={
"欧美":{
"www.youporn.com":["很多免费的,世界最大的","质量一般"],
"www.pornhub.com":["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com":["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
- 将大陆的”服务器在国外”改为”在国内做镜像,慢”,一层层改即可,字典字典列表
av_catalog["大陆"][""][1]="可以在国内做镜像"
6.7打印所有value的值
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
print(info.values())
dict_values(['zhangsan','wangerma','lisi'])
6.8使用setdefault在没有此key时创建新的,有此key时不变化
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
info.setdefault("stu1101","ZHANGSAN")
print(info)
info.setdefault("stu1104","ZHANGSAN")
print(info)
{'stu1102':'lisi','stu1101':'zhangsan','stu1103':'wangerma'}
{'stu1102':'lisi','stu1104':'ZHANGSAN','stu1101':'zhangsan','stu1103':'wangerma'}
6.9使用update合并更新key
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
info2 ={
"stu1102":"chuck",
"stu1104":"mario",
"stu1105":"shuaige"
}
info.update(info2)
print(info)
{'stu1103':'wangerma','stu1101':'zhangsan','stu1102':'chuck','stu1105':'shuaige','stu1104':'mario'}
6.10使用item将字典转为列表
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
print(info.items())
dict_items([('stu1101','zhangsan'),('stu1102','lisi'),('stu1103','wangerma')])
6.11使用fromkeys创建一个初始化的的字典,创建一层字典的时候没影响,创建多层初始化字典的时候会有影响
temp_dict = dict.fromkeys(["no1","no2","no3"],"test")
print(temp_dict) {'no1':'test','no3':'test','no2':'test'}
6.12使用for循环打印字典内容
- 方法1:此方法高效很多,通过key取出value
info ={
'stu1101':"zhangsan",
'stu1102':"lisi",
'stu1103':"wangerma",
}
for i in info:
print(i,info[i])
stu1102 lisi
stu1103 wangerma
stu1101 zhangsan
- 方法2:此方法会多次循环,当key很多的时候,效率很低,不建议使用
for k,v in info.items():
print(k,v) stu1103 wangerma stu1102 lisi stu1101 zhangsan
七、字符串方法
- 使用capitalize使字符串首字母大写
strings ="chuck"
print(strings.capitalize()) Chuck
- 使用count统计字母个数
strings ="chuck"
print(strings.count("c")) 2
- 使用center来补充空缺,并把str置于中间
strings ="chuck"
print(strings.center(50,"-")) ----------------------chuck-----------------------
- 使用endswith判断字符串以什么结尾,可以用判断邮件地址
strings ="chuck"
print(strings.endswith("k"))
- 使用expandtabs将tab键转换成多少个空格
name ="\t chuck"
print(name.expandtabs(tabsize=30)) chuck
- 使用find查找字符串的字符索引,并切片
name =" my name is chuck"
print(name.find("is"))
切片
name =" my name is chuck"
print(name[name.find("is"):15]) is chu
- 使用rfind找到最后边值的下标,忘记他吧
- 使用format格式化输出
name =" my name is {name}"
print(name.format(name="chuck"))
my name is chuck
- 使用formt_map格式化输出,以字典传输进去
name =" my name is {name}"
print(name.format_map({'name':"chuck"}))
my name is chuck
- 使用isalnum判断字符串是否不含有特殊字符却含有数字为True,不包含数字或者含有特殊字符为False
name ="ab123"
print(name.isalnum()) name2 ="abc123#r" print(name2.isalnum()) True False
- 使用isalpha判断字符串是否只包含字母,包括大写
name ="ab123"
print(name.isalpha()) name2 ="abKDFdef" print(name2.isalpha()) False True
- 使用isdecimal判断字符串是否为十进制
name =""
print(name.isdecimal()) name2 ="ad23" print(name2.isdecimal()) True False
- 使用isdigit判断一个字符串是否为整数
name =""
print(name.isdigit()) name2 ="111.111" print(name2.isdigit()) True False
- 使用isidentifier判断字符串是否为合法的标识符,也就是是否为合法的变量名
name ="aaaa77777"
print(name.isidentifier()) name2 ="" print(name2.isidentifier()) True False
- 使用isnumeric判断字符串是否为一个数字,很少用
name ="aaaa77777"
print(name.isnumeric()) name2 ="" print(name2.isnumeric()) False True
- 使用isspace判断字符串是否是一个空格
name =" "
print(name.isspace()) name2 ="" print(name2.isspace()) True False
- 使用istitle判断首字母是否为大写,后面不能是大写
name ="Adjaskdja3234"
print(name.istitle()) name2 ="asdasd1232AADSS" print(name2.istitle() True False
- 使用isprintable判断是否为可打印
- 使用isupper判断字符串是否为大写
name ="Adjaskdja3234"
print(name.isupper()) name2 ="LSAKDLASKDA" print(name2.isupper()) Fale True
- 使用join将列表内容转换成字符串
string ="+"
print(string.join(["","",""])) 1+2+3
- 使用ljust在右边补齐
name ="chuck"
print(name.ljust(20,"-")) chuck---------------
- 使用rjust在左边补齐
name ="chuck"
print(name.rjust(20,"-")) ---------------chuck
- 使用lower将大写变成小写
name ="CHUCK"
print(name.lower()) chuck
- 使用upper将小写转换为大写
name ="chuck"
print(name.lower()) CHUCK
- 使用lstrip从左边去掉空格或者回车
name ="\nchuck\n"
print("####") print(name.lstrip()) print("####") #### chuck #左侧回车已去除 此处为空行#此处应为空行,markdown不支持空行 ####
- 使用rstrip从右边去掉空格或者回车
name ="\nchuck\n"
print("####") print(name.rstrip()) print("####") #### 此处为空行#此处应为空行,markdown不支持空行 chuck #右侧回车已去除 ####
- 使用strip去掉左右侧空格
name ="\nchuck\n"
print("####") print(name.rstrip()) print("####") #### #左侧回车已去除 chuck #右侧回车已去除 ####
- 使用maketrans将字符串转换成对应的值,结合translate翻译,忘记他吧
p = str.maketrans("asdfg","")
print("sdadskjdsdkfjasasdasdasd".translate(p))
98089kj898k7j09098098098
- 使用replace替换字符串或者字母,若后面指定数字,表示替换几次,从前到后
name ="chuck is chuck Ma"
print(name.replace("c","C",2)) ChuCkis chuck Ma
- 使用split将字符串转换成列表,默认为空格,可以指定分隔符
name ="chuck is chuck Ma"
print(name.split()) ['chuck','is','chuck','Ma']
- 使用splitlines按照换行符(\n)来分割,等同于split(”\n”)
- 使用swapcase将大小写全部转换
name ="chuck Ma"
print(name.swapcase()) CHUCK mA
- 使用title将每个字符的首字母变为大写
name ="chuck ma"
print(name.title())
- 使用zfill在左侧用0补充
name ="chuck ma"
print(name.zfill(20))
八 集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
- 无序的排列
8.1列表转为集合
list =[1,2,3,4,5,6,6,6,6]
list =set(list) print(list,type(list)) {1,2,3,4,5,6}<class'set'>
8.2交集
8.2.1使用intersection求两个集合的交集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1.intersection(jihe2))
{1,4,5}
8.2.2使用运算符&求交集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1&jihe2)
{1,4,5}
8.2.3使用isdisjoint判断是否有交集,有交集为False
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
jihe3 ={7,8,9}
print(jihe1.isdisjoint(jihe2))
print(jihe1.isdisjoint(jihe3))
False
True
8.3并集
8.3.1使用union求两个集合的并集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1.union(jihe2))
{1,2,3,4,5,6,22,23,31}
8.3.2使用运算符|求并集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1|jihe2)
{1,2,3,4,5,6,22,23,31}
8.4差集
8.4.1使用difference求集合1集合2中没有的差集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1.difference(jihe2))
{2,3,6}
8.4.2使用运算符-求差集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe-jihe2)
{2,3,6}
8.5子集
8.5.1使用issubset判断是否为子集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
jihe3 ={1,2,3,6}
print(jihe2.issubset(jihe1))
print(jihe3.issubset(jihe1))
False
True
8.6父集
8.6.1使用issuperset判断是否为父集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
jihe3 ={1,2,3,6}
print(jihe1.issuperset(jihe2))
print(jihe1.issuperset(jihe3))
False
True
8.7对称差集
8.7.1使用symmetric_difference求对称差集(两个集合的并集减去子集剩下的部分)
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1.symmetric_difference(jihe2))
{2,3,22,23,6,31}
8.7.2使用运算符^求差集
jihe1 ={1,2,3,4,5,6}
jihe2 ={23,4,31,5,22,1}
print(jihe1^jihe2)
{2,3,22,23,6,31}
8.8在集合中添加元素
jihe1 ={1,2,3,4,5,6}
jihe1.add(7)
print(jihe1)
{1,2,3,4,5,6,7}
8.9在集合中添加多个元素
jihe1 ={1,2,3,4,5,6}
jihe1.update([2,222])
print(jihe1)
{1,2,3,4,5,6,222}
8.10在集合删除一个元素
jihe1 ={1,2,3,4,5,6}
jihe1.remove(2)
print(jihe1)
{1,3,4,5,6}
8.11判断元素是否为集合的成员
jihe1 ={1,2,3,4,5,6}
print(1in jihe1,"-------",8in jihe1)
True-------False
jihe1 ={1,2,3,4,5,6}
print(1notin jihe1,"-------",8notin jihe1)
False-------True
8.12删除一个任意的元素
jihe1 ={1,2,3,4,5,6}
print(jihe1)
{2,3,4,5,6}
8.13删除一个指定的元素,如果该元素不存在会报错
jihe1 ={1,2,3,4,5,6}
jihe1.remove(3)
print(jihe1)
{1,2,4,5,6}
8.14删除一个指定的元素,如果该元素不存在不报错
jihe1 ={1,2,3,4,5,6}
jihe1.discard(7)
jihe1.discard(2)
print(jihe1)
{1,3,4,5,6}
Day2 基本数据类型的更多相关文章
- Day2基本数据类型 字节 和类型转换
Java基础语法 注释 1.单行注释:// 加内容 2.多行注释:/* 多行注释 */ 3.文档注释: /** * * */ 有趣的注释 标识符 关键字 基本数据类型 八大基本数据类型 //整数in ...
- Day2:数据类型
一.数字 1.整型(int),无长整型.python3.x,不论多大的数都是int #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Hiuh ...
- python2.0 s12 day2
s12 day2 视频每节的内容 05 python s12 day2 python编码 1.第一句python代码 python 执行代码的过程 文件读到内存 分析内容 编译字节码 转换机器码 ...
- 跟着ALEX 学python day2 基础2 模块 数据类型 运算符 列表 元组 字典 字符串的常用操作
声明 : 文档内容学习于 http://www.cnblogs.com/xiaozhiqi/ 模块初始: Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相 ...
- python day2:python的基本数据类型及其方法
目录 python day2 1. 编码转换 2. python的基本数据类型 3. for 迭代遍历 4. 列表list 5. 元组tuple 6. 字典dict 7. 枚举enumerate 8. ...
- day2. 六大基本数据类型简介
一.基本数据类型 Number 数字类型 (int float bool complex) str 字符串类型 list 列表类型 tuple 元组类型 set 集合类型 dict 字典类型 二.Nu ...
- Python day2 基础 2 数据类型
数据类型初识 1.数字 2 是一个整数的例子.长整数 不过是大一些的整数.3.23和52.3E-4是浮点数的例子.E标记表示10的幂.在这里,52.3E-4表示52.3 * 10-4.(-5+4j)和 ...
- day2(基础数据类型)
一.基础数据类型操作 1.数字 int 数字主要是用于计算用的,使用方法并不是很多,就记住一种就可以: int.bit_length() -> int Number of bits necess ...
- Day2 数据类型和运算符
基本数据类型 Java 是一种强类型的语言,声明变量时必须指明数据类型.变量(variable)的值占据一定的内存空间.不同类型的变量占据不同的大小.Java中共有8种基本数据类型,包括4 种整型.2 ...
随机推荐
- go web 第一天 学习笔记
package main import ( "fmt" "log" "net/http" "strings" ) fun ...
- Python | 多种编码文件(中文)乱码问题解决
问题线索 1 可以知道的是,文本文件的默认编码并不是utf8. 我们打开一个文本文件,并点击另存为 2 我们在新窗口的编码一栏看到默认编码是ANSI.先不管这个编码是什么编码,但是通过下拉列表我们 ...
- hibernate日志信息
hibernate3使用集成log4j的配置以及实现 hibernate3 自带的默认的日志框架是slf4j,hibernate3的slf只是一个日志的接口,而hibernate3 自带默认的日志 ...
- LeetCode Weekly Contest 47
闲着无聊参加了这个比赛,我刚加入战场的时候时间已经过了三分多钟,这个时候已经有20多个大佬做出了4分题,我一脸懵逼地打开第一道题 665. Non-decreasing Array My Submis ...
- javaSE基础之 LinkedList的底层简单实现
这里贴上LinkedList底层的简单实现 package com.yck.mylinkedlist; public class Node { private Node previous; //上一结 ...
- Python+Requests接口测试教程(2):
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/ 2.1 发get请求 前言requests模块,也就是老污龟 ...
- 利用jmeter+JAVA对RPC的单接口(dubbo接口等)进行性能测试
建立JAVA项目 建立maven项目,加入Jmeter所需要的JAR包依赖. POM.xml 加入如下: <dependency> <groupId>org.apache.j ...
- 锋利的jQuery幻灯片实例
//锋利的jQuery幻灯片实例 <!DOCTYPE html> <html lang="en"> <head> <meta charse ...
- pycharm激活
刚刚下载了2017.1版本专业版的pycharm,作为一个天朝开发者,自然是去找注册码了.转悠了一圈,那些注册码都已经失效了.看到一个有效的方法:把http://elporfirio.com:1017 ...
- MongoDB基本shell操作
---------------------MongoDB基本操作--------------------- 1.MongoDB创建数据库 use 数据库名:切换到指定的数据库中,在插入第一个条 ...