搭建ubuntu版hadoop集群
用到的工具:VMware、hadoop-2.7.2.tar、jdk-8u65-linux-x64.tar、ubuntu-16.04-desktop-amd64.iso
1、 在VMware上安装ubuntu-16.04-desktop-amd64.iso
单击“创建虚拟机”è选择“典型(推荐安装)”è单击“下一步”




è点击完成
修改/etc/hostname
vim hostname
保存退出

修改etc/hosts
127.0.0.1 localhost
192.168.1.100 s100
192.168.1.101 s101
192.168.1.102 s102
192.168.1.103 s103
192.168.1.104 s104
192.168.1.105 s105
配置NAT网络
查看window10下的ip地址及网关

配置/etc/network/interfaces
#interfaces() file used by ifup() and ifdown()
#The loopback network interface
auto lo
iface lo inet loopback #iface eth0 inet static
iface eth0 inet static
address 192.168.1.105
netmask 255.255.255.0
gateway 192.168.1.2
dns-nameservers 192.168.1.2
auto eth0
也可以通过图形化界面配置

配置好后执行ping www.baidu.com看网络是不是已经起作用
当网络通了之后,要想客户机宿主机之前进行Ping通,只需要做以下配置
修改宿主机c:\windows\system32\drivers\etc\hosts文件
文件内容
127.0.0.1 localhost
192.168.1.100 s100
192.168.1.101 s101
192.168.1.102 s102
192.168.1.103 s103
192.168.1.104 s104
192.168.1.105 s105
安装ubuntu 163 14.04 源
$>cd /etc/apt/
$>gedit sources.list
切记在配置之前做好备份
deb http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
更新
$>apt-get update
在家根目录下新建soft文件夹 mkdir soft
但是建立完成后,该文件属于root用户,修改权限 chown enmoedu:enmoedu soft/
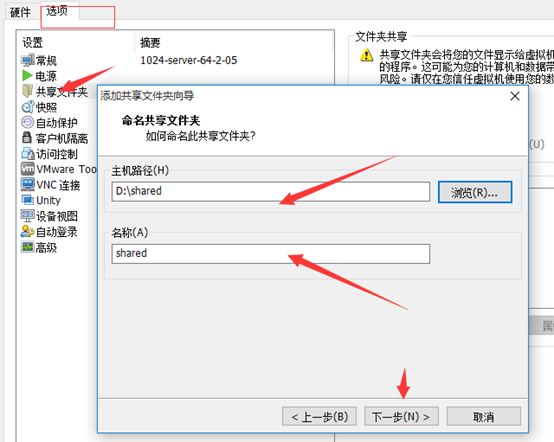
安装共享文件夹

将该文件放到桌面,右键,点击“Extract here”

切换到enmoedu用户的家目录,cd /Desktop/vmware-tools-distrib

执行./vmware-install.pl文件
Enter键执行
安装完成
拷贝hadoop-2.7.2.tar、jdk-8u65-linux-x64.tar到enmoedu家目录下的/Downloads
$> sudo cp hadoop-2.7.2.tar.gz jdk-8u65-linux-x64.tar.gz ~/Downloads/
分别解压hadoop-2.7.2.tar、jdk-8u65-linux-x64.tar到当前目录
$> tar -zxvf hadoop-2.7.2.tar.gz
$>tar -zxvf jdk-8u65-linux-x64.tar.gz
$>cp -r hadoop-2.7.2 /soft
$>cp -r jdk1.8.0_65/ /soft
建立链接文件
$>ln -s hadoop-2.7.2/ hadoop
$>ln -s jdk1.8.0_65/ jdk
$>ls -ll

配置环境变量
$>vim /etc/environment
JAVA_HOME=/soft/jdk
HADOOP_HOME=/soft/hadoop
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/soft/jdk/bin:/soft/hadoop/bin:/soft/hadoop/sbin"
让环境变量生效
$>source environment
检验安装是否成功
$>java –version

$>hadoop version
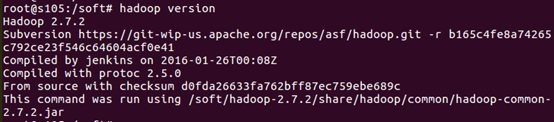
配置/soft/hadoop/etc/hadoop/ 下的配置文件
[core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s100/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/enmoedu/hadoop</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s104:</value>
<description>
The secondary namenode http server address and port.
</description>
</property>
</configuration>
[mapred-site.xml]
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[yarn-site.xml]
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s100</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置ssh无密码登录
安装ssh
$>sudo apt-get install ssh
生成秘钥对
在enmoedu家目录下执行
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
导入公钥数据到授权库中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

测试localhost成功后,将master节点上的供钥拷贝到授权库中
其中root一样执行即可
$>ssh localhost

从master节点上测试是否成功。

修改slaves文件
[/soft/hadoop/etc/hadoop/slaves]
s101
s102
s103
s105
其余机器,通过克隆,修改hostname和网络配置即可
塔建完成后
格式化hdfs文件系统
$>hadoop namenode –format
启动所有进程
start-all.sh
最终结果:

自定义脚本xsync(在集群中分发文件)
[/usr/local/bin]
循环复制文件到所有节点的相同目录下。
[usr/local/bin/xsync]
#!/bin/bash
pcount=$#
if (( pcount< ));then
echo no args;
exit;
fi
p1=$;
fname=`basename $p1`
#echo $fname=$fname; pdir=`cd -P $(dirname $p1) ; pwd`
#echo pdir=$pdir cuser=`whoami`
for (( host=;host<;host=host+ )); do
echo ------------s$host----------------
rsync -rvl $pdir/$fname $cuser@s$host:$pdir
done
测试
xsync hello.txt


自定义脚本xcall(在所有主机上执行相同的命令)
[usr/local/bin]
#!/bin/bash
pcount=$#
if (( pcount< ));then
echo no args;
exit;
fi
echo -----------localhost----------------
$@
for (( host=;host<;host=host+ )); do
echo ------------s$host-------------
ssh s$host $@ done
测试 xcall rm –rf hello.txt


集群搭建完成后,测试次运行以下命令
touch a.txt
gedit a.txt
hadoop fs -mkdir -p /user/enmoedu/data
hadoop fs -put a.txt /user/enmoedu/data
hadoop fs -lsr /

也可以进入浏览器查看


搭建ubuntu版hadoop集群的更多相关文章
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- Hadoop4 利用VMware搭建自己的hadoop集群
前言: 前段时间自己学习如何部署伪分布式模式的hadoop环境,之前由于工作比较忙,学习的进度停滞了一段时间,所以今天抽出时间把最近学习的成果和大家分享一下. 本文要介绍的是如 ...
- 在 Linux 服务器上搭建和配置 Hadoop 集群
实验条件:3台centos服务器,jdk版本1.8.0,Hadoop 版本2.8.0 注:hadoop安装和搭建过程中都是在用户lb的home目录下,master的主机名为host98,slave的主 ...
- 搭建简单的hadoop集群(译文)
本文翻译翻译自http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/ClusterSetup.html 具体的实 ...
- Ubuntu下hadoop集群搭建
--修改IP地址(克隆镜像后可修改可不修改) http://jingyan.baidu.com/article/e5c39bf5bbe0e739d7603396.html -------------- ...
- 大数据系列(1)——Hadoop集群坏境搭建配置
前言 关于时下最热的技术潮流,无疑大数据是首当其中最热的一个技术点,关于大数据的概念和方法论铺天盖地的到处宣扬,但其实很多公司或者技术人员也不能详细的讲解其真正的含义或者就没找到能被落地实施的可行性方 ...
- 沉淀,再出发——手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群
手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群 一.准备,再出发 在项目启动之前,让我们看一下前面所做的工作.首先我们掌握了一些Linux的基本命令和重要的文件,其次我们学会 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- [转]大数据hadoop集群硬件选择
问题导读 1.哪些情况会遇到io受限制? 2.哪些情况会遇到cpu受限制? 3.如何选择机器配置类型? 4.为数据节点/任务追踪器提供的推荐哪些规格? 随着Apache Hadoop的起步,云客户 ...
随机推荐
- linux中的软连接和硬连接
1. 创建软连接的方法 ln -s /path/to/original /path/to/linkName 当我们对软连接文件进行修改后,对应的修改也会反映到原始的文件(反之亦然). 当我们删除软连接 ...
- Unity渲染优化中文翻译(一)——定位渲染问题
最近有一点个人的时间,尝试一下自己翻译一下英文的 Optimizing graphics rendering in Unity Games, 这儿附上英文链接: 个人英文水平有限,unity图像学知识 ...
- BZOJ 3410: [Usaco2009 Dec]Selfish Grazing 自私的食草者(贪心)
这= =,就是线段覆盖对了= =直接贪心就行了= = CODE: #include<cstdio>#include<iostream>#include<cstring&g ...
- AWT与Swing的区别
AWT 是Abstract Window ToolKit (抽象窗口工具包)的缩写,这个工具包提供了一套与本地图形界面进行交互的接口.AWT 中的图形函数与操作系统所提供的图形函数之间有着一一对应的关 ...
- Android 反射-换一种方式编程
Android 反射-换一种方式编程 转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/59109933 本文出自[赵彦军的博客] 上一 ...
- sql server数据库备份压缩拷贝实例
--数据库备份压缩拷贝实例:前提要安装RAR压缩软件--声明变量declare @day varchar(10),@dbname varchar(20),@filename varchar(100), ...
- Struts2之访问路径
上一篇已经和大家分享了关于Struts2命名空间和Action的三种创建方式,本篇我们接着命名空间的内容,来一起探讨一下关于Struts2的访问路径问题,何为访问路径,就是指当我们在浏览器输入地址,点 ...
- 更改Debian Linux里面的EDT时区为CST时区
Debian按默认安装,设置的是EDT时区.这样跟我们的系统就都对不上,因此得 改回CST. 只需要两步即可: 使用vi编辑/etc/timezone,把timezone文件的内容更改为:Asia/S ...
- 1441: Min
1441: Min Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 320 Solved: 213[Submit][Status][Discuss] De ...
- C 风格字符串相加
<<C++ Primer>> 第四版Exercise Section 4.3.1 的4.3.0 有如下题目:编写程序连接两个C风格字符串字面值,把结果存储在C风格字符串中.代码 ...