基本数据结构——堆(Heap)的基本概念及其操作
基本数据结构――堆的基本概念及其操作
小广告:福建安溪一中在线评测系统 Online Judge
在我刚听到堆这个名词的时候,我认为它是一堆东西的集合...
但其实吧它是利用完全二叉树的结构来维护一组数据,然后进行相关操作,一般的操作进行一次的时间复杂度在
O(1)~O(logn)之间。
可谓是相当的引领时尚潮流啊(我不信学信息学的你看到log和1的时间复杂度不会激动一下下)!。
什么是完全二叉树呢?别急着去百度啊,要百度我帮你百度:
若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中
在最左边,这就是完全二叉树。我们知道二叉树可以用数组模拟,堆自然也可以。
现在让我们来画一棵完全二叉树:
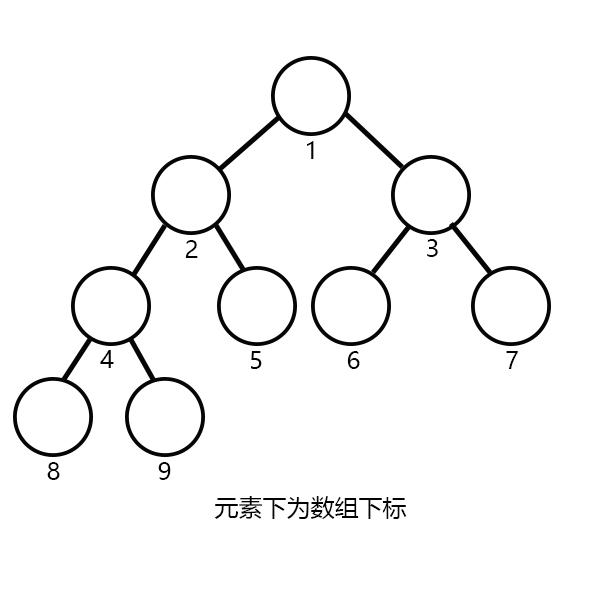
从图中可以看出,元素的父亲节点数组下标是本身的1/2(只取整数部分),所以我们很容易去模拟,也很
容易证明其所有操作都为log级别~~
堆还分为两种类型:大根堆、小根堆
顾名思义,就是保证根节点是所有数据中最大/小,并且尽力让小的节点在上方
不过有一点需要注意:堆内的元素并不一定数组下标顺序来排序的!!很多的初学者会错误的认为大/小根堆中
下标为1就是第一大/小,2是第二大/小……
原因会在后面解释,现在你只需要深深地记住这一点!
我们刚刚画的完全二叉树中并没有任何元素,现在让我们加入一组数据吧!
下标从1到9分别加入:{8,5,2,10,3,7,1,4,6}。
如下图所示
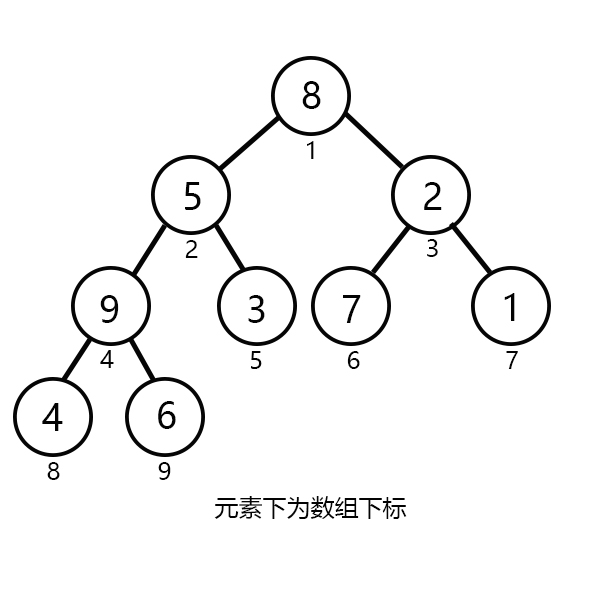
(不要问我怎么加,想想你是怎么读入数组的。)
我们可以发现这组数据是杂乱无章的,我们该如何去维护呢?
现在我就来介绍一下堆的几个基本操作:
- 上浮 shift_up;
- 下沉 shift_down
- 插入 push
- 弹出 pop
- 取顶 top
- 堆排序 heap_sort
学习C/C++的同学有福利了,堆的代码一般十分之长,而我们伟大的STL模板库给我们提供了两种简单方便堆操作的方式,
想学习的可以看看这个:http://www.cnblogs.com/helloworld-c/p/4854463.html 密码: abcd111
我个人建议吧,起码知道一下实现的过程,STL只能是锦上添花,绝不可以雪中送炭!!
万一哪天要你模拟堆的某一操作过程,而你只知道STL却不知道原理,看不出这个题目是堆,事后和其他OIer
讨论出题解,那岂不是砍舌头吃苦瓜,哭得笑哈哈。
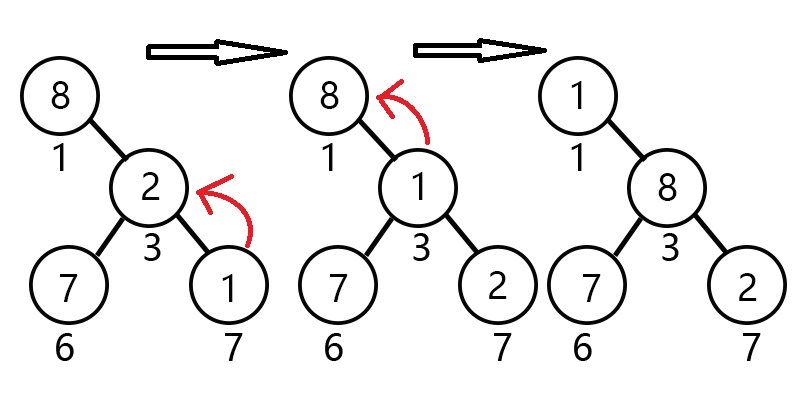
那么我们开始讲解操作过程吧,我们以小根堆为例
刚刚那组未处理过的数据中我们很容易就能看出,根节点1元素8绝对不是最小的
我们很容易发现它的一个儿子节点3(元素2)比它来的小,我们怎么将它放到最高点呢?很简单,直接交换嘛~~
但是,我们又发现了,3的一个儿子节点7(元素1)似乎更适合在根节点。
这时候我们是无法直接和根节点交换的,那我们就需要一个操作来实现这个交换过程,那就是上浮 shift_up。
操作过程如下:
从当前结点开始,和它的父亲节点比较,若是比父亲节点来的小,就交换,
然后将当前询问的节点下标更新为原父亲节点下标;否则退出。
模拟操作图示:
伪代码如下:
Shift_up( i )
{
while( i / >= )
{
if( 堆数组名[ i ] < 堆数组名[ i/ ] )
{
swap( 堆数组名[ i ] , 堆数组名[ i/ ]) ;
i = i / ;
}
else break;
}
这一次上浮完毕之后呢,我们又发现了一个问题,貌似节点3(元素8)不太合适放在那,而它的子节点7(元素2)
好像才应该在那个位置。
此时的你应该会说:“赐予我力量,让节点7上浮吧,我是OIer!”
然而,上帝(我很不要脸的说是我)赐予你另外一种力量,让节点3下沉!
那么问题来了:节点3应该往哪下沉呢?
我们知道,小根堆是尽力要让小的元素在较上方的节点,而下沉与上浮一样要以交换来不断操作,所以我们应该
让节点7与其交换。
由此我们可以得出下沉的算法了:
让当前结点的左右儿子(如果有的话)作比较,哪个比较小就和它交换,
并更新询问节点的下标为被交换的儿子节点下标,否则退出。
模拟操作图示:
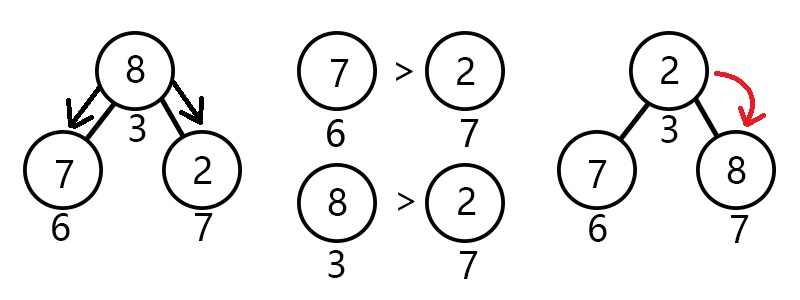
伪代码如下:
Shift_down( i , n ) //n表示当前有n个节点
{
while( i * <= n)
{
T = i * ;
if( T + <= n && 堆数组名[ T + ] < 堆数组名[ T ])
T++;
if( 堆数组名[ i ] < 堆数组名[ T ] )
{
swap( 堆数组名[ i ] , 堆数组名[ T ] );
i = T;
}
else break;
}
讲完了上浮和下沉,接下来就是插入操作了~~~~
我们前面用的插入是直接插入,所以数据才会杂乱无章,那么我们如何在插入的时候边维护堆呢?
其实很简单,每次插入的时候呢,我们都往最后一个插入,让后使它上浮。
(这个不需要图示了吧…)
伪代码如下:
Push ( x )
{
n++;
堆数组名[ n ] = x;
Shift_up( n );
}
咳咳,说完了插入,我们总需要会弹出吧~~~~~
弹出,顾名思义就是把顶元素弹掉,但是,弹掉以后不是群龙无首吗??
我们如何去维护这堆数据呢?
稍加思考,我们不难得出一个十分巧妙的算法:
让根节点元素和尾节点进行交换,然后让现在的根元素下沉就可以了!
(这个也不需要图示吧…)
伪代码如下:
Pop ( x )
{
swap( 堆数组名[] , 堆数组名[ n ] );
n--;
Shift_down( );
}
接下来是取顶…..我想不需要说什么了吧,根节点数组下标必定是1,返回堆[ 1 ]就OK了~~
注意:每次取顶要判断堆内是否有元素,否则..你懂的
图示和伪代码省略,如果你这都不会那你可以重新开始学信息学了,当然如果你是小白….这种稍微高级的数据
结构还是以后再说吧。
说完这些,我们再来说说堆排序。之前说过堆是无法以数组下标的顺序来来排序的对吧?
所以我个人认为呢,并不存在堆排序这样的操作,即便网上有很多堆排序的算法,但是我这里有个更加方便的算法:
开一个新的数组,每次取堆顶元素放进去,然后弹掉堆顶就OK了~
伪代码如下:
Heap_sort( a[] )
{
k=;
while( size > )
{
k++;
a[ k ] = top();
pop();
}
}
堆排序的时间复杂度是O(nlogn)理论上是十分稳定的,但是对于我们来说并没有什么卵用。
我们要排序的话,直接使用快排即可,时间更快,用堆排还需要O(2*n)的空间。这也是为什么我说堆的操作
时间复杂度在O(1)~O(logn)。
讲完到这里,堆也基本介绍完了,那么它有什么用呢??
举个粒子,比如当我们每次都要取某一些元素的最小值,而取出来操作后要再放回去,重复做这样的事情。
我们若是用快排的话,最坏的情况需要O(q*n^2),而若是堆,仅需要O(q*logn),时间复杂度瞬间低了不少。
还有一种最短路算法——Dijkstra,需要用到堆来优化,这个算法我后面会找个时间介绍给大家。
最后附上我写的一份堆操作的代码(C++):
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#define maxn 100010 //这部分可以自己定义堆内存多少个元素
using namespace std;
struct Heap
{
int size,queue[maxn];
Heap() //初始化
{
size=;
for(int i=;i<maxn;i++)
queue[i]=;
}
void shift_up(int i) //上浮
{
while(i>)
{
if(queue[i]<queue[i>>])
{
int temp=queue[i];
queue[i]=queue[i>>];
queue[i>>]=temp;
}
i>>=;
}
}
void shift_down(int i) //下沉
{
while((i<<)<=size)
{
int next=i<<;
if(next<size && queue[next+]<queue[next])
next++;
if(queue[i]>queue[next])
{
int temp=queue[i];
queue[i]=queue[next];
queue[next]=temp;
i=next;
}
else return ;
}
}
void push(int x) //加入元素
{
queue[++size]=x;
shift_up(size);
}
void pop() //弹出操作
{
int temp=queue[];
queue[]=queue[size];
queue[size]=temp;
size--;
shift_down();
}
int top(){return queue[];}
bool empty(){return size;}
void heap_sort() //另一种堆排方式,由于难以证明其正确性
{ //我就没有在博客里介绍了,可以自己测试
int m=size;
for(int i=;i<=size;i++)
{
int temp=queue[m];
queue[m]=queue[i];
queue[i]=temp;
m--;
shift_down(i);
}
}
};
int main()
{
Heap Q;
int n,a,i,j,k;
cin>>n;
for(i=;i<=n;i++)
{
cin>>a;
Q.push(a); //放入堆内
} for(i=;i<=n;i++)
{
cout<<Q.top()<<" "; //输出堆顶元素
Q.pop(); //弹出堆顶元素
}
return ;
}
HEAP CODE
推荐一道堆的基本操作的题目:
CODEVS 1063 合并果子 :http://codevs.cn/problem/1063/
基本数据结构——堆(Heap)的基本概念及其操作的更多相关文章
- 数据结构 - 堆(Heap)
数据结构 - 堆(Heap) 1.堆的定义 堆的形式满足完全二叉树的定义: 若 i < ceil(n/2) ,则节点i为分支节点,否则为叶子节点 叶子节点只可能在最大的两层出现,而最大层次上的叶 ...
- 数据结构&堆&heap&priority_queue&实现
目录 什么是堆? 大根堆 小根堆 堆的操作 STL queue 什么是堆? 堆是一种数据结构,可以用来实现优先队列 大根堆 大根堆,顾名思义就是根节点最大.我们先用小根堆的建堆过程学习堆的思想. 小根 ...
- python数据结构之堆(heap)
本篇学习内容为堆的性质.python实现插入与删除操作.堆复杂度表.python内置方法生成堆. 区分堆(heap)与栈(stack):堆与二叉树有关,像一堆金字塔型泥沙:而栈像一个直立垃圾桶,一列下 ...
- 算法与数据结构基础 - 堆(Heap)和优先级队列(Priority queue)
堆基础 堆(Heap)是具有这样性质的数据结构:1/完全二叉树 2/所有节点的值大于等于(或小于等于)子节点的值: 图片来源:这里 堆可以用数组存储,插入.删除会触发节点shift_down.shif ...
- 堆heap和栈Stack(百科)
堆heap和栈Stack 在计算机领域,堆栈是一个不容忽视的概念,堆栈是两种数据结构.堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除.在单片机应用中,堆栈 ...
- iOS中的堆(heap)和栈(stack)的理解
操作系统iOS 中应用程序使用的计算机内存不是统一分配空间,运行代码使用的空间在三个不同的内存区域,分成三个段:“text segment “,“stack segment ”,“heap segme ...
- Java中堆(heap)和栈(stack)的区别
简单的说: Java把内存划分成两种:一种是栈内存,一种是堆内存. 在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配. 当在一段代码块定义一个变量时,Java就在栈中为这个变量分 ...
- iOS数据存储类型 及 堆(heap)和栈(stack)
iOS数据存储类型 及 堆(heap)和栈(stack) 一般认为在c中分为这几个存储区: 1栈 -- 由编译器自动分配释放. 2堆 -- 一般由程序员分配释放,若程序员不释放,程序结束时可能由O ...
- (转)堆heap和栈stack
一 英文名称 堆和栈是C/C++编程中经常遇到的两个基本概念.先看一下它们的英文表示: 堆――heap 栈――stack 二 从数据结构和系统两个层次理解 在具体的C/C++编程框架中,这两个概念并不 ...
随机推荐
- C#集合的应用以及和数组比较,它的好处有哪些
我们用的比较多的非泛型集合类主要有 ArrayList类 和 HashTable类.我们经常用HashTable 来存储将要写入到数据库或者返回的信息,在这之间要不断的进行类型的转化,增加了系统装箱和 ...
- 代写编程的作业、笔试题、课程设计,包括但不限于C/C++/Python
代写编程作业/笔试题/课程设计,包括但不限于C/C++/Python 先写代码再给钱,不要任何定金!价钱公道,具体见图,诚信第一! (截止2016-11-22已接12单,顺利完成!后文有成功交付的聊天 ...
- jquery ajax标准写法
$.ajax({ url:url, //地址 type:'post', //请求方式 还可以是get type不可写成Type 不让会导致数据发送不过去,使用 ...
- Lowest Common Ancestor of a Binary Tree leetcode
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree. According ...
- MySQL创建数据库与创建用户以及授权
1.create schema [数据库名称] default character set utf8 collate utf8_general_ci;--创建数据库 采用create schema和c ...
- 【HAL库每天一例】freemodbus移植
例程下载:资料包括程序.相关说明资料以及软件使用截图 百度云盘:https://pan.baidu.com/s/1slN8rIt 密码:u6m1 360云盘:https://yunpan.cn/OcP ...
- mvp架构解析
MVP现在已经是目前最火的架构,很多的框架都是以MVP为基础,甚至于Google自己都出一个MVP的开源架构.https://github.com/googlesamples/android-arch ...
- Spring Data JPA 实例查询
一.相关接口方法 在继承JpaRepository接口后,自动拥有了按"实例"进行查询的诸多方法.这些方法主要在两个接口中定义,一是QueryByExampleExecut ...
- iOS开发之UITableView及cell重用
1.UITanleview有的两种风格 一种是Plain,一种是Grouped,可以从这里设置风格: 他们样式分别如下: Plain: Grouped: 2.tableView展示数据的过程: (1) ...
- JavaScript 简介及语法语句
JS脚本语言 全称JavaScript:网页里面使用的脚本语言 非常强大的语言 基础语法 注释语法 单行注释// 多行注释/**/输出语法 ...