C++基本知识点总结(网摘)
原文出处:【Fei Guo】
1. 结构体和共同体的区别。
定义:
结构体struct:把不同类型的数据组合成一个整体,自定义类型。
共同体union:使几个不同类型的变量共同占用一段内存。
地址:
struct和union都有内存对齐,结构体的内存布局依赖于CPU、操作系统、编译器及编译时的对齐选项。
关于内存对齐,先让我们看四个重要的基本概念:
1.数据类型自身的对齐值:
对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,单位字节。
2.结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
3.指定对齐值:#pragma pack(n),n=1,2,4,8,16改变系统的对齐系数
4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
常见数据类型及其长度:
注意long int和int一样是4byte,long double和double一样是8byte。
在标准c++中,int的定义长度要依靠你的机器的字长,也就是说,如果你的机器是32位的,int的长度为32位,如果你的机器是64位的,那么int的标准长度就是64位。
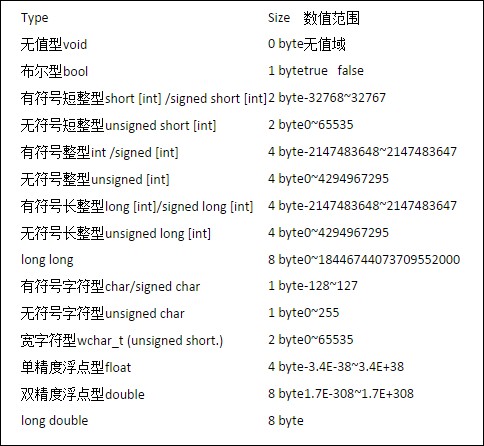
从上面的一段文字中,我们可以看出,首先根据结构体内部成员的自身对齐值得到结构体的自身对齐值(内部成员最大的长度),如果没有修改系统设定的默认补齐长度4的话,取较小的进行内存补齐。
结构体struct:不同之处,stuct里每个成员都有自己独立的地址。sizeof(struct)是内存对齐后所有成员长度的加和。
共同体union:当共同体中存入新的数据后,原有的成员就失去了作用,新的数据被写到union的地址中。sizeof(union)是最长的数据成员的长度。
总结: struct和union都是由多个不同的数据类型成员组成, 但在任何同一时刻, union中只存放了一个被选中的成员, 而struct的所有成员都存在。在struct中,各成员都占有自己的内存空间,它们是同时存在的。一个struct变量的总长度等于所有成员长度之和。在Union中,所有成员不能同时占用它的内存空间,它们不能同时存在。Union变量的长度等于最长的成员的长度。对于union的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于struct的不同成员赋值是互不影响的。
2.static 和const分别怎么用,类里面static和const可以同时修饰成员函数吗。
static的作用:
对变量:
- 局部变量:
在局部变量之前加上关键字static,局部变量就被定义成为一个局部静态变量。
[1].内存中的位置:静态存储区
[2].初始化:未经初始化的全局静态变量会被程序自动初始化为0(自动对象的值是任意的,除非他被显示初始化)
[3].作用域:作用域仍为局部作用域,当定义它的函数或者语句块结束的时候,作用域随之结束。
注:当static用来修饰局部变量的时候,它就改变了局部变量的存储位置(从原来的栈中存放改为静态存储区)及其生命周期(局部静态变量在离开作用域之后,并没有被销毁,而是仍然驻留在内存当中,直到程序结束,只不过我们不能再对他进行访问),但未改变其作用域。
- 全局变量
在全局变量之前加上关键字static,全局变量就被定义成为一个全局静态变量。
[1].内存中的位置:静态存储区(静态存储区在整个程序运行期间都存在)
[2].初始化:未经初始化的全局静态变量会被程序自动初始化为0(自动对象的值是任意的,除非他被显示初始化)
[3].作用域:全局静态变量在声明他的文件之外是不可见的。准确地讲从定义之处开始到文件结尾。
注:static修饰全局变量,并为改变其存储位置及生命周期,而是改变了其作用域,使当前文件外的源文件无法访问该变量,好处如下:(1)不会被其他文件所访问,修改(2)其他文件中可以使用相同名字的变量,不会发生冲突。对全局函数也是有隐藏作用。
对类中的
- 成员变量
用static修饰类的数据成员实际使其成为类的全局变量,会被类的所有对象共享,包括派生类的对象。因此,static成员必须在类外进行初始化(初始化格式: int base::var=10;),而不能在构造函数内进行初始化,不过也可以用const修饰static数据成员在类内初始化 。
特点:
[1].不要试图在头文件中定义(初始化)静态数据成员。在大多数的情况下,这样做会引起重复定义这样的错误。即使加上#ifndef #define #endif或者#pragma once也不行。
[2].静态数据成员可以成为成员函数的可选参数,而普通数据成员则不可以。
[3].静态数据成员的类型可以是所属类的类型,而普通数据成员则不可以。普通数据成员的只能声明为 所属类类型的指针或引用。
- 成员函数
特点:
[1].用static修饰成员函数,使这个类只存在这一份函数,所有对象共享该函数,不含this指针。
[2].静态成员是可以独立访问的,也就是说,无须创建任何对象实例就可以访问。base::func(5,3);当static成员函数在类外定义时不需要加static修饰符。
[3].在静态成员函数的实现中不能直接引用类中说明的非静态成员,可以引用类中说明的静态成员。因为静态成员函数不含this指针。
不可以同时用const和static修饰成员函数。
C++编译器在实现const的成员函数的时候为了确保该函数不能修改类的实例的状态,会在函数中添加一个隐式的参数const this*。但当一个成员为static的时候,该函数是没有this指针的。也就是说此时const的用法和static是冲突的。
我们也可以这样理解:两者的语意是矛盾的。static的作用是表示该函数只作用在类型的静态变量上,与类的实例没有关系;而const的作用是确保函数不能修改类的实例的状态,与类型的静态变量没有关系。因此不能同时用它们。
const的作用:
1.限定变量为不可修改。
2.限定成员函数不可以修改任何数据成员。
3.const与指针:
const char *p 表示 指向的内容不能改变。
char * const p,就是将P声明为常指针,它的地址不能改变,是固定的,但是它的内容可以改变。
3.指针和引用的区别,引用可以用常指针实现吗。
本质上的区别是,指针是一个新的变量,只是这个变量存储的是另一个变量的地址,我们通过访问这个地址来修改变量。
而引用只是一个别名,还是变量本身。对引用进行的任何操作就是对变量本身进行操作,因此以达到修改变量的目的。

(1)指针:指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元;而引用跟原来的变量实质上是同一个东西,只不过是原变量的一个别名而已。如:
int a=1;int *p=&a;
int a=1;int &b=a;
上面定义了一个整形变量和一个指针变量p,该指针变量指向a的存储单元,即p的值是a存储单元的地址。
而下面2句定义了一个整形变量a和这个整形a的引用b,事实上a和b是同一个东西,在内存占有同一个存储单元。
(2)可以有const指针,但是没有const引用;
(3)指针可以有多级,但是引用只能是一级(int **p;合法 而 int &&a是不合法的)
(4)指针的值可以为空,但是引用的值不能为NULL,并且引用在定义的时候必须初始化;
(5)指针的值在初始化后可以改变,即指向其它的存储单元,而引用在进行初始化后就不会再改变了。
(6)"sizeof引用"得到的是所指向的变量(对象)的大小,而"sizeof指针"得到的是指针本身的大小;
(7)指针和引用的自增(++)运算意义不一样;
指针传参的时候,还是值传递,试图修改传进来的指针的值是不可以的。只能修改地址所保存变量的值。
引用传参的时候,传进来的就是变量本身,因此可以被修改。
4.什么是多态,多态有什么用途。
[1].定义:“一个接口,多种方法”,程序在运行时才决定调用的函数。
[2].实现:C++多态性主要是通过虚函数实现的,虚函数允许子类重写override(注意和overload的区别,overload是重载,是允许同名函数的表现,这些函数参数列表/类型不同)。
多态与非多态的实质区别就是函数地址是早绑定还是晚绑定。
如果函数的调用,在编译器编译期间就可以确定函数的调用地址,并生产代码,是静态的,就是说地址是早绑定的。
而如果函数调用的地址不能在编译器期间确定,需要在运行时才确定,这就属于晚绑定。
[3].目的:接口重用。封装可以使得代码模块化,继承可以扩展已存在的代码,他们的目的都是为了代码重用。而多态的目的则是为了接口重用。
[4].用法:声明基类的指针,利用该指针指向任意一个子类对象,调用相应的虚函数,可以根据指向的子类的不同而实现不同的方法。
补充一下关于重载、重写、隐藏(总是不记得)的区别:
Overload(重载):在C++程序中,可以将语义、功能相似的几个函数用同一个名字表示,但参数或返回值不同(包括类型、顺序不同),即函数重载。
(1)相同的范围(在同一个类中);
(2)函数名字相同;
(3)参数不同;
(4)virtual 关键字可有可无。
Override(覆盖):是指派生类函数覆盖基类函数,特征是:
(1)不同的范围(分别位于派生类与基类);
(2)函数名字相同;
(3)参数相同;
(4)基类函数必须有virtual 关键字。
注:重写基类虚函数的时候,会自动转换这个函数为virtual函数,不管有没有加virtual,因此重写的时候不加virtual也是可以的,不过为了易读性,还是加上比较好。
Overwrite(重写):隐藏,是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)。
补充一下虚函数表:
多态是由虚函数实现的,而虚函数主要是通过虚函数表(V-Table)来实现的。
如果一个类中包含虚函数(virtual修饰的函数),那么这个类就会包含一张虚函数表,虚函数表存储的每一项是一个虚函数的地址。如下图:
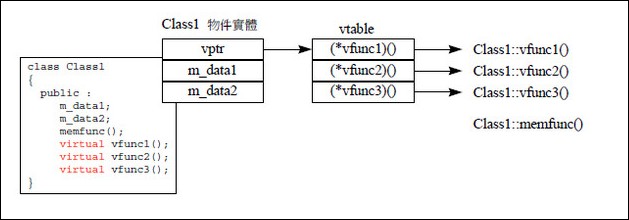
这个类的每一个对象都会包含一个虚指针(虚指针存在于对象实例地址的最前面,保证虚函数表有最高的性能),这个虚指针指向虚函数表。
注:对象不包含虚函数表,只有虚指针,类才包含虚函数表,派生类会生成一个兼容基类的虚函数表。
- 原始基类的虚函数表
下图是原始基类的对象,可以看到虚指针在地址的最前面,指向基类的虚函数表(假设基类定义了3个虚函数)
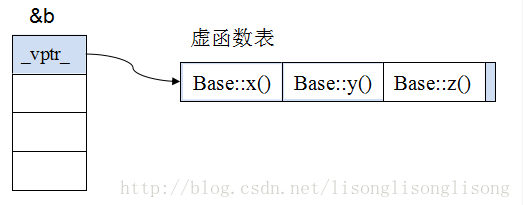
- 单继承时的虚函数(无重写基类虚函数)
假设现在派生类继承基类,并且重新定义了3个虚函数,派生类会自己产生一个兼容基类虚函数表的属于自己的虚函数表。

Derive class 继承了 Base class 中的三个虚函数,准确的说,是该函数实体的地址被拷贝到 Derive类的虚函数表,派生类新增的虚函数置于虚函数表的后面,并按声明顺序存放。
- 单继承时的虚函数(重写基类虚函数)
现在派生类重写基类的x函数,可以看到这个派生类构建自己的虚函数表的时候,修改了base::x()这一项,指向了自己的虚函数。

- 多重继承时的虚函数(Derived ::public Base1,public Base2)
这个派生类多重继承了两个基类base1,base2,因此它有两个虚函数表。

它的对象会有多个虚指针(据说和编译器相关),指向不同的虚函数表。
多重继承时指针的调整:
Derive b;
Base1* ptr1 = &b; // 指向 b 的初始地址
Base2* ptr2 = &b; // 指向 b 的第二个子对象
因为 Base1 是第一个基类,所以 ptr1 指向的是 Derive 对象的起始地址,不需要调整指针(偏移)。
因为 Base2 是第二个基类,所以必须对指针进行调整,即加上一个 offset,让 ptr2 指向 Base2 子对象。
当然,上述过程是由编译器完成的。
Base1* b1 = (Base1*)ptr2;
b1->y(); // 输出 Base2::y()
Base2* b2 = (Base2*)ptr1;
b2->y(); // 输出 Base1::y()
其实,通过某个类型的指针访问某个成员时,编译器只是根据类型的定义查找这个成员所在偏移量,用这个偏移量获取成员。由于 ptr2 本来就指向 Base2 子对象的起始地址,所以b1->y()调用到的是Base2::y(),而 ptr1 本来就指向 Base1 子对象的起始地址(即 Derive对象的起始地址),所以b2->y()调用到的是Base1::y()。
- 虚继承时的虚函数表
虚继承的引入把对象的模型变得十分复杂,除了每个基类(MyClassA和MyClassB)和公共基类(MyClass)的虚函数表指针需要记录外,每个虚拟继承了MyClass的父类还需要记录一个虚基类表vbtable的指针vbptr。MyClassC的对象模型如图4所示。

虚基类表每项记录了被继承的虚基类子对象相对于虚基类表指针的偏移量。比如MyClassA的虚基类表第二项记录值为24,正是MyClass::vfptr相对于MyClassA::vbptr的偏移量,同理MyClassB的虚基类表第二项记录值12也正是MyClass::vfptr相对于MyClassA::vbptr的偏移量。(虚函数与虚继承深入探讨)
对象模型探讨:
1.没有继承情况,vptr存放在对象的开始位置,以下是Base1的内存布局
|
m_iData :100 |
2.单继承的情况下,对象只有一个vptr,它存放在对象的开始位置,派生类子对象在父类子对象的最后面,以下是D1的内存布局
|
B1:: m_iData : 100 |
|
B1::vptr : 4294800 |
|
B2::vptr : 4294776 |
|
D::m_iData :300 |
3. 虚拟继承情况下,虚父类子对象会放在派生类子对象之后,派生类子对象的第一个位置存放着一个vptr,虚拟子类子对象也会保存一个vptr,以下是VD1的内存布局
|
Unknown : 4294888 |
|
B1::vptr :4294864 |
|
VD1::vptr : 4294944 |
|
VD1::m_iData : 200 |
|
VD2::Unknown : 4294952 |
|
VD::m_iData : 500 |
|
B1::m_iData : 100 |
4. 棱形继承的情况下,非虚基类子对象在派生类子对象前面,并按照声明顺序排列,虚基类子对象在派生类子对象后面
|
VD1::Unknown : 4294968 |
|
VD2::vptr : 4 294932 |
|
VD2::m_iData : 300 |
|
B1::vptr : 4294920 |
|
B1::m_iData : 100 |
补充一下纯虚函数:
- 定义: 在很多情况下,基类本身生成对象是不合情理的。为了解决这个问题,方便使用类的多态性,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;)纯虚函数不能再在基类中实现,编译器要求在派生类中必须予以重写以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。
- 特点:
[1].当想在基类中抽象出一个方法,且该基类只做能被继承,而不能被实例化;(避免类被实例化且在编译时候被发现,可以采用此方法)
[2].这个方法必须在派生类(derived class)中被实现;
- 目的:使派生类仅仅只是继承函数的接口。
- 定义:称带有纯虚函数的类为抽象类。
- 作用:为一个继承体系提供一个公共的根,为派生类提供操作接口的通用语义。
- 特点:[1].抽象类只能作为基类来使用,而继承了抽象类的派生类如果没有实现纯虚函数,而只是继承纯虚函数,那么该类仍旧是一个抽象类,如果实现了纯虚函数,就不再是抽象类。
class Panda : public Bear, public Endangered {
}
构造:
1.派生类的对象包含每个基类的基类子对象。
2.派生类构造函数初始化所有基类(多重继承中若没有显式调用某个基类的构造函数,则编译器会调用该基类默认构造函数),派生类只能初始化自己的基类,并不需要考虑基类的基类怎么初始化。
3.多重继承时,基类构造函数按照基类构造函数在类派生列表中的出现次序调用。
深拷贝与浅拷贝:
浅拷贝:默认的复制构造函数只是完成了对象之间的位拷贝,也就是把对象里的值完全复制给另一个对象,如A=B。这时,如果B中有一个成员变量指针已经申请了内存,
那A中的那个成员变量也指向同一块内存。
这就出现了问题:当B把内存释放了(如:析构),这时A内的指针就是野指针了,出现运行错误。
深拷贝:自定义复制构造函数需要注意,对象之间发生复制,资源重新分配,即A有5个空间,B也应该有5个空间,而不是指向A的5个空间。
定义:在多重继承下,一个基类可以在派生层次中出现多次。(派生类对象中可能出现多个基类对象)在 C++ 中,通过使用虚继承解决这类问题。虚继承是一种机制,类通过虚继承指出它希望共享其虚基类的状态。在虚继承下,对给定虚基类,无论该类在派生层次中作为虚基类出现多少次,只继承一个共享的基类子对象。共享的基类子对象称为虚基类。
class istream : public virtual ios { ... };
class ostream : virtual public ios { ... };
// iostream inherits only one copy of its ios base class
class iostream: public istream, public ostream { ... };
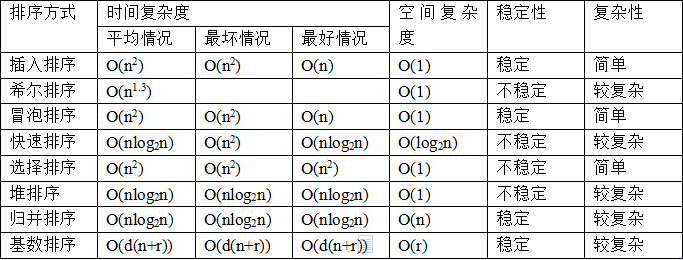
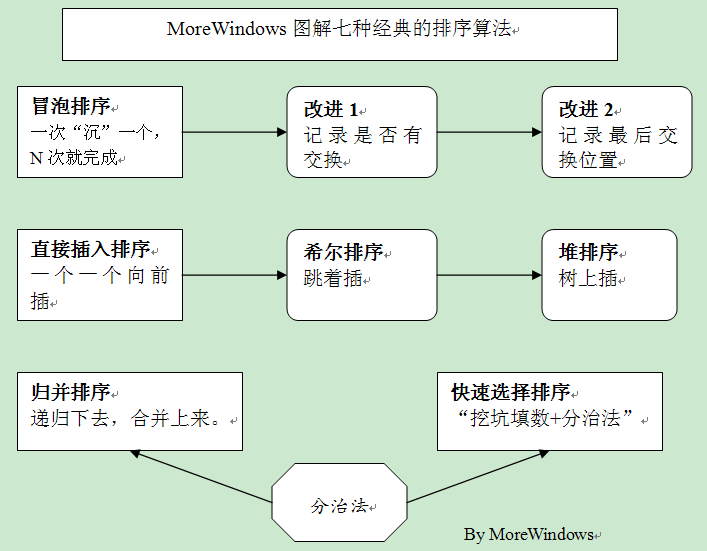
- 插入排序
每次将一个待排序的数据,跟前面已经有序的序列的数字一一比较找到自己合适的位置,插入到序列中,直到全部数据插入完成。
- 希尔排序
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。由于希尔排序是对相隔若干距离的数据进行直接插入排序,因此可以形象的称希尔排序为“跳着插”
- 冒泡排序
通过交换使相邻的两个数变成小数在前大数在后,这样每次遍历后,最大的数就“沉”到最后面了。重复N次即可以使数组有序。
冒泡排序改进1:在某次遍历中如果没有数据交换,说明整个数组已经有序。因此通过设置标志位来记录此次遍历有无数据交换就可以判断是否要继续循环。
冒泡排序改进2:记录某次遍历时最后发生数据交换的位置,这个位置之后的数据显然已经有序了。因此通过记录最后发生数据交换的位置就可以确定下次循环的范围了。
- 快速排序
“挖坑填数+分治法”,首先令i =L; j = R; 将a[i]挖出形成第一个坑,称a[i]为基准数。然后j--由后向前找比基准数小的数,找到后挖出此数填入前一个坑a[i]中,再i++由前向后找比基准数大的数,找到后也挖出此数填到前一个坑a[j]中。重复进行这种“挖坑填数”直到i==j。再将基准数填入a[i]中,这样i之前的数都比基准数小,i之后的数都比基准数大。因此将数组分成二部分再分别重复上述步骤就完成了排序。
- 选择排序
数组分成有序区和无序区,初始时整个数组都是无序区,然后每次从无序区选一个最小的元素直接放到有序区的最后,直到整个数组变有序区。
- 堆排序
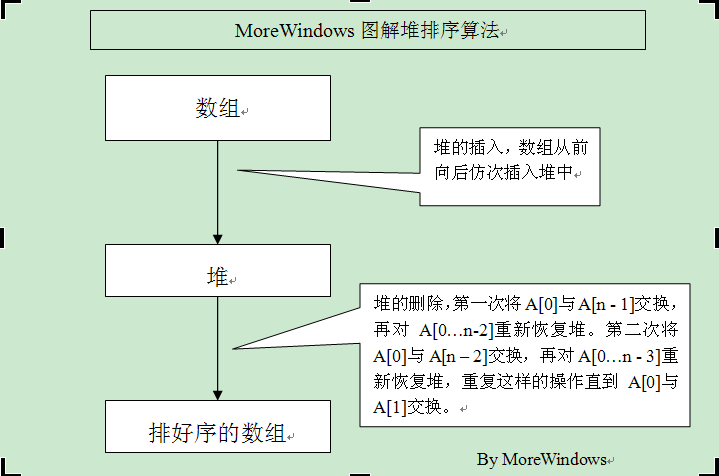
堆的插入就是——每次插入都是将新数据放在数组最后,而从这个新数据的父结点到根结点必定是一个有序的数列,因此只要将这个新数据插入到这个有序数列中即可。
堆的删除就是——堆的删除就是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。调整时先在左右儿子结点中找最小的,如果父结点比这个最小的子结点还小说明不需要调整了,反之将父结点和它交换后再考虑后面的结点。相当于从根结点开始将一个数据在有序数列中进行“下沉”。
因此,堆的插入和删除非常类似直接插入排序,只不是在二叉树上进行插入过程。所以可以将堆排序形容为“树上插”
- 归并排序
归并排序主要分为两步:分数列(divide),每次把数列一分为二,然后分到只有两个元素的小数列;合数列(Merge),合并两个已经内部有序的子序列,直至所有数字有序。用递归可以实现。
- 基数排序(桶排序)
基数排序,第一步根据数字的个位分配到每个桶里,在桶内部排序,然后将数字再输出(串起来);然后根据十位分桶,继续排序,再串起来。直至所有位被比较完,所有数字已经有序。
6.vector中size()和capacity()的区别。
size()指容器当前拥有的元素个数(对应的resize(size_type)会在容器尾添加或删除一些元素,来调整容器中实际的内容,使容器达到指定的大小。);capacity()指容器在必须分配存储空间之前可以存储的元素总数。
size表示的这个vector里容纳了多少个元素,capacity表示vector能够容纳多少元素,它们的不同是在于vector的size是2倍增长的。如果vector的大小不够了,比如现在的capacity是4,插入到第五个元素的时候,发现不够了,此时会给他重新分配8个空间,把原来的数据及新的数据复制到这个新分配的空间里。(会有迭代器失效的问题)
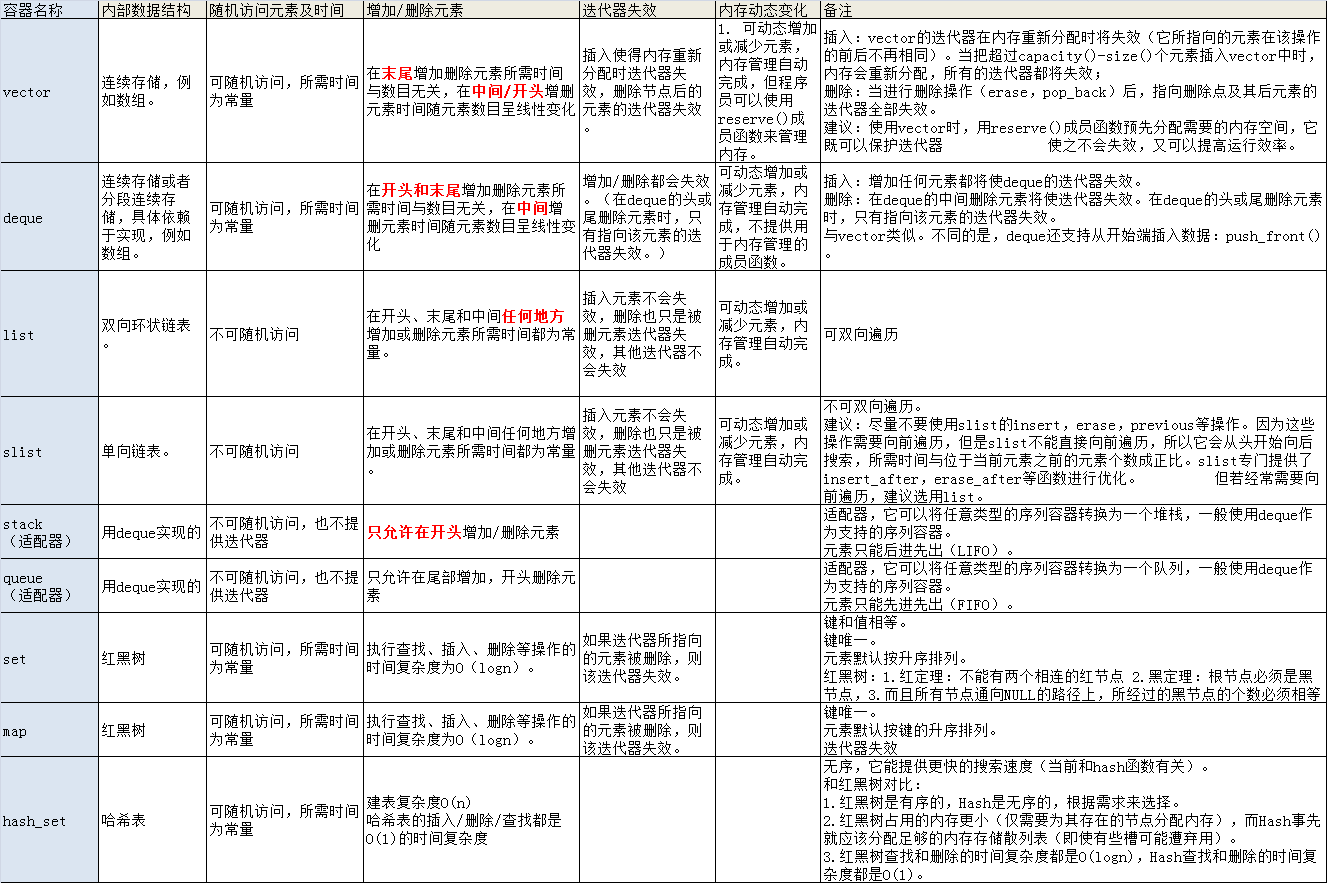
各容器的特点:
7.map和set的原理。
map和set的底层实现主要是由红黑树实现的。
红黑树:
(深入探讨红黑树)
8.tcp为什么要三次握手,tcp为什么可靠。
为什么不能两次握手:(防止已失效的连接请求又传送到服务器端,因而产生错误)
假设改为两次握手,client端发送的一个连接请求在服务器滞留了,这个连接请求是无效的,client已经是closed的状态了,而服务器认为client想要建立
一个新的连接,于是向client发送确认报文段,而client端是closed状态,无论收到什么报文都会丢弃。而如果是两次握手的话,此时就已经建立连接了。
服务器此时会一直等到client端发来数据,这样就浪费掉很多server端的资源。
(校注:此时因为client没有发起建立连接请求,所以client处于CLOSED状态,接受到任何包都会丢弃。
但是如果服务器发送对这个延误的旧连接报文的确认的同时,客户端调用connect函数发起了连接,就会使客户端进入SYN_SEND状态,当服务器那个对延误旧连接报文的确认传到客户端时,
因为客户端已经处于SYN_SEND状态,所以就会使客户端进入ESTABLISHED状态,此时服务器端反而丢弃了这个重复的通过connect函数发送的SYN包,见第三个图。
而连接建立之后,发送包由于SEQ是以被丢弃的SYN包的序号为准,而服务器接收序号是以那个延误旧连接SYN报文序号为准,导致服务器丢弃后续发送的数据包)
三次握手的最主要目的是保证连接是双工的,可靠更多的是通过重传机制来保证的。
TCP可靠传输的实现:
TCP 连接的每一端都必须设有两个窗口——一个发送窗口和一个接收窗口。TCP 的可靠传输机制用字节的序号进行控制。TCP 所有的确认都是基于序号而不是基于报文段。
发送过的数据未收到确认之前必须保留,以便超时重传时使用。发送窗口没收到确认不动,和收到新的确认后前移。
发送缓存用来暂时存放: 发送应用程序传送给发送方 TCP 准备发送的数据;TCP 已发送出但尚未收到确认的数据。
接收缓存用来暂时存放:按序到达的、但尚未被接收应用程序读取的数据; 不按序到达的数据。
必须强调三点:
1> A 的发送窗口并不总是和 B 的接收窗口一样大(因为有一定的时间滞后)。
2> TCP 标准没有规定对不按序到达的数据应如何处理。通常是先临时存放在接收窗口中,等到字节流中所缺少的字节收到后,再按序交付上层的应用进程。
3> TCP 要求接收方必须有累积确认的功能,这样可以减小传输开销
- TCP报文格式
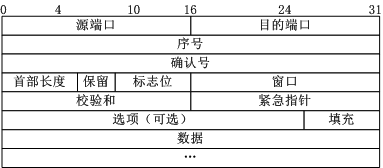
(1)序号:Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
(2)确认序号:Ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,Ack=Seq+1。
(3)标志位:共6个,即URG、ACK、PSH、RST、SYN、FIN等,具体含义如下:
(A)URG:紧急指针(urgent pointer)有效。
(B)ACK:确认序号有效。
(C)PSH:接收方应该尽快将这个报文交给应用层。
(D)RST:重置连接。
(E)SYN:发起一个新连接。
(F)FIN:释放一个连接。
需要注意的是:
(A)不要将确认序号Ack与标志位中的ACK搞混了。
(B)确认方Ack=发起方Req+1,两端配对。
- 三次握手
TCP三次即建立TCP连接,指建立一个TCP连接时,需要客户端服务端总共发送3 个包以确认连接的建立。在socket编程中,这一过程中由客户端执行connect来触发,流程如下:
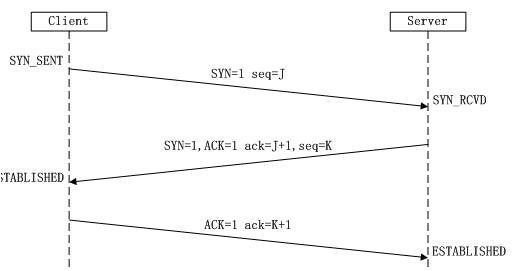
(1)第一次握手:Client将标志位SYN置为1(表示要发起一个连接),随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3)第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
SYN攻击:
在三次握手过程中,Server发送SYN-ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),
此时Server处于SYN_RCVD状态,当收到ACK后,Server转入ESTABLISHED状态。
SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server回复确认包,并等待Client的确认,由于源地址是不存在的,
因此,Server需要不断重发直至超时,这些伪造的SYN包将产时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。
SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
#netstat -nap | grep SYN_RECV
ddos攻击:
分布式拒绝服务(DDoS:Distributed Denial of Service)攻击指借助于客户/服务器技术,
将多个计算机联合起来作为攻击平台,对一个或多个目标发动DDoS攻击,从而成倍地提高拒绝服务攻击的威力。
通常,攻击者使用一个偷窃帐号将DDoS主控程序安装在一个计算机上,在一个设定的时间主控程序将与大量代理程序通讯,代理程序已经被安装在网络上的许多计算机上。
代理程序收到指令时就发动攻击。利用客户/服务器技术,主控程序能在几秒钟内激活成百上千次代理程序的运行。
- 四次挥手
所谓四次挥手(Four-Way Wavehand)即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发,整个流程如下图所示:
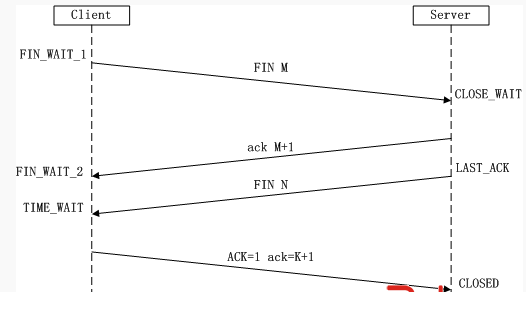
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭,上图描述的即是如此。
(1)第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
(2)第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
(3)第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
(4)第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
为什么需要TIME_WAIT
TIMEWAIT状态也称为2MSL等待状态。
1)为实现TCP这种全双工(full-duplex)连接的可靠释放
这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。这种2MSL等待的另一个结果是这个TCP连接在2MSL等待期间,定义这个连接的插口(客户的IP地址和端口号,服务器的IP地址和端口号)不能再被使用。这个连接只能在2MSL结束后才能再被使用。
2)为使旧的数据包在网络因过期而消失
每个具体TCP实现必须选择一个报文段最大生存时间MSL(Maximum Segment Lifetime)。它是任何报文段被丢弃前在网络内的最长时间。
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,我们也未必全部数据都发送给对方了,所以我们不可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,我们的ACK和FIN一般都会分开发送。
9.函数调用和系统调用的区别。
什么是系统调用?(常见Linux及其分类表)
所谓系统调用就是用户在程序中调用操作系统所提供的一个子功能,也就是系统API,系统调用可以被看做特殊的公共子程序。系统中的各种共享资源都由操作系统统一掌管,因此在用户程序中,凡是与资源有关的操作(如存储分配、进行I/O传输及管理文件等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。通常,一个操作系统提供的系统调用命令有几十个乃至上百个之多。这些系统调用按照功能大致可以分为以下几类:
- 设备管理:完成设备的请求或释放,以及设备启动等功能。
- 文件管理:完成文件的读、写、创建及删除等功能
- 进程控制:完成进程的创建、撤销、阻塞、及唤醒的功能
- 进程通信:完成进程之间的消息传递或信号的传递
- 内存管理:完成内存的分配、回收以及获取作业占用内存区大小及始址等功能。
显然,系统调用运行在系统的核心态。通过系统调用的方式来使用系统功能,可以保证系统的稳定性和安全性,防止用户随意更改或访问系统的数据或命令。系统调用命令式由操作系统提供的一个或多个子程序模块来实现的。
下图详细阐述了,Linux系统中系统调用的过程:(int 0x80中断向量是dos系统返回,int 3中断向量是断点指令——可以查中断向量表)

库是可重用的模块,处于用户态。
系统调用是操作系统提供的服务,处于内核态,不能直接调用,而要使用类似int 0x80的软中断陷入内核,所以库函数中有很大部分是对系统调用的封装。
既然如此,如何调用系统调用?
用户是处于用户态,具有的权限是非常有限,肯定是不能直接使用内核态的服务,只能间接通过有访问权限的API函数内嵌的系统调用函数来调用。
介绍下系统调用的过程:
首先将API函数参数压到栈上,然后将函数内调用系统调用的代码放入寄存器,通过陷入中断,进入内核将控制权交给操作系统,操作系统获得控制后,将系统调用代码拿出来,跟操作系统一直维护的一张系统调用表做比较,已找到该系统调用程序体的内存地址,接着访问该地址,执行系统调用。执行完毕后,返回用户程序

例子:
int main()
{
int fd = create("filename",0666);
exit(0);
}
补充一下系统调用和库函数的区别:
系统调用:是操作系统为用户态运行的进程和硬件设备(如CPU、磁盘、打印机等)进行交互提供的一组接口,即就是设置在应用程序和硬件设备之间的一个接口层。
可以说是操作系统留给用户程序的一个接口。再来说一下,linux内核是单内核,结构紧凑,执行速度快,各个模块之间是直接调用的关系。放眼望整个linux系统,
从上到下依次是用户进程->linux内核->硬件。
其中系统调用接口是位于Linux内核中的,如果再稍微细分一下的话,整个linux系统从上到下可以是:用户进程->系统调用接口->linux内核子系统->硬件,
也就是说Linux内核包括了系统调用接口和内核子系统两部分;
或者从下到上可以是:物理硬件->OS内核->OS服务->应用程序,其中操作系统起到“承上启下”的关键作用,向下管理物理硬件,向上为操作系服务和应用程序提供接口,
这里的接口就是系统调用了。
一般地,操作系统为了考虑实现的难度和管理的方便,它只提供一少部分的系统调用,这些系统调用一般都是由C和汇编混合编写实现的,
其接口用C来定义,而具体的实现则是汇编,这样的好处就是执行效率高,而且,极大的方便了上层调用。 库函数:顾名思义是把函数放到库里。是把一些常用到的函数编完放到一个文件里,供别人用。
别人用的时候把它所在的文件名用#include<>加到里面就可以了。一般是放到lib文件里的。
一般是指编译器提供的可在c源程序中调用的函数。可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数。
(由于版权原因,库函数的源代码一般是不可见的,但在头文件中你可以看到它对外的接口)
libc中就是一个C标准库,里面存放一些基本函数,这些基本函数都是被标准化了的,而且这些函数通常都是用汇编直接实现的。
库函数一般可以概括的分为两类,一类是随着操作系统提供的,另一类是由第三方提供的。
随着系统提供的这些库函数把系统调用进行封装或者组合,可以实现更多的功能,这样的库函数能够实现一些对内核来说比较复杂的操作。
比如,read()函数根据参数,直接就能读文件,而背后隐藏的比如文件在硬盘的哪个磁道,哪个扇区,加载到内存的哪个位置等等这些操作,程序员是不必关心的,
这些操作里面自然也包含了系统调用。而对于第三方的库,它其实和系统库一样,只是它直接利用系统调用的可能性要小一些,而是利用系统提供的API接口来实现功能(API的接口是开放的)。
部分Libc库中的函数的功能的实现还是借助了系统掉调用,比如printf的实现最终还是调用了write这样的系统调用;而另一些则不会使用系统调用,比如strlen, strcat, memcpy等。 实时上,系统调用所提供给用户的是直接而纯粹的高级服务,如果想要更人性化,具有更符合特定情况的功能,那么就要我们用户自己来定义,因此就衍生了库函数,它把部分系统调用包装起来,
一方面把系统调用抽象了,一方面方便了用户级的调用。系统调用和库函数在执行的效果上很相似(当然库函数会更符合需求),
但是系统调用是运行于内核状态;而库函数由用户调用,运行于用户态。 系统调用是为了方便使用操作系统的接口,而库函数则是为了人们编程的方便。
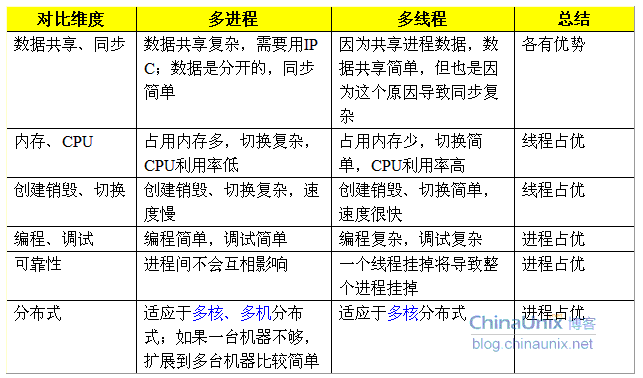
10.线程和进程,线程可以共享进程里的哪些东西。 知道协程是什么吗
进程,是并发执行的程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间,即进程空间或(虚空间)。进程空间的大小 只与处理机的位数有关,一个 16 位长处理机的进程空间大小为 216 ,而 32 位处理机的进程空间大小为 232 。进程至少有 5 种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
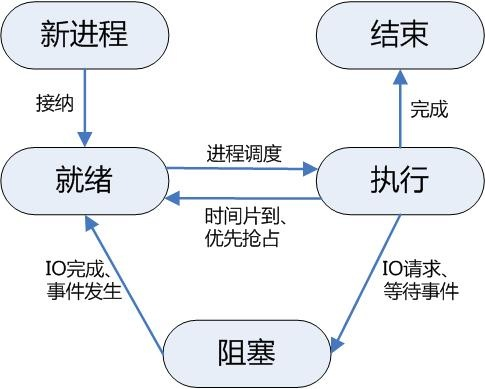
线程,在网络或多用户环境下,一个服务器通常需要接收大量且不确定数量用户的并发请求,为每一个请求都创建一个进程显然是行不通的,——无论是从系统资源开销方面或是响应用户请求的效率方面来看。因此,操作系统中线程的概念便被引进了。线程,是进程的一部分,一个没有线程的进程可以被看作是单线程的。线程有时又被称为轻权进程或轻量级进程,也是 CPU 调度的一个基本单位。
共享进程的地址空间,全局变量(数据和堆)。在一个进程中,各个线程共享堆区,而进程中的线程各自维持自己的栈。
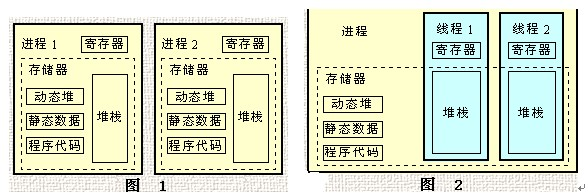
Each thread has its own:
- 栈区和栈指针(Stack area and stack pointer)
- 寄存器(Registers)
- 调度优先级Scheduling properties (such as policy or priority)
- 信号(阻塞和悬挂)Signals (pending and blocked signals)
- 普通变量Thread specific data ( automatic variables )
线程是指进程内的一个执行单元,也是进程内的可调度实体.
与进程的区别:
(1)地址空间:进程内的一个执行单元;进程至少有一个线程;它们共享进程的地址空间;而进程有自己独立的地址空间;
(2)资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
(3)线程是处理器调度的基本单位,但进程不是.
4)二者均可并发执行. 进程和线程都是由操作系统所体会的程序运行的基本单元,系统利用该基本单元实现系统对应用的并发性。进程和线程的区别在于: 简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
线程的划分尺度小于进程,使得多线程程序的并发性高。
另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。
这就是进程和线程的重要区别。 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),
但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行.
协程:
定义:协程其实可以认为是比线程更小的执行单元。为啥说他是一个执行单元,因为他自带CPU上下文。
协程切换:协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
(我们在自己在进程里面完成逻辑流调度,碰着i\o我就用非阻塞式的。那么我们即可以利用到异步优势,又可以避免反复系统调用,还有进程切换造成的开销,分分钟给你上几千个 逻辑流不费力。这就是协程。)
协程的调度完全由用户控制,一个线程可以有多个协程,用户创建了几个线程,然后每个线程都是循环按照指定的任务清单顺序完成不同的任务,当任务被堵塞的时候执行下一个任务,
当恢复的时候再回来执行这个任务,任务之间的切换只需要保存每个任务的上下文内容,就像直接操作栈一样的,这样就完全没有内核切换的开销,可以不加锁的访问全局变量,
所以上下文的切换非常快;另外协程还需要保证是非堵塞的且没有相互依赖,协程基本上不能同步通讯,多采用一步的消息通讯,效率比较高。
多线程和多进程的优劣:
多线程还是多进程的争执由来已久,这种争执最常见到在B/S通讯中服务端并发技术的选型上,
比如WEB服务器技术中,Apache是采用多进程的(perfork模式,每客户连接对应一个进程,每进程中只存在唯一一个执行线程),
Java的Web容器Tomcat、Websphere等都是多线程的(每客户连接对应一个线程,所有线程都在一个进程中)。
多进程:fork
多线程:pthread_create
11.mysql的数据库引擎有哪些,他们的区别
ISAM
ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库被查询的次数要远大于更新的次数。因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源。ISAM的两个主要不足之处在于,它不支持事务处理,也不能够容错:如果你的硬盘崩溃了,那么数据文件就无法恢复了。如果你正在把ISAM用在关键任务应用程序里,那就必须经常备份你所有的实时数据,通过其复制特性,MYSQL能够支持这样的备份应用程序。
MYISAM
MYISAM是MYSQL的ISAM扩展格式和缺省的数据库引擎。除了提供ISAM里所没有的索引和字段管理的大量功能,MYISAM还使用一种表格锁定的机制,来优化多个并发的读写操作。其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间。MYISAM还有一些有用的扩展,例如用来修复数据库文件的MYISAMCHK工具和用来恢复浪费空间的MYISAMPACK工具。
MYISAM强调了快速读取操作,这可能就是为什么MYSQL受到了WEB开发如此青睐的主要原因:在WEB开发中你所进行的大量数据操作都是读取操作。所以,大多数虚拟主机提供商和INTERNET平台提供商只允许使用MYISAM格式。
HEAP
HEAP允许只驻留在内存里的临时表格。驻留在内存使得HEAP比ISAM和MYISAM的速度都快,但是它所管理的数据是不稳定的,而且如果在关机之前没有进行保存,那么所有的数据都会丢失。在数据行被删除的时候,HEAP也不会浪费大量的空间,HEAP表格在你需要使用SELECT表达式来选择和操控数据的时候非常有用。要记住,用完表格后要删除表格。
INNODB和BERKLEYDB
INNODB和BERKLEYDB(BDB)数据库引擎都是造就MYSQL灵活性的技术的直接产品,这项技术就是MySql++ API。在使用MySql的时候,你所面对的每一个挑战几乎都源于ISAM和MYIASM数据库引擎不支持事务处理也不支持外来键。尽管要比ISAM和MYISAM引擎慢很多,但是INNODB和BDB包括了对事务处理和外来键的支持,这两点都是前两个引擎所没有的。如前所述,如果你的设计需要这些特性中的一者或者两者,那你就要被迫使用后两个引擎中的一个了。
12.makefile吗,一个文件依赖库a,库a依赖库b,写makefile的时候,a要放在b的前面还是后面
- Makefile概述:
什么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员,makefile还是要懂。这就好像现在有这么多的HTML的编辑器,但如果你想成为一个专业人士,你还是要了解HTML的标识的含义。特别在Unix下的软件编译,你就不能不自己写makefile了,会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
因为,makefile关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。
makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
现在讲述如何写makefile的文章比较少,这是我想写这篇文章的原因。当然,不同产商的make各不相同,也有不同的语法,但其本质都是在“文件依赖性”上做文章,这里,我仅对GNU的make进行讲述,我的环境是RedHat Linux 8.0,make的版本是3.80。必竟,这个make是应用最为广泛的,也是用得最多的。而且其还是最遵循于IEEE 1003.2-1992 标准的(POSIX.2)。
在这篇文档中,将以C/C++的源码作为我们基础,所以必然涉及一些关于C/C++的编译的知识,相关于这方面的内容,还请各位查看相关的编译器的文档。这里所默认的编译器是UNIX下的GCC和CC。
- 编译和连接:
编译:
定义:一般来说,无论是C、C++、还是pas,首先要把源文件编译成中间代码文件,在Windows下也就是 .obj 文件,UNIX下是 .o 文件,即 Object File,这个动作叫做编译(compile)。
描述:编译时,编译器需要的是语法的正确,函数与变量的声明的正确。只要所有的语法正确,编译器就可以编译出中间目标文件。一般来说,每个源文件都应该对应于一个中间目标文件(O文件或是OBJ文件)。
连接:
定义:然后再把大量的Object File合成执行文件,这个动作叫作链接(link)。
描述:通常是你需要告诉编译器头文件的所在位置(头文件中应该只是声明,而定义应该放在C/C++文件中),链接时,主要是链接函数和全局变量,所以,我们可以使用这些中间目标文件(O文件或是OBJ文件)来链接我们的应用程序。链接器并不管函数所在的源文件,只管函数的中间目标文件(Object File),在大多数时候,由于源文件太多,编译生成的中间目标文件太多,而在链接时需要明显地指出中间目标文件名,这对于编译很不方便,所以,我们要给中间目标文件打个包,在Windows下这种包叫“库文件”(Library File),也就是 .lib 文件,在UNIX下,是Archive File,也就是 .a 文件。
总结一下,源文件首先会生成中间目标文件,再由中间目标文件生成执行文件。在编译时,编译器只检测程序语法,和函数、变量是否被声明。如果函数未被声明,编译器会给出一个警告,但可以生成Object File。而在链接程序时,链接器会在所有的Object File中找寻函数的实现,如果找不到,那到就会报链接错误码(Linker Error),在VC下,这种错误一般是:Link 2001错误,意思说是说,链接器未能找到函数的实现。你需要指定函数的Object File.
- Makefile
make命令执行时,需要一个 Makefile 文件,以告诉make命令需要怎么样的去编译和链接程序。
首先,我们用一个示例来说明Makefile的书写规则。我们的规则是:
1)如果这个工程没有编译过,那么我们的所有C文件都要编译并被链接。
2)如果这个工程的某几个C文件被修改,那么我们只编译被修改的C文件,并链接目标程序。
3)如果这个工程的头文件被改变了,那么我们需要编译引用了这几个头文件的C文件,并链接目标程序。
只要我们的Makefile写得够好,所有的这一切,我们只用一个make命令就可以完成,make命令会自动智能地根据当前的文件修改的情况来确定哪些文件需要重编译,从而自己编译所需要的文件和链接目标程序。
Makefile的规则: target…:dependecies… command
target也就是一个目标文件,可以是Object File,也可以是执行文件。还可以是一个标签(Label),对于标签这种特性,在后续的“伪目标”章节中会有叙述。
dependicies就是,要生成那个target所需要的文件或是目标。
command也就是make需要执行的命令。(任意的Shell命令)
这是一个文件的依赖关系,也就是说,target这一个或多个的目标文件依赖于dependicies中的文件,其生成规则定义在command中。说白一点就是说,dependicies中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。这就是Makefile的规则。也就是Makefile中最核心的内容。(深入探讨makefile)
注意事项:
1.命令要以[Tab]为开始
2.有clean

C++基本知识点总结(网摘)的更多相关文章
- Feedly订阅Blog部落格RSS网摘 - Blog透视镜
网络信息爆炸的时代,如何更有效率地阅读文章,订阅RSS网摘,可以快速地浏览文章标题,当对某些文章有兴趣时,才点下连结连到原网站,阅读更详细的文章,Feedly Reader阅读器除了提供在线版订阅RS ...
- Bloglines订阅Blog部落格RSS网摘 - Blog透视镜
网络信息蓬勃发展,Blog部落格越来越普及,如果逐一地去浏览网站,势必费时费力,倘若信息可以自己送上门,那就可以节省不少时间,就好像看报纸的标题,有兴趣才点连结,进到网站浏览文章内容,Blogline ...
- TCP/IP协议头部结构体(网摘小结)(转)
源:TCP/IP协议头部结构体(网摘小结) TCP/IP协议头部结构体(转) 网络协议结构体定义 // i386 is little_endian. #ifndef LITTLE_ENDIAN #de ...
- Vim命令快捷键(网摘)
Vim命令快捷键(网摘) 原文出处:[?---->home]
- c#与C++类型转换网摘
转载自 C++和C#转换 https://www.cnblogs.com/zjoch/p/4147182.html c#与C++类型转换,网摘 //c++:HANDLE(void *) ...
- Delphi 中DataSnap技术网摘
Delphi2010中DataSnap技术网摘 一.为DataSnap系统服务程序添加描述 这几天一直在研究Delphi 2010的DataSnap,感觉功能真是很强大,现在足有理由证明Delphi7 ...
- Python入门及容易!网摘分享给大家!
Python:Python学习总结 背景 PHP的$和->让人输入的手疼(PHP确实非常简洁和强大,适合WEB编程),Ruby的#.@.@@也好不到哪里(OO人员最该学习的一门语言). Pyth ...
- C/C++ 知识点---sizeof使用规则及陷阱分析(网摘)
C/C++ 知识点---sizeof使用规则及陷阱分析 原文出处:[胖奇的专栏] 1.什么是sizeof 首先看一下sizeof在msdn上的定义: The sizeof keyword gi ...
- C/C++ 知识点---LIB和DLL的区别与使用(网摘)
LIB和DLL的区别与使用 原文出处:[远风工作室] 共有两种库:一种是LIB包含了函数所在的DLL文件和文件中函数位置的信息(入口),代码由运行时加载在进程空间中的DLL提供,称为动态链接库dyna ...
随机推荐
- KBEngine简单RPG-Demo源码解析(3)
十四:在世界中投放NPC/MonsterSpace的cell创建完毕之后, 引擎会调用base上的Space实体, 告知已经获得了cell(onGetCell),那么我们确认cell部分创建好了之后就 ...
- vue子父组件通信
之前在用vue写子父组件通信的时候,老是遇到问题!!! 子组件传值给父组件: 子组件:通过emit方法给父组件传值,这里的upparent是父组件要定义的方法 模板: <div v-on:cli ...
- Student implements java.io.Serializable
package JBJADV003; public class Student implements java.io.Serializable { private String name; priva ...
- vijos1698题解
题目: 船体的结构是不能随意修改的..那样会破坏整艘船和谐的韵律.. 虽然说.如果沿岸航行的话是不会预见太大的海浪的..但是还要小心保护轨杆和船帆.. 毕竟对于小s这样的单轨帆船...轨杆和船帆如果受 ...
- 【Python3之pymysql模块】
一.什么是 PyMySQL? PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb. PyMySQL 遵循 Python 数据库 ...
- JavaScript用typeof判断变量是数组还是对象,都返回object
在JavaScript中所有数据类型严格意义上都是对象,但实际使用中我们还是有类型之分,如果要判断一个变量是数组还是对象使用typeof搞不定,因为它全都返回object. 使用typeof加leng ...
- 输入三个整数x、y、z,请把这三个数由小到大输出
题目:输入三个整数x,y,z,请把这三个数由小到大输出. 程序分析:我们想办法把最小的数放到x上,先将x与y进行比较,如果x> y则将x与y的值进行交换,然后再用x与z进行比较,如果x> ...
- CSS单位
一.em单位:相对单位,相对于父级大小. <div class="fs"> 你看看我的字体大小 <div class="fs"> 你在看 ...
- Jenkins 的svn插件下载的代码不是最新代码的问题
项目组使用Jenkins做自动化的每日编译和单元测试.经常发现,当提交完代码后,在Jenkins的每日编译代码还是旧代码,刚提交的代码并没有check out出来. 后来发现Jenkins服务器的时间 ...
- Swift 轻量级网络层设计
前言 普遍我们的网络层设计的时候直接是如下结构APIManager.post(url, parameter,completeHandle),服务器配置在APIManager.m文件中进行配置.这样一个 ...