关于MySQL buffer pool的预读机制
1、线性预读
2、随机预读
一、预读机制
InnoDB在I/O的优化上有个比较重要的特性为预读,预读请求是一个i/o请求,它会异步地在缓冲池中预先回迁多个页面,预计很快就会需要这些页面,这些请求在一个范围内引入所有页面。InnoDB以64个page为一个extent,那么InnoDB的预读是以page为单位还是以extent?
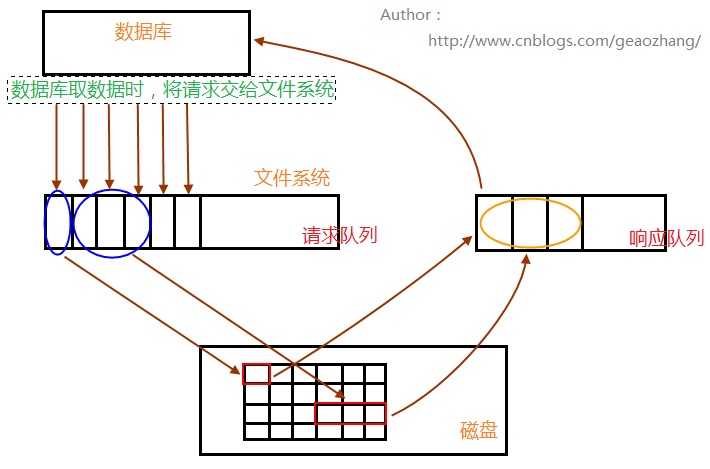
数据库请求数据的时候,会将读请求交给文件系统,放入请求队列中;相关进程从请求队列中将读请求取出,根据需求到相关数据区(内存、磁盘)读取数据;取出的数据,放入响应队列中,最后数据库就会从响应队列中将数据取走,完成一次数据读操作过程。
接着进程继续处理请求队列,(如果数据库是全表扫描的话,数据读请求将会占满请求队列),判断后面几个数据读请求的数据是否相邻,再根据自身系统IO带宽处理量,进行预读,进行读请求的合并处理,一次性读取多块数据放入响应队列中,再被数据库取走。(如此,一次物理读操作,实现多页数据读取,rrqm>0(# iostat -x),假设是4个读请求合并,则rrqm参数显示的就是4)
二、两种预读算法
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)
为了区分这两种预读的方式,我们可以把线性预读放到以extent为单位,而随机预读放到以extent中的page为单位。线性预读着眼于将下一个extent提前读取到buffer pool中,而随机预读着眼于将当前extent中的剩余的page提前读取到buffer pool中。
1、线性预读(linear read-ahead)
线性预读方式有一个很重要的变量控制是否将下一个extent预读到buffer pool中,通过使用配置参数innodb_read_ahead_threshold,控制触发innodb执行预读操作的时间。
如果一个extent中的被顺序读取的page超过或者等于该参数变量时,Innodb将会异步的将下一个extent读取到buffer pool中,innodb_read_ahead_threshold可以设置为0-64的任何值(因为一个extent中也就只有64页),默认值为56,值越高,访问模式检查越严格。
mysql> show variables like 'innodb_read_ahead_threshold';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_read_ahead_threshold | 56 |
+-----------------------------+-------+
例如,如果将值设置为48,则InnoDB只有在顺序访问当前extent中的48个pages时才触发线性预读请求,将下一个extent读到内存中。如果值为8,InnoDB触发异步预读,即使程序段中只有8页被顺序访问。
可以在MySQL配置文件中设置此参数的值,或者使用SET GLOBAL需要该SUPER权限的命令动态更改该参数。
在没有该变量之前,当访问到extent的最后一个page的时候,innodb会决定是否将下一个extent放入到buffer pool中。
2、随机预读(randomread-ahead)
随机预读方式则是表示当同一个extent中的一些page在buffer pool中发现时,Innodb会将该extent中的剩余page一并读到buffer pool中。
mysql> show variables like 'innodb_random_read_ahead';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_random_read_ahead | OFF |
+--------------------------+-------+
由于随机预读方式给innodb code带来了一些不必要的复杂性,同时在性能也存在不稳定性,在5.5中已经将这种预读方式废弃,默认是OFF。若要启用此功能,即将配置变量设置innodb_random_read_ahead为ON。
三、监控Innodb的预读
1、可以通过show engine innodb status\G显示统计信息
mysql> show engine innodb status\G
----------------------
BUFFER POOL AND MEMORY
----------------------
……
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
……
1、Pages read ahead:表示每秒读入的pages;
2、evicted without access:表示每秒读出的pages;
3、一般随机预读都是关闭的,也就是0。
2、通过两个状态值,评估预读算法的有效性
mysql> show global status like '%read_ahead%';
+---------------------------------------+-------+
| Variable_name | Value |
+---------------------------------------+-------+
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 2303 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
+---------------------------------------+-------+
3 rows in set (0.01 sec)
1、Innodb_buffer_pool_read_ahead:通过预读(后台线程)读入innodb buffer pool中数据页数
2、Innodb_buffer_pool_read_ahead_evicted:通过预读来的数据页没有被查询访问就被清理的pages,无效预读页数
关于MySQL buffer pool的预读机制的更多相关文章
- 【MySQL】mysql buffer pool结构分析
转自:http://blog.csdn.net/wyzxg/article/details/7700394 MySQL官网配置说明地址:http://dev.mysql.com/doc/refman/ ...
- [MySQL] Buffer Pool Adaptive Flush
Buffer Pool Adaptive Flush 在MySQL的帮助文档中Tuning InnoDB Buffer Pool Flushing提到, innodb_adaptive_flushin ...
- MySQL buffer pool中的三种链
三种page.三种list.LRU控制调优 一.innodb buffer pool中的三种页 1.free page:从未用过的页 2.clean page:干净的页,数据页的数据和磁盘一致 3.d ...
- Mysql InnoDB Buffer Pool
参考书籍<mysql是怎样运行的> 系列文章目录和关于我 一丶为什么需要Buffer Pool 对于InnoDB存储引擎的表来说,无论是用于存储用户数据的索引,还是各种系统数据,都是以页的 ...
- innodb buffer pool小解
INNODB维护了一个缓存数据和索引信息到内存的存储区叫做buffer pool,他会将最近访问的数据缓存到缓冲区.通过配置各个buffer pool的参数,我们可以显著提高MySQL的性能. INN ...
- 14.4.3.1 The InnoDB Buffer Pool
14.4.3.1 The InnoDB Buffer Pool 14.4.3.2 Configuring Multiple Buffer Pool Instances 14.4.3.3 Making ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 的设计原理和管理机制
一.缓冲池(Buffer Pool)的地位 在<MySQL 学习总结 之 InnoDB 存储引擎的架构设计>中,我们就讲到,缓冲池是 InnoDB 存储引擎中最重要的组件.因为为了提高 M ...
- MySQL · 引擎特性 · InnoDB Buffer Pool
前言 用户对数据库的最基本要求就是能高效的读取和存储数据,但是读写数据都涉及到与低速的设备交互,为了弥补两者之间的速度差异,所有数据库都有缓存池,用来管理相应的数据页,提高数据库的效率,当然也因为引入 ...
- MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库. 操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问. M ...
随机推荐
- Bootstrap模态弹出框
前面的话 在 Bootstrap 框架中把模态弹出框统一称为 Modal.这种弹出框效果在大多数 Web 网站的交互中都可见.比如点击一个按钮弹出一个框,弹出的框可能是一段文件描述,也可能带有按钮操作 ...
- Scrapy 爬虫实例教程(一)---简介及资源列表
Scrapy(官网 http://scrapy.org/)是一款功能强大的,用户可定制的网络爬虫软件包.其官方描述称:" Scrapy is a fast high-level screen ...
- JAVA - 深入JAVA 虚拟机 2
类的两种类型的类加载器 -Java虚拟机自带的加载器 根类加载器(Bootstrap): 使用C++编写,programer can not abtain this class. 扩展类加载器(Ext ...
- 如何查看安装的sql server是什么版本
方法 1:通过使用 SQL Server Management Studio 中的对象资源管理器连接到服务器.连接对象资源管理器后,它将显示版本信息(在括号中),以及用于连接到 SQL Server ...
- SpringMVC配置实例
一.SpringMVC概述 MVCII模式实现的框架技术 Model--业务模型(Biz,Dao...) View--jsp及相关的jquery框架技术(easyui) Contraller--Dis ...
- 一个简单、易用的Python命令行(terminal)进度条库
eprogress 是一个简单.易用的基于Python3的命令行(terminal)进度条库,可以自由选择使用单行显示.多行显示进度条或转圈加载方式,也可以混合使用. 示例 单行进度条 多行进度条 圆 ...
- Laravel 日志查看器 导入log-viewer扩展
1.修改配置文件 config\app.php中 'log'=>'daily' 日志文件是按天生成的 2.在项目目录中composer命令安装扩展:composer require arcan ...
- Python_网络爬虫(新浪新闻抓取)
爬取前的准备: BeautifulSoup的导入:pip install BeautifulSoup4 requests的导入:pip install requests 下载jupyter noteb ...
- ubuntu的/etc/modules内核模块文件
/etc/modules: 内核模块文件,里面列出的模块会在系统启动时自动加载. /etc/modprobe.d: 存放禁止加载或者加载内核模块脚本的目录. 以下是我增加netfilter模块是的流程 ...
- hiernate-session
一.概述 Session 是 Hibernate 向应用程序提供操纵数据的主要接口,它提供了基本的保存.更新.删除和加载 Java 对象的方法. 二.Session 缓存 1.简介 (1)Sessio ...