堆排序HeapSort
堆排序,顾名思义,是采用数据结构堆来进行排序的一种排序算法。
研究没有规律的堆,没有任何意义。特殊的堆有最大堆(父节点值大于等于左右字节点值),最小堆(父节点值小于等于子节点值)。一般采用最大堆来进行排序,图1为最大堆来表示一维数组。

图1 最大堆表示一维数组
2叉树堆的几点特性
1、 最后父节点索引值
不妨设堆的总元素个数为N;最后一个父节点的索引值Index = N/2 ;可以写几个简单的堆进行数学归纳。图1中的最后一个父节点5 = 10 /2 ;
这个特性主要是在采用自底向上构建堆的时候,循环起始值。

2、父节点与子节点索引值关系
LeftIndex = parent * 2;
RightIndex = parent * 2 + 1;
对于任意一个节点K,其父节点为K/2,其左子节点为2K,右子节点为2K+1。
Max-Heapify(保持最大堆属性)
散乱排布的堆对算法的实现非常不友好,没有意义。因此,在随机数据输入时,需要对数据按照最大堆的属性进行一个初始排序。对一个父节点数据的max-heapify形象的推导直接采用算法导论的图,如图2。节点2的数据显然不符合最大堆的数据定义(父节点值不小于子节点值),因此把MAX(parent,left,right)替换到父节点,父节点的数据替换 到子节点中。对于替换的子节点4,仍然需要判断其是否满足最大堆数据定义,一直递归到满足定义。


图2 max-heapify原理
构建最大堆
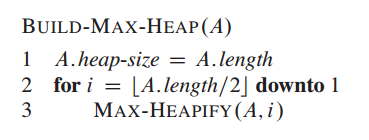
对所有的父节点都进行max-heapify操作,自底向上从最后父节点一直循环到根节点,很巧妙。采用自底向上能够保证遍历过的数据始终是保持最大堆属性的,max-heapify操作始终是求当前父节点下所有子节点的最大值。
那自顶向下会怎样呢?
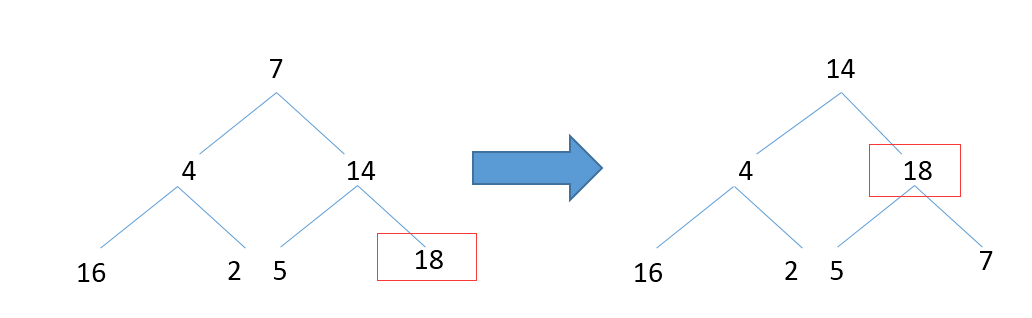
第一次max-heapify后,根节点并没有变成最大值,还要再遍历下根节点,这个显然在算法设计上不合适。所以自底向上的构思很巧妙。
HeapSort

首先保证输出数据满足最大堆的数据属性(第一行),然后把最大值提取出来存储在数组末端;然后计算剩下数据的最大堆,把最大值提出来;循环操作到排序完成。采用算法导论图解

编程实现
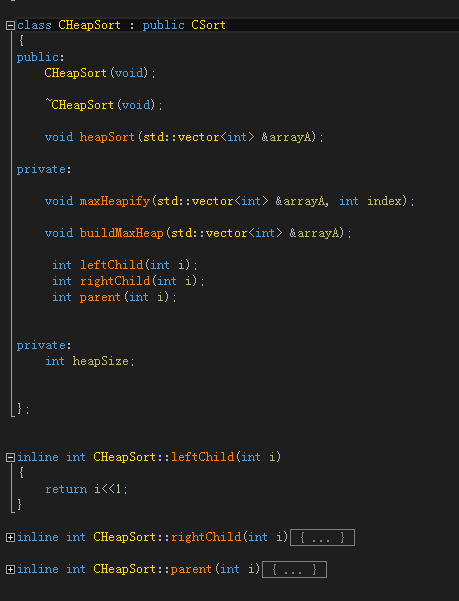
void CHeapSort::maxHeapify( std::vector<int> &arrayA, int index )
{ int l = leftChild(index);
int r = rightChild(index); int maxValue = ; if(l < heapSize && arrayA[l] > arrayA[index])
{
maxValue = l;
}
else
{
maxValue = index;
} if(r < heapSize && arrayA[r] > arrayA[maxValue])
{
maxValue = r;
} /* 父节点部位最大值 */
if(maxValue != index)
{
std::swap(arrayA[index],arrayA[maxValue]);
maxHeapify(arrayA,maxValue);
} } void CHeapSort::buildMaxHeap( std::vector<int> &arrayA )
{
heapSize = arrayA.size();
int halfSize = heapSize >> ; for(int i = halfSize ;i >= ; i--)
{
maxHeapify(arrayA,i);
}
} void CHeapSort::heapSort( std::vector<int> &arrayA )
{
buildMaxHeap(arrayA); for(int i = arrayA.size() - ; i > ; i--)
{
std::swap(arrayA[],arrayA[i]);
heapSize--;
maxHeapify(arrayA,);
}
}
结果:

堆排序HeapSort的更多相关文章
- 堆排序 Heapsort
Prime + Heap 简直神了 时间优化好多,顺便就把Heapsort给撸了一发 具体看图 Heapsort利用完全二叉树+大(小)顶锥的结构每次将锥定元素和锥最末尾的元素交换 同时大(小)顶锥元 ...
- 排序算法FOUR:堆排序HeapSort
/** *堆排序思路:O(nlogn) * 用最大堆,传入一个数组,先用数组建堆,维护堆的性质 * 再把第一个数与堆最后一个数调换,因为第一个数是最大的 * 把堆的大小减小一 * 再 在堆的大小上维护 ...
- 算法分析-堆排序 HeapSort 优先级队列
堆排序的是集合了插入排序的单数组操作,又有归并排序的时间复杂度,完美的结合了2者的优点. 堆的定义 n个元素的序列{k1,k2,…,kn}当且仅当满足下列关系之一时,称之为堆. 情形1:ki < ...
- 堆排序——HeapSort
基本思想: 图示: (88,85,83,73,72,60,57,48,42,6) 平均时间复杂度: O(NlogN)由于每次重新恢复堆的时间复杂度为O(logN),共N - 1次重新恢复堆操作 ...
- 堆排序Heapsort的Java和C代码
Heapsort排序思路 将整个数组看作一个二叉树heap, 下标0为堆顶层, 下标1, 2为次顶层, 然后每层就是"3,4,5,6", "7, 8, 9, 10, 11 ...
- 堆排序与优先队列——算法导论(7)
1. 预备知识 (1) 基本概念 如图,(二叉)堆是一个数组,它可以被看成一个近似的完全二叉树.树中的每一个结点对应数组中的一个元素.除了最底层外,该树是完全充满的,而且从左向右填充.堆的数组 ...
- 堆排序算法 java 实现
堆排序算法 java 实现 白话经典算法系列之七 堆与堆排序 Java排序算法(三):堆排序 算法概念 堆排序(HeapSort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,可以利用数组的特 ...
- 排序 选择排序&&堆排序
选择排序&&堆排序 1.选择排序: 介绍:选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理如下.首先在未排序序列中找到最小(大)元素,存放到排序序列的起始 ...
- 排序算法——QuickSort、MergeSort、HeapSort(C++实现)
快速排序QuickSort template <class Item> void quickSort (Item a[], int l, int r) { if (r<=l) ret ...
随机推荐
- Java 浅拷贝和深拷贝的理解和实现方式
Java中的对象拷贝(Object Copy)指的是将一个对象的所有属性(成员变量)拷贝到另一个有着相同类类型的对象中去.举例说明:比如,对象A和对象B都属于类S,具有属性a和b.那么对对象A进行拷贝 ...
- WPF 快捷方式
http://www.cnblogs.com/gnielee/archive/2010/07/16/wpf-custom-hotkey-command.html
- django中间件Middleware
熟悉web开发的同学对hook钩子肯定不陌生,通过钩子可以方便的实现一些触发和回调,并且做一些过滤和拦截. django中的中间件(middleware)就是类似钩子的一种存在.下面我们来介绍一下,并 ...
- canvas图表详解系列(4):动态散点图
本章建议学习时间4小时 学习方式:详细阅读,并手动实现相关代码(如果没有canvas基础,需要先学习前面的canvas基础笔记) 学习目标:此教程将教会大家如何使用canvas绘制各种图表,详细分解步 ...
- JavaScript观察者模式
观察者模式观察者模式又叫发布订阅模式(Publish/Subscribe),它定义了一种一对多的关系,让多个观察者对象同时监听某一个主题对象,这个主题对象的状态发生变化时就会通知所有的观察者对象,使得 ...
- Linux 进程状态 概念 Process State Definition
From : http://www.linfo.org/process_state.html 进程状态是指在进程描述符中状态位的值. 进程,也可被称为任务,是指一个程序运行的实例. 一个进程描述符是一 ...
- uva1629,Cake Slicing,记忆化搜索
同上个题一样,代码相似度极高,或者说可以直接用一个模板吧 dp[i,j,p,q]表示一块长为j-i+1,宽为q-p+1,左上角在位置(i,j)上的蛋糕,dp[]表示当前状态下的最优值,然后对该块蛋糕枚 ...
- PLSQL Developer oracle导入导出表及数据
1.进入PLSQL Developer 2.创建新用户(如需要新表空间则需先创建新表空间再创建用户) 3.打开菜单Tools->Export User Objects 导出表及视图等创建SQL ...
- linux下svn的安装与配置
---恢复内容开始--- linux下svn的安装与配置 Linux发行版本:CentOS6.5 1.安装subversion sudo yum -y install subversion 2.创建s ...
- JAVA提高八:动态代理技术
对于动态代理,学过AOP的应该都不会陌生,因为代理是实现AOP功能的核心和关键技术.那么今天我们将开始动态代理的学习: 一.引出动态代理 生活中代理应该是很常见的,比如你可以通过代理商去买电脑,也可以 ...