Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化
本文提要
从编码角度来优化数据层的话,我首先会去查一下项目中运行的sql语句,定位到瓶颈是否出现在这里,首先去优化sql语句,而慢sql就是其中的主要优化对象,对于慢sql,顾名思义就是花费较多执行时间的语句,它带来的影响也比较恶劣,首先是执行时间过长影响数据的返回速度,其次,慢sql的长时间执行也会消耗和占用mysql的系统资源,影响其他的sql语句执行,过多的慢sql极其影响性能,如果系统流量或者并发量较大的情况下,过多的执行慢sql很有可能造成mysql的死锁以致于mysql服务无法正常使用。
druid整合到项目中以及druid监控的开启已经持续了一段时间,因此对于慢sql的监控和整理也大致有了一些结果,本篇文章就试着从日志文件和监控面板中找出几条慢sql并进行优化。
优化步骤
总结了一下,大致步骤如下:
- 定位优化对象的性能瓶颈;
- 明确优化目标;
- 从explain入手分析;
- 找到优化方法;
找出慢sql
首先进入druid监控后台,查看一下这几天的运行日志后,慢sql的大致情况,如图:
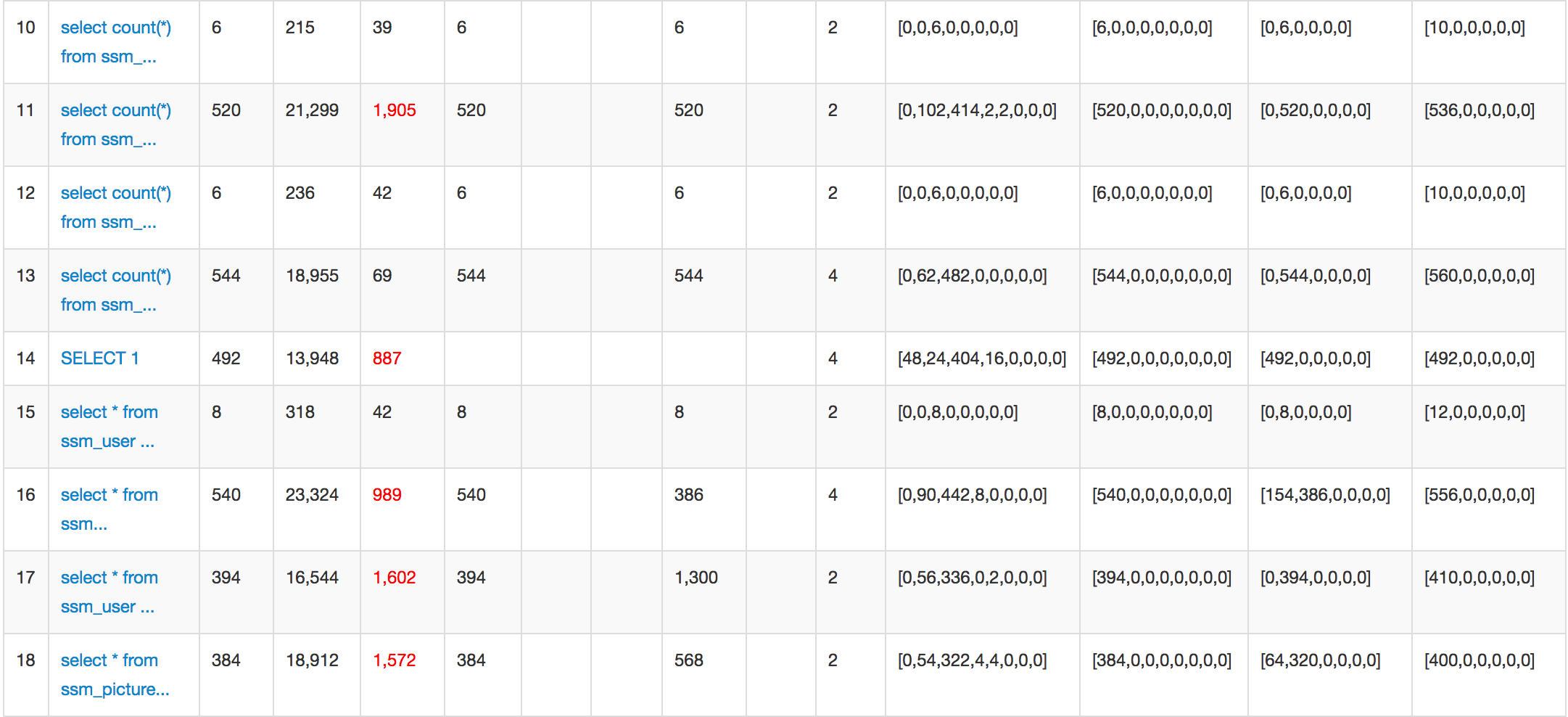
从监控后台看到的数据只是一个粗略的统计,是一个总览记录,想要看到详细的执行记录及其中的慢sql统计可以通过日志文件,这个功能也已经整合到项目中,直接在tomcat的logs目录即可查看。
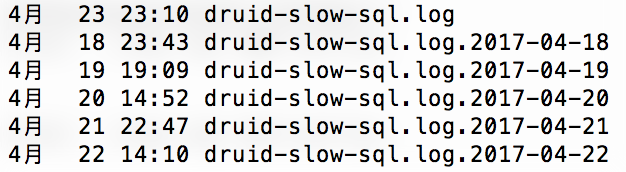
日志文件内容节选:
//1.图片表查询sql
[10:13:37] StatFilter - slow sql 1572 millis.
select * from ssm_picture
WHERE type = ? and grade = ?
limit ?,?
["1","1",0,10]
...
//2.更新文章表sql
[14:19:12] StatFilter - slow sql 1926 millis.
update ssm_article
set
article_title=?,article_content=?,
add_name=?
where id=?
["11","<p>1324354657usdfghjnkm,zxvb nm,,fgfhjtfggggggggggggggggggg<br/></p>","22","1033"]
...
//3.文章表查询sql
[15:07:04] StatFilter - slow sql 1672 millis.
select * from ssm_article
limit ?,?
[0,10]
日志的记录格式为 [执行时间] -慢sql执行耗时 ,sql语句,其实日志中记录是挺多的,去重之后从日志文件中单独选了几条比较典型的sql语句进行优化。
explain关键字
explain关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作、以及MySQL成功返回结果集需要执行的行数。explain 可以帮助我们分析 select 语句,让我们知道查询效率低下的原因,从而改进我们查询,让查询优化器能够更好的工作。
用法:

结果集说明如下:
| 项 | 说明 |
|---|---|
| id | MySQL Query Optimizer选定的执行计划中查询的序列号。表示查询中执行select子句或操作表的顺序,id值越大优先级越高,越先被执行。id相同,执行顺序由上至下。 |
| select_type 查询类型 | 说明 |
|---|---|
| SIMPLE | 简单的select查询,不使用union及子查询。 |
| PRIMARY | 最外层的select查询。 |
| UNION | UNION 中的第二个或随后的 select查询,不依赖于外部查询的结果集。 |
| DEPENDENT UNION | UNION中的第二个或随后的 select查询,依 赖于外部查询的结果集。 |
| SUBQUERY | 子查询中的第一个select查询,不依赖于外部查询的结果集。 |
| DEPENDENT SUBQUERY | 子查询中的第一个select查询,依赖于外部查询的结果集。 |
| DERIVED | 用于from子句里有子查询的情况。MySQL会递归执行这些子查询,把结果放在临时表里。 |
| UNCACHEABLE SUBQUERY | 结果集不能被缓存的子查询,必须重新为外层查询的每一行进行评估。 |
| UNCACHEABLE UNION | UNION中的第二个或随后的select查询,属于不可缓存的子查询。 |
| 项 | 说明 |
|---|---|
| table | 输出行所引用的表 |
| type 显示连接使用的类型,按最优到最差的类型排序 | 说明 |
|---|---|
| system | 表仅有一行(=系统表)。这是const连接类型的一个特例。 |
| const | const用于用常数值比较PRIMARY KEY时。当查询的表仅有一行时,使用System。 |
| eq_ref | const用于用常数值比较PRIMARY KEY时。当查询的表仅有一行时,使用System。 |
| ref | 连接不能基于关键字选择单个行,可能查找到多个符合条件的行。叫做ref是因为索引要跟某个参考值相比较。这个参考值或者是一个常数,或者是来自一个表里的多表查询的结果值 |
| ref_or_null | 如同ref, 但是MySQL必须在初次查找的结果里找出null条目,然后进行二次查找。 |
| index_merge | 说明索引合并优化被使用了。 |
| unique_subquery | 在某些IN查询中使用此种类型,而不是常规的ref:value IN (SELECT primary_key FROM single_table WHERE some_expr) |
| index_subquery | 在某些IN查询中使用此种类型,与unique_subquery类似,但是查询的是非唯一性索引:value IN(SELECT key_column FROM single_table WHERE some_expr) |
| range | 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range。 |
| index | 全表扫描,只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序,但是开销仍然非常大。 |
| all | 最坏的情况,从头到尾全表扫描。 |
| 项 | 说明 |
|---|---|
| possible_keys | 指出MySQL能在该表中使用哪些索引有助于查询。如果为空,说明没有可用的索引。 |
| 项 | 说明 |
|---|---|
| key | MySQL实际从possible_key选择使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL 会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX (indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引 |
| 项 | 说明 |
|---|---|
| key_len | 使用的索引的长度。在不损失精确性的情况下,长度越短越好。 |
| 项 | 说明 |
|---|---|
| ref | 显示索引的哪一列被使用了 |
| 项 | 说明 |
|---|---|
| rows | MYSQL认为必须检查的用来返回请求数据的行数 |
extra 中出现以下2项意味着MYSQL根本不能使用索引,效率会受到重大影响。应尽可能对此进行优化。
| extra项 | 说明 |
|---|---|
| Using filesort | 表示MySQL会对结果使用一个外部索引排序,而不是从表里按索引次序读到相关内容。可能在内存或者磁盘上进行排序。MySQL中无法利用索引完成的排序操作称为“文件排序” |
| Using temporary | 表示MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询 group by。 |
优化目标
优化的目标是一定要明确的,不然根本无从下手,针对于前文中提到的sql语句,及explain关键字的解释,我列出了两条目标:
- 避免全表扫描
- rows参数尽量减小
至于为什么只列出这两条目标,主要是因为项目中并没有复杂的逻辑,也也没有复杂的查询,建表时也并没有根据相关查询创建索引,而且数据量也不大,因此能够优化的点并不是太多,即使做了优化也不能显著的提升速度及性能,因此就先列了两个简单的小目标,先体验一下explain关键字在sql优化中的作用。
优化
针对第2条更新文章sql,执行时间较长的原因主要是因为数据量太大,应该是一个朋友在测试的时候做的操作,article_content字段插入了一条20万字符大小的数据,因此,主要问题在于插入数据过大,代码已经更新了参数检查功能,在程序中做了限制。
对于另外两条查询语句,首先用explain分析sql语句,如下:


注意其中的两个参数,type都是all,rows较小,都为总记录,我们的两个目标是什么?type不能为all,rows尽量小,这里似乎满足了一个条件,其实不然,因为这两个表的数据量小,因此rows值也小,如果换一张表(book表较大),以相同格式执行一条sql得到如下结果:

rows为416,并没有因为使用了limit关键字而返回较小的值,因此两条sql都需要做一下简单的优化。
几张表都没有创建索引,是不是就没有索引了呢?其实不然,你可能忽略了一点,就是主键索引,索引的知识点在接下来一篇文章中会写,这一篇就简单的提一下,因此优化策略就是使用主键索引,将type由all变为index,稍微优化了一点点,改写后的sql语句如下,分析结果如下:

通过与上面的结果对比,可以看到rows值也变小了。


type由all全部变为index。
总结
由于项目比较简单,都是操作单表的sql语句,没有复杂查询,也没有多表的连接查询,速度提升并没有太多,对于目前的项目来说,不会有特别大的优化动作,如果以后有机会再去结合实际案例去优化,现在就点到为止了,这一篇主要是介绍一下druid监控的成果以及mysql查询优化的explain关键字,因此并没有做太多的案例及分析,只是做了一些小修改,使得大家对explain关键字有了一些了解,下一篇会继续做一些优化改动。
Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化的更多相关文章
- Spring+SpringMVC+MyBatis+easyUI整合基础篇(二)牛刀小试
承接上文,该篇即为项目整合的介绍了. 废话不多说,先把源码和项目地址放上来,重点要写在前面. github地址为ssm-demo 你也可以先体验一下实际效果,点击这里就行啦 账号:admin 密码:1 ...
- Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十五)阶段总结
作者:13 GitHub:https://github.com/ZHENFENG13 版权声明:本文为原创文章,未经允许不得转载. 一 每个阶段在结尾时都会有一个阶段总结,在<SSM整合基础篇& ...
- Spring+SpringMVC+MyBatis+easyUI整合基础篇
基础篇 Spring+SpringMVC+MyBatis+easyUI整合基础篇(一)项目简介 Spring+SpringMVC+MyBatis+easyUI整合基础篇(二)牛刀小试 Spring+S ...
- Spring+SpringMVC+MyBatis+easyUI整合进阶篇(六)一定要RESTful吗?
作者:13 GitHub:https://github.com/ZHENFENG13 版权声明:本文为原创文章,未经允许不得转载. 写在前面的话 这个问题看起来就显得有些萌,或者说类似的问题都有些不靠 ...
- 如约而至,Java 10 正式发布! Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十四)Redis缓存正确的使用姿势 努力的孩子运气不会太差,跌宕的人生定当更加精彩 优先队列详解(转载)
如约而至,Java 10 正式发布! 3 月 20 日,Oracle 宣布 Java 10 正式发布. 官方已提供下载:http://www.oracle.com/technetwork/java ...
- Spring+SpringMVC+MyBatis+easyUI整合基础篇(十二)阶段总结
不知不觉,已经到了基础篇的收尾阶段了,看着前面的十几篇文章,真的有点不敢相信,自己竟然真的坚持了下来,虽然过程中也有过懒散和焦虑,不过结果还是自己所希望的,克服了很多的问题,将自己的作品展现出来,也发 ...
- Spring+SpringMVC+MyBatis+easyUI整合基础篇(十一)SVN服务器进阶
日常啰嗦 上一篇文章<Spring+SpringMVC+MyBatis+easyUI整合基础篇(十)SVN搭建>简单的讲了一下SVN服务器的搭建,并没有详细的介绍配置文件及一些复杂的功能, ...
- Spring+SpringMVC+MyBatis+easyUI整合基础篇(六)maven整合SSM
写在前面的话 承接前文<Spring+SpringMVC+MyBatis+easyUI整合基础篇(五)讲一下maven>,本篇所讲述的是如何使用maven与原ssm项目整合,使得一个普 ...
- Spring+SpringMVC+MyBatis+easyUI整合基础篇(八)mysql中文查询bug修复
写在前面的话 在测试搜索时出现的问题,mysql通过中文查询条件搜索不出数据,但是英文和数字可以搜索到记录,中文无返回记录.本文就是写一下发现问题的过程及解决方法.此bug在第一个项目中点这里还存在, ...
- Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十一)redis密码设置、安全设置
警惕 前一篇文章<Spring+SpringMVC+MyBatis+easyUI整合进阶篇(九)Linux下安装redis及redis的常用命令和操作>主要是一个简单的介绍,针对redis ...
随机推荐
- 1715: [Usaco2006 Dec]Wormholes 虫洞
1715: [Usaco2006 Dec]Wormholes 虫洞 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 501 Solved: 278[Sub ...
- 通讯录--(iOS9独有的方法)
导入库文件 #import <ContactsUI/ContactsUI.h> #pragma mark iOS9 新出的点击通讯录的获取信息的办法 #pragma mark - 先弹 ...
- Android: DrawerLayout 侧滑菜单栏
DrawerLayout是SupportLibrary包中实现的侧滑菜单效果的控件. 分为主内容区域和侧边菜单区域 drawerLayout本身就支持:侧边菜单根据手势展开与隐藏, 开发者只需要实现: ...
- Archlinux中卸载 Slim
Slim 是图形登录器.最近停止更新了,据说在systemd中有兼容性问题. 卸载Slim的原因是某计算机使用的是AMD显卡的Catalyst驱动,图形驱动一旦出问题,Slim就无法启动,给维护造成困 ...
- Linux系统常用命令总结
1. 最关键的命令 manecho 2. 目录文件操作命令 ls: 查看目录下的文件信息或文件信息dir:pwd: 打印当前路径cd:改变路径mkdir:创建路径rmdir:删除路径cp:拷贝文件或目 ...
- ajax(20161110)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- mybatis的学习笔记
前几天学习了mybatis,今天来复习一下它的内容. mybatis是一个基于Java的持久层框架,那就涉及到数据库的操作.首先来提出第一个问题:java有jdbc连接数据库,我们为什么还要使用框架呢 ...
- js原生API----查找dom
一.祖先接口Node,及他的扩展接口EventTarget Node是一个接口,许多DOM类型从这个接口继承,并允许类似地处理(或测试)这些各种类型. 以下接口都从Node继承其方法和属性: Docu ...
- 储存过程嵌套临时表同名引发的BUG?
临时表使用:存储过程嵌套时,均创建了相同名称的临时表. create procedure SP_A ( @i int output )asbegin create table #t ( ta int ...
- java.sql.SQLException: Value '0000-00-00 00:00:00' can not be represented as java.sql.Timestamp
下面是我查询数据库时打印出来的异常信息: ### Error querying database. Cause: java.sql.SQLException: Value '0000-00-00 0 ...