数学建模:1.概述& 监督学习--回归分析模型
数学建模概述
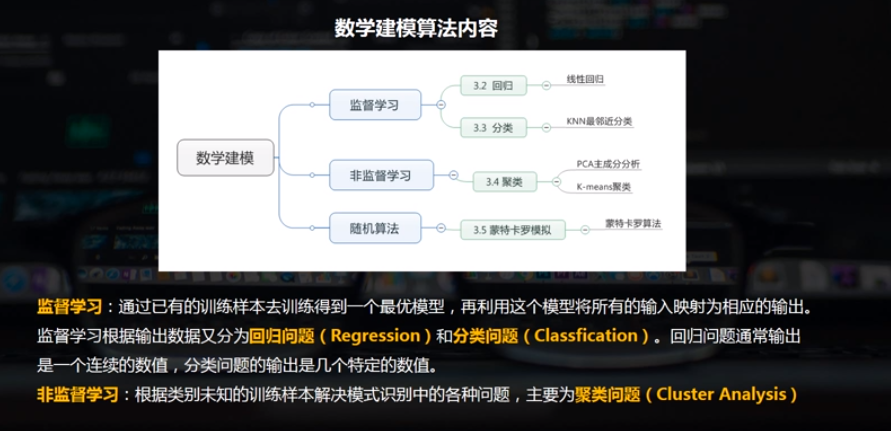
1.回归分析
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间互相依赖的定量关系的一种统计分析方法。
按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。



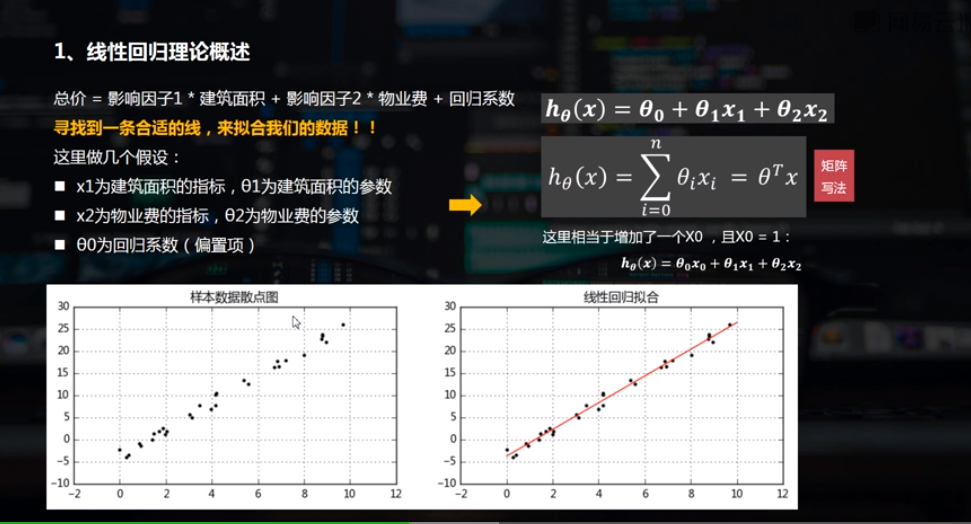

2.线性回归的python实现
线性回归的python实现方法
线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
简单线性回归 / 多元线性回归
2.1 简单线性回归 (一元线性回归)
(1)示例
创建线性回归模型:
model = LinearRegression()
model.fit(xtrain[:, np.newaxis], ytrain)
model.coef_斜率的参数 、 model.intercept_ 截距的参数
拟合测试:
xtest = np.linspace(0, 10, 1000) #测试值、根据拟合曲线求出 ytest = model.predict(xtest[:, np.newaxis])
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
# 简单线性回归(一元线性回归)
# (1)数据示例 from sklearn.linear_model import LinearRegression
# 导入线性回归模块 rng = np.random.RandomState(1) #选择随机数里边的种子1
xtrain = 10 * rng.rand(30)
ytrain = 8 + 4 * xtrain + rng.rand(30)
# np.random.RandomState → 随机数种子,对于一个随机数发生器,只要该种子(seed)相同,产生的随机数序列就是相同的
# 生成随机数据x与y
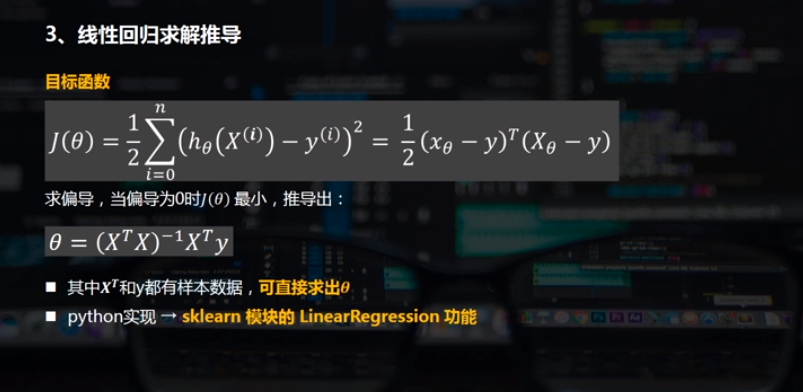
# 样本关系:y = 8 + 4*x fig = plt.figure(figsize =(12,3))
ax1 = fig.add_subplot(1,2,1)
plt.scatter(xtrain,ytrain,marker = '.',color = 'k')
plt.grid()
plt.title('样本数据散点图')
# 生成散点图 model = LinearRegression() #创建线性回归模型
model.fit(xtrain[:, np.newaxis], ytrain) #填上值自变量和因变量,如果是多元线性回归自变量给它个矩阵就可以了,model.fit(xtrain, ytrain)这样子是不行的,要把它转置为列的值,
# xtrain.shape #(30,) # xtrain[:, np.newaxis] #预测结果就会放到这个model里边
# LinearRegression → 线性回归评估器,用于拟合数据得到拟合直线
# model.fit(x,y) → 拟合直线,参数分别为x与y
# x[:,np.newaxis] → 将数组变成(n,1)形状 把xtrain数组变成列排布(30,1) #print(model.coef_) #[ 4.00448414]斜率的参数
#print(model.intercept_) #8.44765949943截距的参数 xtest = np.linspace(0, 10, 1000) #测试值
ytest = model.predict(xtest[:, np.newaxis])
# 创建测试数据xtest,并根据拟合曲线求出ytest
# model.predict → 预测 ax2 = fig.add_subplot(1, 2, 2)
plt.scatter(xtrain, ytrain, marker = '.', color = 'k')
plt.plot(xtest, ytest, color = 'r')
plt.grid()
plt.title('线性回归拟合')
# 绘制散点图、线性回归拟合直线
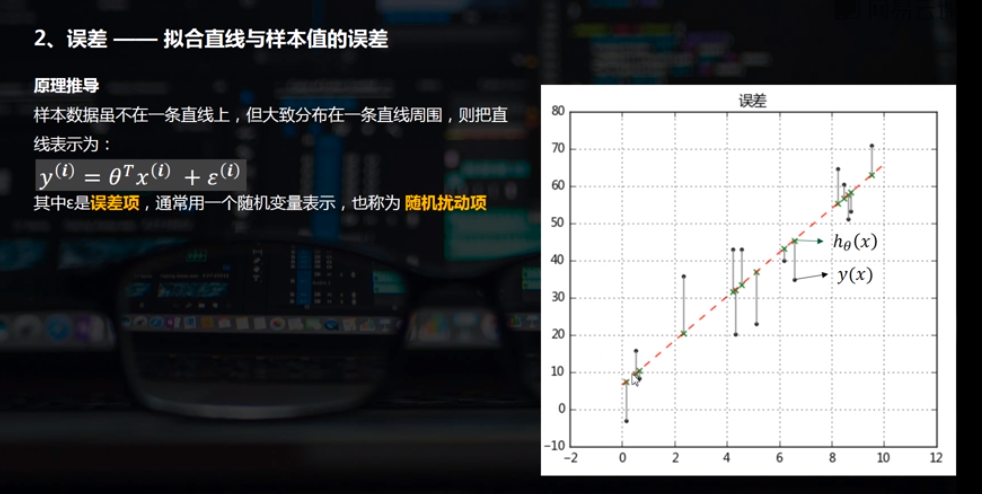
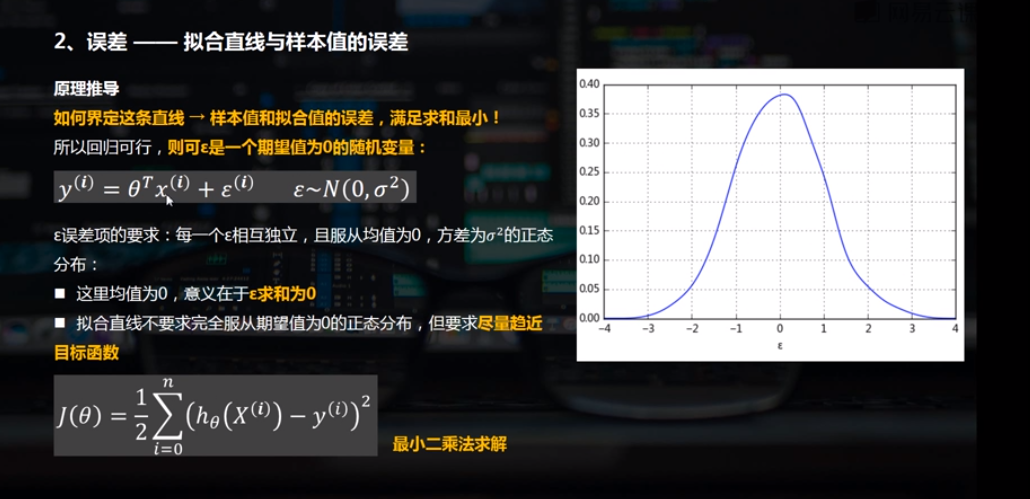
(2)误差
# 简单线性回归(一元线性回归)
# (2)误差 rng = np.random.RandomState(8)
xtrain = 10 * rng.rand(15)
ytrain = 8 + 4 * xtrain + rng.rand(15) * 30
model.fit(xtrain[:,np.newaxis],ytrain)
xtest = np.linspace(0,10,1000)
ytest = model.predict(xtest[:,np.newaxis])
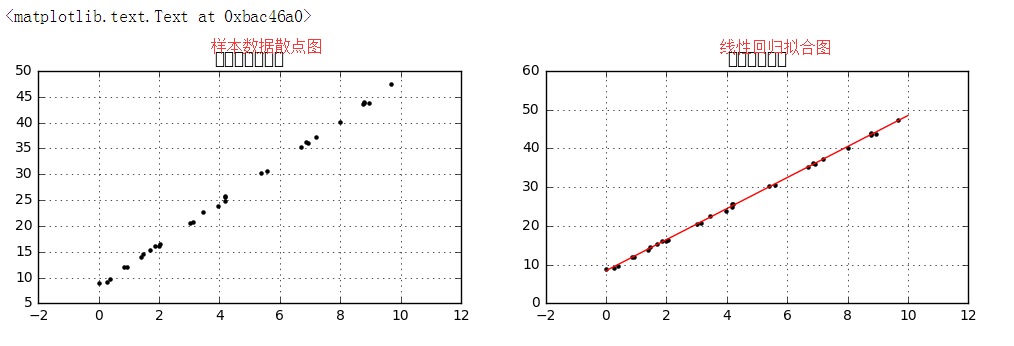
# 创建样本数据并进行拟合 plt.plot(xtest,ytest,color = 'r',linestyle = '--') # 拟合直线
plt.scatter(xtrain,ytrain,marker = '.',color = 'k') # 样本数据散点图
ytest2 = model.predict(xtrain[:,np.newaxis]) # 样本数据x在拟合直线上的y值
plt.scatter(xtrain,ytest2,marker = 'x',color = 'g') # ytest2散点图
plt.plot([xtrain,xtrain],[ytrain,ytest2],color = 'gray') # 误差线
plt.grid()
plt.title('误差')
# 绘制图表
(3)求解a,b
# 简单线性回归(一元线性回归)
# (3)求解a,b rng = np.random.RandomState(1)
xtrain = 10 * rng.rand(30)
ytrain = 8 + 4 * xtrain + rng.rand(30)
# 创建数据 model = LinearRegression()
model.fit(xtrain[:,np.newaxis],ytrain)
# 回归拟合 print('斜率a为:%.4f' % model.coef_[0])
print('截距b为:%.4f' % model.intercept_)
print('线性回归函数为:\ny = %.4fx + %.4f' % (model.coef_[0],model.intercept_))
# 参数输出

2.2 多元线性回归
model = LinearRegression()
model.fit(df[['b1', 'b2', 'b3', 'b4']], df['y'])
# 多元线性回归 rng = np.random.RandomState(5)
xtrain = 10 * rng.rand(150,4)
ytrain = 20 + np.dot(xtrain ,[1.5,2,-4,3])
df = pd.DataFrame(xtrain, columns = ['b1','b2','b3','b4'])
df['y'] = ytrain
pd.scatter_matrix(df[['b1','b2','b3','b4']],figsize=(10,6),
diagonal='kde',
alpha = 0.5,
range_padding=0.1)
print(df.head())
# 创建数据,其中包括4个自变量
# 4个变量相互独立 model = LinearRegression()
model.fit(df[['b1', 'b2', 'b3', 'b4']], df['y'])
print('斜率a为:', model.coef_)
print('线性回归函数为:\ny = %.1fx1 + %.1fx2 + %.1fx3 + %.1fx4 + %.1f'
% (model.coef_[0],model.coef_[1],model.coef_[2],model.coef_[3],model.intercept_))
# 参数输出

3. 线性回归模型评估
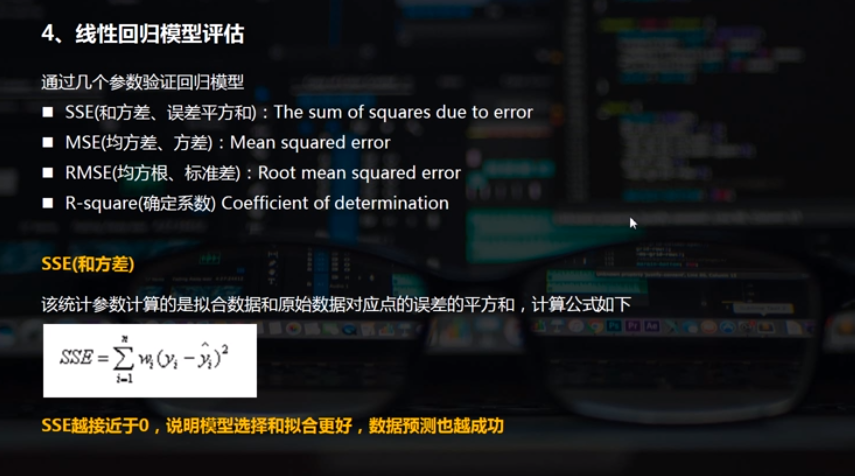


线性回归模型评估
通过几个参数验证回归模型
SSE(和方差、误差平方和):The sum of squares due to error
MSE(均方差、方差):Mean squared error
RMSE(均方根、标准差):Root mean squared error
R-square(确定系数) Coefficient of determination
# 模型评价
# MSE, RMES, R-square from sklearn import metrics rng = np.random.RandomState(1)
xtrain = 10 * rng.rand(30)
ytrain = 8 + 4 * xtrain + rng.rand(30) * 3
# 创建数据 model = LinearRegression()
model.fit(xtrain[:,np.newaxis],ytrain)
# 多元回归拟合 ytest = model.predict(xtrain[:,np.newaxis]) # 求出预测数据
mse = metrics.mean_squared_error(ytrain,ytest) # 求出均方差MSE
rmse = np.sqrt(mse) # 求出均方根RMSE
print(mse)
print(rmse) # ssr = ((ytest - ytrain.mean())**2).sum() # 求出预测数据与原始数据均值之差的平方和
# sst = ((ytrain - ytrain.mean())**2).sum() # 求出原始数据和均值之差的平方和
# r2 = ssr / sst # 求出确定系数 #0.99464521596949995
r2 = model.score(xtrain[:,np.newaxis],ytrain) # 求出确定系数 #0.99464521596949995
r2 print("均方差MSE为: %.5f" % mse)
print("均方根RMSE为: %.5f" % rmse)
print("确定系数R-square为: %.5f" % r2)
# 确定系数R-square非常接近于1,线性回归模型拟合较好

总结:
能比较的有两个 R_square '确定系数' 、 MSE,
做两个回归模型可以分别判断哪个MSE更小就好,R哪个接近于1哪个就更好。如果只有一个回归模型,判断是否接近1,只要是大于0.6、0.8就非常不错了。同时在后边做组成成分,假如现在有10个参数,做一个回归模型,做一个R模型评估,比如说为0.85,把这10个参数降维,降维为3个主成分,再做一个3元的线性回归,这个叫回归模型2,为0.92,这个时候我们就选择那个3元的线性回归模型0.92更好,相互比较做出最优比较。
数学建模:1.概述& 监督学习--回归分析模型的更多相关文章
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 2017 年“认证杯”数学中国数学建模网络挑战赛 C题思路讲解
之前有小伙伴私信我叫我说说这次比赛C题的思路,怎么写的,我就写篇博客说说吧,仅供参考! 针对C题,该题目比较综合,是一个成熟的数模赛题,与国赛的相似性较高.一般而言,第一问难度较低,题目要求进行数据挖 ...
- “GANs”与“ODEs”:数学建模的终结?
在本文中,我想将经典数学建模和机器学习之间建立联系,它们以完全不同的方式模拟身边的对象和过程.虽然数学家基于他们的专业知识和对世界的理解来创建模型,而机器学习算法以某种隐蔽的不完全理解的方式描述世界, ...
- 【数学建模】day07-数理统计II
方差分析和回归分析. 用数理统计分析试验结果.鉴别各因素对结果影响程度的方法称为方差分析(Analysis Of Variance),记作 ANOVA. 比如:从用不同工艺制作成的灯泡中,各自抽取了若 ...
- MATLAB之数学建模:深圳市生活垃圾处理社会总成本分析
MATLAB之数学建模:深圳市生活垃圾处理社会总成本分析 注:MATLAB版本--2016a,作图分析部分见<MATLAB之折线图.柱状图.饼图以及常用绘图技巧> 一.现状模式下的模型 % ...
- Matlab与数学建模
一.学习目标. (1)了解Matlab与数学建模竞赛的关系. (2)掌握Matlab数学建模的第一个小实例—评估股票价值与风险. (3)掌握Matlab数学建模的回归算法. 二.实例演练. 1.谈谈你 ...
- Python数学建模-01.新手必读
Python 完全可以满足数学建模的需要. Python 是数学建模的最佳选择之一,而且在其它工作中也无所不能. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数学 ...
- Python数学建模-02.数据导入
数据导入是所有数模编程的第一步,比你想象的更重要. 先要学会一种未必最佳,但是通用.安全.简单.好学的方法. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数据导入 ...
- Python小白的数学建模课-A1.2021年数维杯C题(运动会优化比赛模式探索)探讨
Python小白的数学建模课 A1-2021年数维杯C题(运动会优化比赛模式探索)探讨. 运动会优化比赛模式问题,是公平分配问题 『Python小白的数学建模课 @ Youcans』带你从数模小白成为 ...
随机推荐
- Shiro配置URL过滤
常用过滤器: anon 不需要认证 authc 需要认证 user 验证通过或RememberMe登录的都可以 URL说明: /admin?=authc 表示 ...
- appium+java(四)微信公众号自动化测试实践
前言 随着手机阅读的普遍应用,微信公众号阅读,更为普遍,微信和qq一样,都是基于腾讯自研X5内核,不是google原生webview(其实就是进行了二次定制).实质上也是混合应用的一种,现在很多app ...
- [C]变量作用域
函数环境变量作用域 C语言栈环境变量作用域跟JS是类似的. 就是内部函数可以访问外部函数的执行(栈)环境变量. 当访问一个变量时,程序将会查询当前栈环境是否存在这个变量,如果没有,将会往上层栈环境继续 ...
- 用layui前端框架弹出form表单以及提交
第一步:引用两个文件 第二步:点击删除按钮弹出提示框 /*删除开始*/ $(".del").click(function () { var id = $(this).attr(&q ...
- windows 2012执行powershell脚本报错
使用powershell运行脚本报错:进行数字签名.无法在当前系统上运行该脚本.有关运行脚本和设置执行策略的详细信息 修复方法:powershell "Set-ExecutionPolicy ...
- Python-面向对象(组合、封装与多态)
一.组合 什么是组合? 就是一个类的属性 的类型 是另一个自定义类的 类型,也可以说是某一个对象拥有一个属性,该属性的值是另一个类的对象. 通过为某一个对象添加属性(这里的属性是另一个类的对象)的方式 ...
- MQ选型之RabbitMQ
RabbitMQ是部署最广泛的开源消息代理.[官方原话] 前言: MQ 是什么?队列是什么,MQ 我们可以理解为消息队列(message queue),队列我们可以理解为管道.以管道的方式做消息传递. ...
- log4j 知识点
什么是log4j? log4j 是一个帮助程序员将日志语句输出到各种输出目标的工具. log4j 包的设计使得日志语句可以保留在已发布的代码中,而不会产生高性能成本. log4j 使用分层记录器可以有 ...
- Confluence 6 外部小工具在其他应用中设置可信关系
为了在你的 Confluence 中与其他应用建立外部小工具,我们建议你在 2 个应用之间设置 OAuth 或者信任的应用连接关系.在这个例子中,外部应用为小工具的服务器(服务器提供者)和 Confl ...
- uva11426 欧拉函数应用,kuangbin的筛法模板
/* 给定n,对于所有的对(i,j),i<j,求出sum{gcd(i,j)} 有递推式sum[n]=sum[n-1]+f[n] 其中f[n]=gcd(1,n)+gcd(2,n)+gcd(3,n) ...