vue缓存页面【二】
keep-alive是vue内置的一个组件,可以使被它包含的组件处于保留状态,或避免被重新渲染。
用法:
运行结果描述:
input输入框内,路由切换输入框内部的内容不会发生改变。
在keep-alive标签内部添加
include:字符串或正则表达式。只有匹配的组件会被缓存
exclude: 字符串或正则表达式。任何匹配的组件都不会被缓存。

结合router缓存部分页面:
比较实用的例子:
思路:通过beforeRouterLeave这个钩子来对路由里面的keepAlive进行赋值。从而动态的确定A页面是否需要被缓存。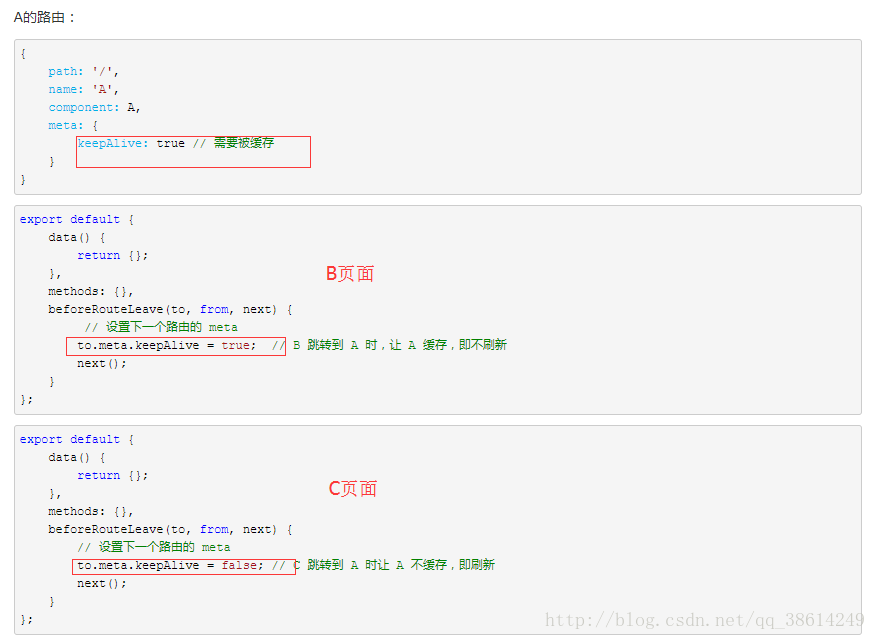
以上转载自:https://blog.csdn.net/qq_38614249/article/details/79468609
【Vue】Vue2.0页面缓存和不缓存的方法,以及watch监听会遇到的问题vue2.0页面
缓存和不缓存的方法:
1、在app中设置需要缓存的div
<keep-alive>//缓存的页面
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<router-view v-if="!$route.meta.keepAlive"></router-view>//不缓存的页面2、在路由router.js中设置.vue页面是否需要缓存
{
path: '/home',
component: home,
meta: { keepAlive: true },//当前的.vue文件需要缓存
},
{
path: '/notice',
component: notice,//当前页面不需要缓存
}3、从缓存页面跳转到不缓存页面,或者从不缓存页面跳转到缓存页面的时候,会发现watch是不能监听路由的,是因为缓存和不缓存页面分别在不同的div里面,一个div里面是不可能监听到另一个div的路由的,所有需要把监听的路由都加上缓存(在路由添加 meta: { keepAlive: true }),路由在缓存页面之间进行跳转的时候,就可以通过监听路由来进行判断数据是否需要更新。vue中前进刷新、后退缓存用户浏览数据和浏览位置的实践
vue中,我们所要实现的一个场景就是:
1.搜索页面==>到搜索结果页时,搜索结果页面要重新获取数据,
2.搜索结果页面==>点击进入详情页==>从详情页返回列表页时,要保存上次已经加载的数据和自动还原上次的浏览位置。
最近在项目中遇到这个问题,思考了几套方案,总是不太完善。百度搜到的方案也基本都只能满足一些很简单的需求。对于复杂一些的情况,还是有些不完善的地方。以下是个人对于这种场景的一个摸索,也参考了百度。如有更好的方案,欢迎指出。
缓存组件,vue2中提供了keep-alive。首先在我们的app.vue中定义keep-alive:
<keep-alive>
<router-view v-if="$route.meta.keepAlive"/>
</keep-alive>
<router-view v-if="!$route.meta.keepAlive"/>这里是根据路由中的meta源信息中的keepAlive字段来判断当前路由组件是否需要缓存。这里的meta的keepAlive是我们自定义的,当然你也可以叫别的名字。
下面在router/index.js即我们的路由文件中,定义meta信息:
// list是我们的搜索结果页面
{
path: '/list',
name: 'List',
component: resolve => require(['@/pages/list'], resolve),
meta: {
isUseCache: false, // 这个字段的意思稍后再说
keepAlive: true // 通过此字段判断是否需要缓存当前组件
}
},上面的component: resolve => require(['@/pages/list'], resolve)这里的组件引入方式可能和大家平时写的有些不一样,这里是为了路由的懒加载用的,大家可以忽略。按照正常的import引入也可以,这个和本次的主题无关。如此一来,vue的路由会帮我们去缓存list页面。
刷新数据or缓存数据的实现:
说这之前,先简单说一下和缓存相关的vue钩子函数。
设置了keepAlive缓存的组件:
第一次进入:beforeRouterEnter ->created->…->activated->…->deactivated
后续进入时:beforeRouterEnter ->activated->deactivated可以看出,只有第一次进入该组件时,才会走created钩子,而需要缓存的组件中activated是每次都会走的钩子函数。所以,我们要在这个钩子里面去判断,当前组件是需要使用缓存的数据还是重新刷新获取数据。思路有了,下面我们来实现:
// list组价的activated钩子
activated() {
// isUseCache为false时才重新刷新获取数据
// 因为对list使用keep-alive来缓存组件,所以默认是会使用缓存数据的
if(!this.$route.meta.isUseCache){
this.list = []; // 清空原有数据
this.onLoad(); // 这是我们获取数据的函数
}
},这里的isUseCache 其实就是我们用来判断是否需要使用缓存数据的字段,我们在list的路由的meta中已经默认设置为false,所以第一次进入list时是获取数据的。
当我们从详情页返回时,我们把list页面路由的isUseCache设置成true,这样我们在返回list页面时会使用缓存数据:
// 详情页面的beforeRouteLeave钩子函数
beforeRouteLeave (to, from, next) {
if (to.name == 'List') {
to.meta.isUseCache = true;
}
next();
},我们这里是在即将离开detail页面前判断是否返回的列表页。如果是返回list页面,则把list页面路由的isUseCache字段设置成true。为什么这样设置呢?因为我们对list组件使用的keep-alive进行缓存组件,其默认就是使用缓存的。而我们又在list组件的actived钩子函数中进行了判断:只有在list页面的isUseCache==false时才会清空原有数据并重新获取数据。所以此处设置isUseCache为true,此时返会list页面是不会重新获取数据的,而是使用的缓存数据。
detail返回list可以缓存数据了,那么search前往list页面时怎么让list页面不使用缓存数据而是获取新数据呢?我们重新回到list的activated钩子中:
// list组价的activated钩子
activated() {
// isUseCache为false时才重新刷新获取数据
// 因为对list使用keep-alive来缓存组件,所以默认是会使用缓存数据的
if(!this.$route.meta.isUseCache){
this.list = []; // 清空原有数据
this.onLoad(); // 这是我们获取数据的函数
this.$route.meta.isUseCache = false; }
},我们加了一行this.$route.meta.isUseCache=false;也就是从detail返回list后,将list的isUseCache字段为false,而从detail返回list前,我们设置了list的isUseCache为true。所以,只有从detail返回list才使用缓存数据,而其他页面进入list是重新刷新数据的。
至此,一个前进刷新、后退返回的功能基本完成了。
如果场景再复杂一丢丢,比如,如果这个详情页是个订单详情,那么在订单详情页可能会有删除订单的操作。那么删除订单操作后会返回订单列表页,是需要列表页重新刷新的。那么我们需要此时在订单详情页进行是否要刷新的判断。简单改造一下详情页:
data () {
return {
isDel: false // 是否进行了删除订单的操作
}
},
beforeRouteLeave (to, from, next) {
if (to.name == 'List') {
// 根据是否删除了订单的状态,进行判断list是否需要使用缓存数据
to.meta.isUseCache = !this.isDel;
}
next();
},
methods: {
deleteOrder () {
// 这里是一些删除订单的操作
// 将状态变为已删除订单
// 所以beforeRouteLeave钩子中就会将list组件路由的isUseCache设置为false
// 所以此时再返回list时,list是会重新刷新数据的
this.isDel = true;
this.$router.go(-1)
}
}至此,算是解决了我的vue项目中的这个前进刷新、后退缓存数据和浏览位置的问题。
最后再提一下,页面滚动位置的问题。
问题1:我们知道,在vue这种单页应用中,如果你在a页面滚动了一段距离后,此时前往b页面后,b页面也会停留在a页面的滚动位置。这个问题的解决,我们可以利用router本身提供的功能来解决:
routes: [
{
path: '/detail',
name: 'Detail',
component: resolve => require(['@/pages/detail'], resolve)
}
],
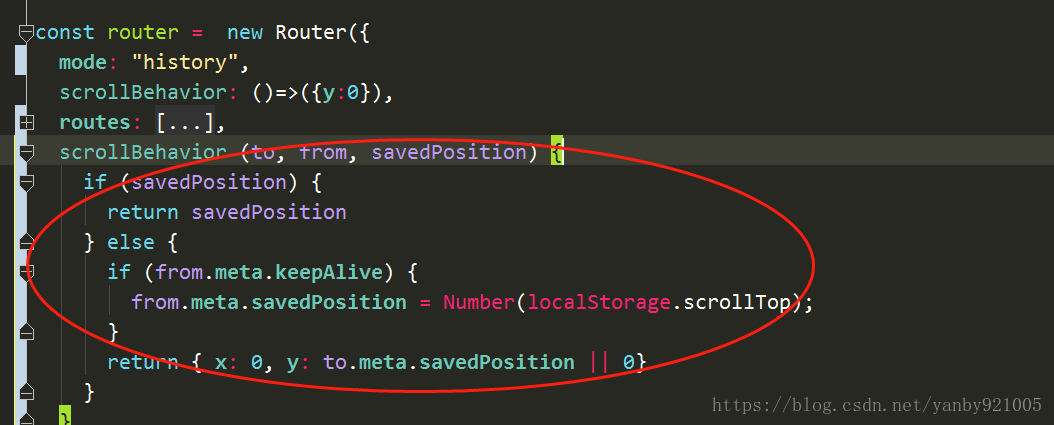
scrollBehavior (to, from, savedPosition) {
if (savedPosition) {
return savedPosition
} else {
if (from.meta.keepAlive) {
from.meta.savedPosition = document.body.scrollTop;
}
return { x: 0, y: to.meta.savedPosition || 0 }
}
}scrollBehavior是路由提供的基础功能,这段函数写的是:
1.如果通过浏览器自带的前进后退按钮切换的路由,那么会自动使用浏览默认的回滚上次页面的浏览位置。
2.如果是通过vue路由进行的页面切换。例如a前往b,首先判断a是不是通过keep-alive缓存的组件,如果是,则在a路由的meta中添加一个savedPosition字段,并且值为a的滚动位置。最后return的是页面需要回滚的位置。如此一来,如果打开一个页面,该页面的组件路由中meta.savedPosition为undefined的话,则页面滚动到(0,0)的位置,这样解决了问题1。那么如果打开一个页面,它的路由的meta.savedPosition有值的话,则滚动到上次浏览的位置,因为meta.savedPosition保存的就是上次浏览的位置。
vue中,在本地缓存中读写数据的方法
1.安装good-storage插件
cnpm i good-storage --save
2.读/写的方法
common/js/cache.js:
import storage from 'good-storage'
const SEARCH_KEY = '__search__'
const SEARCH_MAX_LENGTH = 15
// compare:findindex传入的是function,所以不能直接传val
function insertArray(arr, val, compare, maxLen) {
const index = arr.findIndex(compare)
if (index === 0) {
return
}
if (index > 0) {
arr.splice(index, 1)
}
arr.unshift(val) // 插入到数组最前
if (maxLen && arr.length > maxLen) {
arr.pop() // 删除末位元素
}
}
// 存储搜索历史
export function saveSearch(query) {
let searches = storage.get(SEARCH_KEY, [])
insertArray(searches, query, (item) => {
return item === query
}, SEARCH_MAX_LENGTH)
storage.set(SEARCH_KEY, searches)
return searches
}
// 加载本地缓存的搜索历史
export function loadSearch() {
return storage.get(SEARCH_KEY, [])
}3.数据用vuex传递
在store/actions.js中写入数据:
import * as types from './mutation-types'
import {saveSearch} from 'common/js/cache'
export const saveSearchHistory = function({commit, state}, query) {
commit(types.SET_SEARCH_HISTORY, saveSearch(query))
}4.组件中调用vuex
import {mapActions} from 'vuex'
// methods内:
saveSearch() {
this.saveSearchHistory(this.query)
},
...mapActions([
'saveSearchHistory'
])本文转载自:https://blog.csdn.net/qq_31393401/article/details/79299606
vue列表进入详情页面返回时数据缓存
1.在app.vue中添加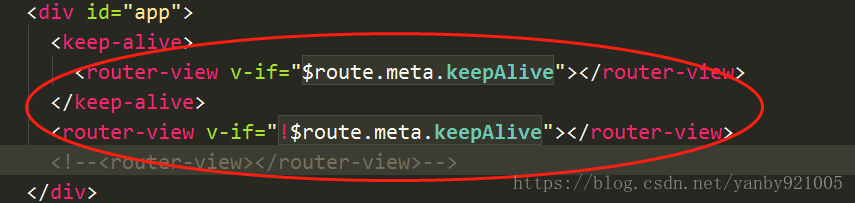
2.在router.index中添加
3.在列表页面添加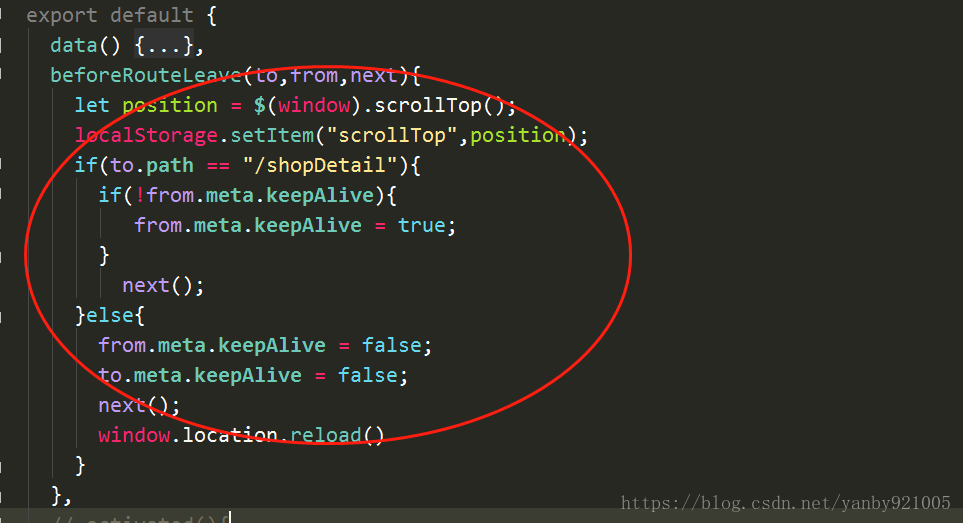
本文转载自:https://blog.csdn.net/yanby921005/article/details/80360822
vue.js生命周期钩子函数及缓存
在工作中用到最多的就是created,mounted,activated,deactivated.
由于系统需要缓存,使用了keep-alive
<keep-alive :include="/keepalive[a-zA-Z]+/">
<router-view></router-view>
</keep-alive>include 和 exclude 属性允许组件有条件地缓存。二者都可以用逗号分隔字符串或正则表达式来表示
匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称(父组件 components 选项的键值)。匿名组件不能被匹配。
//如果希望页面缓存,就在当前页的name属性,加上符合正则条件的name名称。不希望就加上不匹配的正则name名称。
created
实例已经创建完成之后被调用。在这一步,实例已完成以下的配置:数据观测(data observer),属性和方法的运算, watch/event 事件回调。然而,挂载阶段还没开始,$el 属性目前不可见。
//在刚进入页面的时候,会触发该函数的方法。只在页面刚开始加载时执行一次。
mounted
el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子。如果 root 实例挂载了一个文档内元素,当 mounted 被调用时 vm.$el 也在文档内。
该钩子在服务器端渲染期间不被调用。
//页面已经完成会执行该函数。
activated
keep-alive 组件激活时调用。
该钩子在服务器端渲染期间不被调用。
//当页面存在缓存的时候执行该函数。
deactivated
keep-alive 组件停用时调用。
该钩子在服务器端渲染期间不被调用。
//在页面结束时触发该方法,可清除掉滚动方法等缓存。
本文转载自:https://blog.csdn.net/stubbor/article/details/73739765
vue缓存页面【二】的更多相关文章
- vue缓存页面
vue如何和ionic的缓存机制一样,可以缓存页面,在A页面跳转至B页面后返回A页面时A页面的数据还在? 在app.vue中将router-view使用keep-alive包起来,使用v-if来判断使 ...
- vue缓存页面之后的生命周期
一:<router-view :key="key"></router-view> 没有作缓存时的状态 created :某单页面刚刚创建时候的回掉函数. m ...
- 六、vue如何缓存页面
vue如何和ionic的缓存机制一样,可以缓存页面,在A页面跳转至B页面后返回A页面时A页面的数据还在? 在app.vue中将router-view使用keep-alive包起来,使用v-if来判断使 ...
- VUE 多页面配置(二)
1. 概述 1.1 说明 项目开发过程中会遇到需要多个主页展示情况,故在vue单页面的基础上进行配置多页面开发以满足此需求,此记录为统一配置出入口. 2. 实例 2.1 页面配置 使用vue脚手架搭建 ...
- 关于vue里页面的缓存
keep-alive是vue内置的一个组件,可以使被它包含的组件处于保留状态,或避免被重新渲染. 用法: 运行结果描述: input输入框内,路由切换输入框内部的内容不会发生改变. 在keep-ali ...
- vue 缓存的keepalive页面刷新数据
用到这个的业务场景是这样的: a页面点击新建列表按钮进入到新建的页面b,填写b页面并点击b页面确认添加按钮,把这些数据带到a页面,填充到列表(数组),可以添加多条, 点击这条的时候进入到编辑页面,确认 ...
- Vue 缓存当前页面keep-alive
需求: 产品经理在列表页(几千个数据,n个page)点击某一项进去到详情页后,再返回到列表页发现页面回到了第一页,找不到之前的查看的是哪一条了,为了方便咋公司产品经理,返回列表页时需要记住之前的pag ...
- vue如何配置路由 、获取路由的参数、部分刷新页面、缓存页面
vue如何配置路由 .获取路由的参数.部分刷新页面.缓存页面:http://www.mamicode.com/info-detail-1941546.html vue-router传递参数的几种方式: ...
- Vue生命周期和钩子函数及使用keeplive缓存页面不重新加载
Vue生命周期 每个Vue实例在被创建之前都要经过一系列的初始化过程,这个过程就是vue的生命周期,在这个过程中会有一些钩子函数会得到回调 Vue中能够被网页直接使用的最小单位就是组件,我们经常写的: ...
随机推荐
- python中使用xlrd、xlwt和xlutils3操作Excel
简单试了下python下excel的操作,使用了xlrd.xlwt和xlutil3:xlrd可以实现excel的读取操作,xlwt则是写入excel操作,xlutils3主要是为了修改excel,简单 ...
- 解决:MVC对象转json包含\r \n
项目中对象转json字符串时,如下:JsonSerializerSettings jsetting = new JsonSerializerSettings(); jsetting.DefaultVa ...
- [NewLife.XCode]高级查询(化繁为简、分页提升性能)
NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量结合示例代码和 ...
- 函数式编程之-Currying
这个系列涉及到了F#这门语言,也许有的人觉得这样的语言遥不可及,的确我几乎花了2-3年的时间去了解他:也许有人觉得学习这样的冷门语言没有必要,我也赞同,那么我为什么要花时间去学习呢?作为一门在Tiob ...
- DocumentFragment对象
一般动态创建html元素都是创建好了直接appendChild()上去,但是如果要添加大量的元素还用这个方法的话就会导致大量的重绘以及回流,所以需要一个'缓存区'来保存创建的节点,然后再一次性添加到父 ...
- vue项目全局引入vue-awesome-swiper插件做出轮播效果
在安装了vue的前提下,打开命令行窗口,输入vue init webpack swiper-test,创建一个vue项目且名为swiper-test(创建速度可能会有点慢,耐心等),博文讲完后,源码托 ...
- 【学习笔记】node.js重构路由功能
摘要:利用node.js模块化实现路由功能,将请求路径作为参数传递给一个route函数,这个函数会根据参数调用一个方法,最后输出浏览器响应内容 1.介绍 node.js是一个基于Chrome V8引擎 ...
- linux磁盘管理增加,扩容
一.磁盘空间不足,添加新的磁盘 一般来说,当我们在服务上插入新的磁盘时,服务器是会对磁盘进行识别的.但是,有的时候服务器并没有对这些新插入的磁盘进行识别.这时,我们可以通过重启服务器,来使服务器重新加 ...
- 总结下Mysql分表分库的策略及应用
上月前面试某公司,对于mysql分表的思路,当时简要的说了下hash算法分表,以及discuz分表的思路,但是对于新增数据自增id存放的设计思想回答的不是很好(笔试+面试整个过程算是OK过了,因与个人 ...
- Java_冒泡排序_原理及优化
冒泡排序及其优化 一.原理及优化原理 1.原理讲解 冒泡排序即:第一个数与第二个数进行比较,如果满足条件位置不变,再把第二个数与第三个数进行比较.不满足条件则替换位置,再把第二个数与第三个数进行比较, ...