face detection[Multi-view face detection&& MTCNN]
因为这两篇论文感觉内容较短,故而合并到一个博文中。
Multi-view face detection
本文来自《Multi-view Face Detection Using Deep Convolutional Neural Networks》的解读。时间线是2015年4月。
本文考虑的是多角度的人脸检测问题。在当前已经有很多这方面的工作,而当前最好的方法都需要对人脸关键点进行标注,如TSM,或者需要对人脸姿态进行标注,同时还需要训练十几个模型,从而能够在所有方向上抓取所有的人脸,例如HeadHunter方法中需要22个模型。而本文提出深度密度人脸检测(deep dense face detector,DDFD),不需要姿态或者关键点标注,而且能够用一个单一的模型区抓取各个方向上的人脸。而且不需要额外的组件,比如分割,候选框回归,或者SVM分类器等等。此外,还分析了本文的方法:发现
- 1)所提出的方法能够从不同的角度检测面部,并且可以在一定程度上处理遮挡;
- 2)似乎训练集中正样本的分布与本文提出的人脸检测器的得分之间有一定相关性。
后者表明,通过使用更好的采样策略和更复杂的数据增强技术,可以进一步提高该模型的性能。
0.引言
2001年,Viola和Jones当初发明的级联人脸检测器,将人脸检测的速度大大提升,算是人脸发展史的一个里程碑。然而他们的方法却只能处理差不多是正脸且正向的人脸,而对不同方向不同姿态的人脸就没办法了。

对于这二十几年在多角度人脸检测上的工作,大致可以分成以下三个类别:
- 基于级联的:这些方法多是在Viola和Jones检测器上进行扩展;
- 基于DPM的:这些方法基于可变形部件模型,其中人脸被定义为不同部件的组合。 这些部件是通过无监督或有监督训练定义的,并且训练潜在SVM分类器以及这些部件之间的几何关系。 这些人脸检测器对部分遮挡是比较鲁棒,因为即使某些部件不存在,它们也可以探测到其他部件并组合成人脸。 然而,这些方法是计算密集型的
- 因为1)它们需要为每个候选位置求解潜在的SVM;
- 2)必须训练和组合多个DPM以实现最好的效果。 此外,在某些情况下,基于DPM的模型需要用于训练的人脸关键点标注数据:
- 基于神经网络的:使用神经网络来做人脸检测的历史也是挺长的。
多角度人脸检测中的难点是传统模型使用的特征不够鲁棒,不足以表征不同姿态的人脸,因此导致分类器也无法正确分类。然而随着DL的发展,这个问题被不断的逼近解决。本文提出的单一神经网络模型,就是不需要额外的关键点和姿态标注数据,且不需要引入额外的如SVM的分类器。
1. 本文方法
首先准备数据对AlexNet网络进行微调,然后通过对正样本进行裁剪然后使用IOU超过50%的作为正样本填充,并通过随机翻转等打到了一共200K个正样本和20百万个负样本。然后统一缩放到227x227,并用来微调一个经过预训练的Alexnet。然后作者采用了划窗的方法,不断的从输入图片中提取图片块,先经过Alexnet做特征映射,然后将全连接层reshape成二维的,再通过一个人脸分类器。该人脸分类器是由一个5层CNN+3层全连接层组成的网络。
ps:个人认为,就是不断的划窗,然后对一堆窗口进行分类是否是人脸,然后再进行NMS。
MTCNN
0 引言
MTCNN的灵感来自《A convolutional neural network cascade for face detection》,凯鹏认为,
- 该作者卷积层中的滤波器缺少多样化限制了模型的判别能力;
- 相比其他多累目标检测和分类任务,人脸检测就是一个极具挑战的二分类任务,所以每一层需要更少数量的滤波器。
所以凯鹏减少了滤波器的个数,并将5x5的大小变成3x3的大小,然后加深了网络的通道数量。
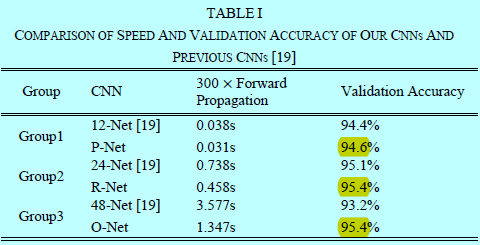
上图就是MTCNN的网络层与级联CNN的网络层的对比。
MTCNN主要贡献就是一个框架可以同时预测人脸区域并且同时预测人脸关键点,且能够在线进行硬样本的挖掘,从而提升性能。通过采用多任务学习将级联CNN进行统一起来,该提出的CNN框架中包含三个阶段:
- 通过一个浅层CNN快速的生成候选框;
- 然后通过一个更复杂的CNN拒绝大量的非人脸框;
- 最后使用一个更强劲的CNN去再次调整结果,并输出5个关键点位置。
1 结构
这里我们先给出MTCNN的操作流程图和对应的网络结构图

图1.1 MTCNN操作流程图
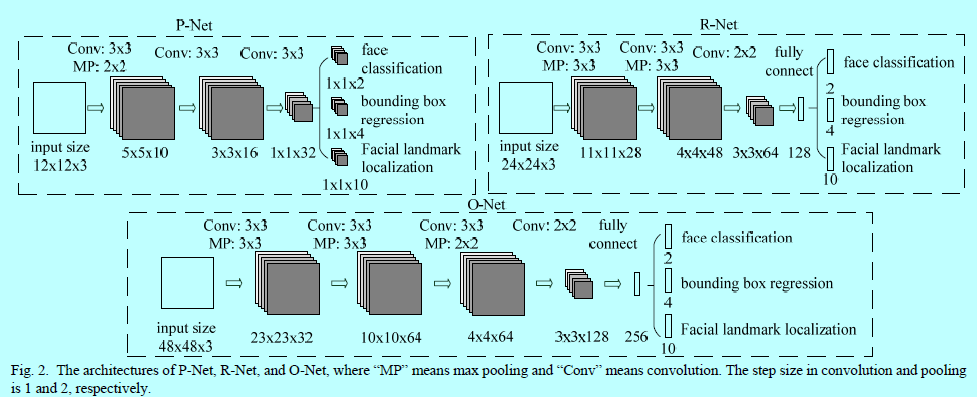
图1.2 MTCNN的网络结构图
如图1.1所示,给定一张图片,先对图片进行金字塔构建,保证整个网络结构的尺度不变性。
- 阶段1:利用一个全卷积网络,叫做proposal network(P-net),用于获取候选人脸窗口和他们的框回归向量。然后通过估计的边界框回归向量对候选框进行校正。然后用NMS来融合高度重叠的候选框。
- 阶段2:所有的候选框被送入另一个CNN中,叫做Refine Network(R-Net),该网络可以拒绝大量的假候选框,基于边界框回归进行校正,并执行NMS;
- 阶段3:该阶段相似于第二个阶段,但是在该阶段中,我们通过更多的有监督信息去识别人脸区域,最后,该网络会输出5个人脸关键点位置。
2 训练过程
MTCNN用了三个任务去训练整个CNN检测器:
- 是否是人脸的分类;
- 边界框的回归;
- 人脸关键点的定位。
2.1 人脸分类
这是一个二分类问题,那么采用交叉熵loss:
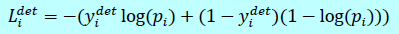
这里\(p_i\)是网络预测\(x_i\)是人脸的概率,其中\(y_j^{det}\in {0,1}\)是ground-truth
2.2 边界框回归
对每个候选框,都预测基于最近的ground truth的偏移量(边界框的【左上角的坐标,宽,高】四个量),这是一个回归问题,使用欧式距离:
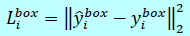
其中\(\hat y_j^{box}\)是网络预测的结果;\(y_i^{box}\)是ground-truth;
2.3 人脸关键点定位
和边界框回归任务一样,采用欧式距离进行回归

这里\(\hat y_i^{landmark}\)是人脸关键点的预测值;\(y_i^{landmark}\)是ground truth。
2.4 多源训练
因为在每个CNN中有不同的任务存在,所以这里在学习过程中也有不同类型的训练样本,比如人脸,非人脸,半对齐的人脸等等。这种情况下,上面三个公式在某些情况下就不能完全使用,比如对背景区域采用上,就只启动\(L_i^{det}\),并直接将其他两个loss置0。这是通过采用类型指示器完成的,如果将上述三个loss函数统一起来,就瑞下图:

这里\(N\)是样本个数,\(\alpha_j\)表示任务重要程度,这里使用的值是:
- 在P-net和R-net中:\(\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5\);
- 在O-net中:\(\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=1\)
其中\(\beta_j^j\in {0,1}\)是采样类型指示器。
2.5 在线硬样本挖掘
不同于传统的,基于原始分类器训练后的硬样本挖掘,这里使用的是在线硬样本挖掘。在每个mini-batch中,先基于所有样本前向一次,并计算loss值,然后进行排序,选择前70%的作为硬样本。这样只需要计算这部分硬样本的BP,不需要计算所有样本的BP。其内在含义就是,如果loss值小意味着当前样本拟合的不错了,就不需要训练了,主要就是关注分类严重错误的那些样本。
我们这里比较关心,通过图像金字塔对原图进行缩放之后,是如何经过整个Pnet,Rnet和Onet的,有两种方法:
- 图像金字塔只经过Pnet,然后进行融合结果;
- 每一个尺度的图像经过所有三个网络,然后最后再做结果融合。
这里我们调试了下pangyupo/mxnet_mtcnn_face_detection的代码。
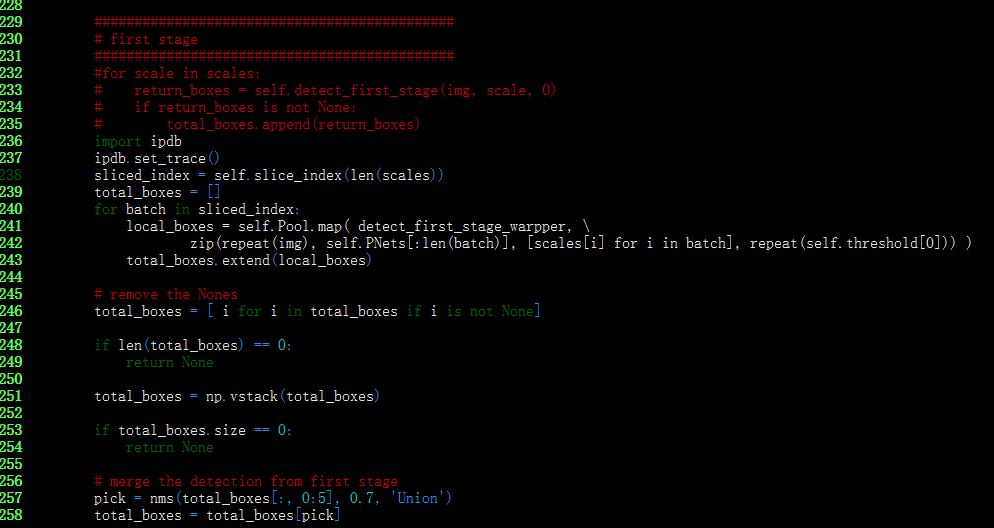



从上图可以知道,首先计算多个缩放因子,然后一个缩放因子对应一个进程进行处理,最后将结果通过除以缩放因子,将结果还原到scale=1的原图空间中。即图像金字塔只存在于Pnet过程中。
# https://github.com/pangyupo/mxnet_mtcnn_face_detection/blob/master/helper.py
def generate_bbox(map, reg, scale, threshold):
"""
generate bbox from feature map
Parameters:
----------
map: numpy array , n x m x 1
detect score for each position
reg: numpy array , n x m x 4
bbox
scale: float number
scale of this detection
threshold: float number
detect threshold
Returns:
-------
bbox array
"""
stride = 2
cellsize = 12
t_index = np.where(map>threshold)
# find nothing
if t_index[0].size == 0:
return np.array([])
dx1, dy1, dx2, dy2 = [reg[0, i, t_index[0], t_index[1]] for i in range(4)]
reg = np.array([dx1, dy1, dx2, dy2])
score = map[t_index[0], t_index[1]]
# 获取当前结果之后,通过下面的除以scale,将结果映射回scale=1的原图中。
boundingbox = np.vstack([np.round((stride*t_index[1]+1)/scale),
np.round((stride*t_index[0]+1)/scale),
np.round((stride*t_index[1]+1+cellsize)/scale),
np.round((stride*t_index[0]+1+cellsize)/scale),
score,
reg])
return boundingbox.T
def detect_first_stage(img, net, scale, threshold):
"""
run PNet for first stage
Parameters:
----------
img: numpy array, bgr order
input image
scale: float number
how much should the input image scale
net: PNet
worker
Returns:
-------
total_boxes : bboxes
"""
height, width, _ = img.shape
hs = int(math.ceil(height * scale))
ws = int(math.ceil(width * scale))
im_data = cv2.resize(img, (ws,hs)) # 基于缩放因子对图片进行缩放
# adjust for the network input
input_buf = adjust_input(im_data)
output = net.predict(input_buf) # 获取PNet网络的输出
'''添加如下代码
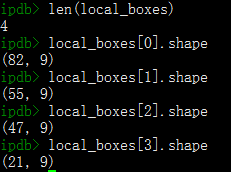
print(f'len(output):{len(output)} output[0].shape:{output[0].shape} output[1].shape:{output[1].shape}')
输出结果为(下面为4个进程的输出结果,对应4个不同的缩放因子):
# 第一个结果中的32 61 表示的是对应的划框map中的结果,即此缩放因子下一共有31x61个划框
len(output):2 output[0].shape:(1, 4, 32, 61) output[1].shape:(1, 2, 32, 61)
len(output):2 output[0].shape:(1, 4, 48, 88) output[1].shape:(1, 2, 48, 88)
len(output):2 output[0].shape:(1, 4, 69, 126) output[1].shape:(1, 2, 69, 126)
len(output):2 output[0].shape:(1, 4, 99, 179) output[1].shape:(1, 2, 99, 179)
通过shape的数量可以判定,P-Net只输出【边界框的四个预测值;是否有人脸的两个预测值】,并不输出对应的人脸关键点位置
然后通过下面的generate_bbox函数,带上缩放因子统一的将每个缩放因子结果再映射回原图中,从而完成图像金字塔的结果融合
'''
boxes = generate_bbox(output[1][0,1,:,:], output[0], scale, threshold)
if boxes.size == 0:
return None
# nms
pick = nms(boxes[:,0:5], 0.5, mode='Union')
boxes = boxes[pick]
return boxes
def detect_first_stage_warpper( args ):
return detect_first_stage(*args)
face detection[Multi-view face detection&& MTCNN]的更多相关文章
- Wordpress Calendar Event Multi View < 1.4.01 反射型xss漏洞(CVE-2021-24498)
简介 WordPress是Wordpress基金会的一套使用PHP语言开发的博客平台.该平台支持在PHP和MySQL的服务器上架设个人博客网站.WordPress 插件是WordPress开源的一个应 ...
- 【Detection】R-FCN: Object Detection via Region-based Fully Convolutional Networks论文分析
目录 0. Paper link 1. Overview 2. position-sensitive score maps 2.1 Background 2.2 position-sensitive ...
- Image Processing and Analysis_8_Edge Detection: Optimal edge detection in two-dimensional images ——1996
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- Image Processing and Analysis_8_Edge Detection:Multiresolution edge detection techniques ——1995
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- [读论文]Shading-aware multi view stereo
如何实现refine的? 几何误差和阴影误差如何加到一起? 为了解决什么问题? 弱纹理或无纹理:单纯的多视图立体算法在物体表面弱纹理或者无纹理区域重建完整度不够高,精度也不够高,因此结合阴影恢复形状来 ...
- 论文阅读:Review of Visual Saliency Detection with Comprehensive Information
这篇文章目前发表在arxiv,日期:20180309. 这是一篇针对多种综合性信息的视觉显著性检测的综述文章. 注:有些名词直接贴原文,是因为不翻译更容易理解.也不会逐字逐句都翻译,重要的肯定不会错过 ...
- Viola–Jones object detection framework--Rapid Object Detection using a Boosted Cascade of Simple Features中文翻译 及 matlab实现(见文末链接)
ACCEPTED CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION 2001 Rapid Object Detection using a B ...
- Isolation-based Anomaly Detection
Anomalies are data points that are few and different. As a result of these properties, we show that, ...
- PHP检测移动设备类mobile detection使用实例
目前,一个网站有多个版本是很正常的,如PC版,3G版,移动版等等.根据不同的浏览设备我们需要定向到不同的版本中.不仅如此,我们有时候还需要根据不同的客户端加载不同的CSS,因此我们需要能够检测浏览设备 ...
- Chrysler -- CCD (Chrysler Collision Detection) Data Bus
http://articles.mopar1973man.com/general-cummins/34-engine-system/81-ccd-data-bus CCD (Chrysler Coll ...
随机推荐
- Android string资源 包含 数学符号等特殊字符 及 参数占位符
定义:<?xml version="1.0" encoding="utf-8"?><resources> <string n ...
- (网页)input框怎么覆盖掉数字英文的
例子1: <input type="text" value="0" onkeyup="cleartwoNum(this)"> / ...
- PyCharm 在PyCharm中使用GitHub
PyCharm是当前进行Python开发,尤其是Django开发最好的IDE,GitHub是程序员的圣地,几乎人人都在用,就不详细介绍两者了. 本文假设你对PyCharm和Github都有一定的了解, ...
- spring4笔记----使用装配注入合作者Bean的三种方式
no :不自动装配 byName :id(name)与setter方法去set前缀,并小写首字母后同名的Bean完成注入,如有多个匹配则抛异常 byType :spring容器找全部bean,如果找到 ...
- MySQL高性能优化实战总结!
1.1 前言 MySQL对于很多Linux从业者而言,是一个非常棘手的问题,多数情况都是因为对数据库出现问题的情况和处理思路不清晰.在进行MySQL的优化之前必须要了解的就是MySQL的查询过程,很多 ...
- 修改Windows默认远程端口号
1.定位注册表,[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server\Wds\rdpwd\Tds\tcp],右侧修改 ...
- LeetCode算法题-Ugly Number(Java实现-四种解法)
这是悦乐书的第199次更新,第208篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第64题(顺位题号是263).编写一个程序来检查给定的数字是否是一个丑陋的数字.丑陋的数 ...
- Tomcat结构
Tomcat结构 Server(服务器) 服务器代表整个Tomcat容器. Tomcat提供了服务器接口的默认实现(很少由用户定制). Service(服务) 服务是位于服务器内部的中间组件,将一个或 ...
- DB2常见错误信息
000 00000 SQL语句成功完成01xxx SQL语句成功完成,但是有警告+012 01545 未限定的列名被解释为一个有相互联系的引用+098 01568 动态SQL语句用分号结束+100 0 ...
- inline-block,一个奇怪的问题:中间div掉下来
先上代码: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <tit ...