Storm知识点

1. 离线计算是什么?
2. 流式计算是什么?
3. storm核心组件和架构?
- 核心组件
- 架构
4. 并发度
5. Storm运行模式
6. Storm常见的分组策略
7. Storm操作命令
- 任务提交命令:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
storm jar /export/servers/storm/examples/storm-starter/storm-starter-topologies-1.0.3.jar org.apache.storm.starter.WordCountTopology wordcount
hadoop jar /usr/local/wordcount.jar /data.txt /wcout
- 杀死任务命令:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
- 停用任务命令:storm deactive 【拓扑名称】
storm deactive topology-name
- 启用任务命令:storm activate 【拓扑名称】
storm activate topology-name
- 重新部署任务命令:storm rebalance 【拓扑名称】
storm rebalance topology-name
- Spout创建一个新的Tuple时,会发一个消息通知acker去跟踪;
- Bolt在处理Tuple成功或失败后,也会发一个消息通知acker;
- acker会找到发射该Tuple的Spout,回调其ack或fail方法。
//BaseBasicBolt 实现可靠消息传递
public class SplitSentence extends BaseBasicBolt {//自动建立 anchor,自动 ack
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
//BaseRichBolt 实现可靠消息传递
public class SplitSentence extends BaseRichBolt {//建立 anchor 树以及手动 ack 的例子
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word)); // 建立 anchor 树
}
_collector.ack(tuple); //手动 ack,如果想让 Spout 重发该 Tuple,则调用 _collector.fail(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
9. 调整可靠性
- 在build topology时,设置acker数目为0,即conf.setNumAckers(0);
- 在Spout中,不指定messageId,使得Storm无法追踪;
- 在Bolt中,使用Unanchor方式发射新的Tuple。
10. Jstorm查看CPU核数
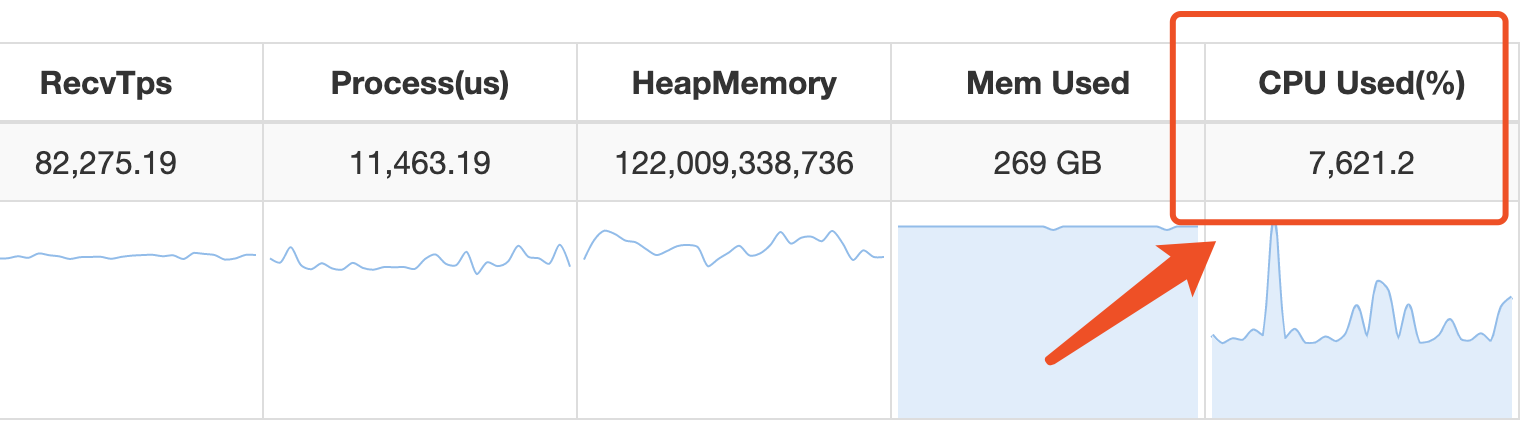
11. Jstorm消费kakfa单条数据太大起Lag
Kafka spoutConfig.fetchSizeBytes = ;
Kafka spoutConfig.bufferSizeBytes = ;
Storm知识点的更多相关文章
- Storm知识点笔记
Spark和Storm Spark基于MapReduce算法实现的分布式计算,不同于MapReduce的是,作业中间结果可以保存在内存中,而不要再读写HDFS, Spark适用于数据挖掘和机器学习等需 ...
- [大数据面试题]storm核心知识点
1.storm基本架构 storm的主从分别为Nimbus.Supervisor,工作进程为Worker. 2.计算模型 Storm的计算模型分为Spout和Bolt,Spout作为管口.Bolt作为 ...
- 初版storm项目全流程自动化测试代码实现
由于项目需要,写了版针对业务的自动化测试代码,主要应用场景在于由于业务日趋复杂,一些公共代码的改动,担心会影响已有业务.还没进行重写,但知识点还是不少的与大家分享实践下.首先,介绍下整个流处理的业务流 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- Hadoop storm大数据分析 知识体系结构
最近工作工作有用到hadoop 和storm,最近看到一个网站上例句的hadoop 和storm的知识体系.所以列出来供大家了解和学习.来自哪个网站就不写了以免以为我做广告额. 目录结构知识点还是挺全 ...
- Storm系列二: Storm拓扑设计
Storm系列二: Storm拓扑设计 在本篇中,我们就来根据一个案例,看看如何去设计一个拓扑, 如何分解问题以适应Storm架构,同时对Storm拓扑内部的并行机制会有一个基本的了解. 本章代码都在 ...
- mysql常见知识点总结
mysql常见知识点总结 参考: http://www.cnblogs.com/hongfei/archive/2012/10/20/2732516.html https://www.cnblogs. ...
- 牛客网Java刷题知识点之Java 集合框架的构成、集合框架中的迭代器Iterator、集合框架中的集合接口Collection(List和Set)、集合框架中的Map集合
不多说,直接上干货! 集合框架中包含了大量集合接口.这些接口的实现类和操作它们的算法. 集合容器因为内部的数据结构不同,有多种具体容器. 不断的向上抽取,就形成了集合框架. Map是一次添加一对元素. ...
随机推荐
- Python模块之信号(signal)
在了解了Linux的信号基础之 后,Python标准库中的signal包就很容易学习和理解.signal包负责在Python程序内部处理信号,典型的操作包括预设信号处理函数,暂 停并等待信号,以及定时 ...
- Linux查看机器的硬件信息
转载:https://linux.cn/article-9932-1.html
- Python 基于Python从mysql表读取千万数据实践
基于Python 从mysql表读取千万数据实践 by:授客 QQ:1033553122 场景: 有以下两个表,两者都有一个表字段,名为waybill_no,我们需要从tl_waybill_b ...
- (后端)maven仓库
仓库网址:http://mvnrepository.com/artifact/org.springframework/spring-core 可以去选择评分高的jar,复制: <!-- http ...
- 使用Visual Studio Team Services敏捷规划和项目组合管理(七)——流程定制
使用Visual Studio Team Services敏捷规划和项目组合管理(七)--流程定制 在Team Services中,可以通过流程定制工作追踪体验.流程定义了工作项跟踪系统的构建部分,以 ...
- Python自定义异常及抛出异常
""" 自定义异常 """ class MyException(Exception): # 继承异常类 def __init__(self, ...
- win10系统磁盘占用率高的解决方法,占用100%的问题
win10系统开机后明明什么都没做,磁盘占用率却只见飙升到了100%,出现这种情况是win10自带的服务导致的.下面的方法可以解决win10系统磁盘占用率高问题. 1.按下Win+R,然后输入serv ...
- SQL Server将一列的多行内容拼接成一行
昨天遇到一个SQL Server的问题:需要写一个储存过程来处理几个表中的数据,最后问题出在我想将一个表的一个列的多行内容拼接成一行 比如表中有两列数据 : ep_classes ep_name A ...
- Android重复依赖解决办法
参考文章:https://blog.csdn.net/qq_24216407/article/details/72842614 在build.gradle引用了Vlc的安卓包:de.mrmaffen: ...
- c函数指针
#include <stdio.h> int max(int a, int b){ return a > b ? a : b; } int min(int a, int b){ re ...