NLTK1及NLP理论基础
以下为Aron老师课程笔记
一、NLTK安装
1. 安装nltk
https://pypi.python.org/pypi/nltk
把nltk-3.0.0解压到D:\Anacond3目录
打开cmd,进到D:\Anaconda3\nltk-3.2.4\nltk-3.2.4目录
输入命令:python setup.py install
2. 安装PyYAML:
http://pyyaml.org/wiki/PyYAML(注意Py版本)
下载之后执行exe文件
3. 打开IDLE,输入import nltk,没有错误的话,就说明安装成功了
4. 下载NLTK_DATA
在python shell里面输入
Import nltk
nltk.download()
选择all,设置好下载路径(Download Directory),然后点击Download
二、文本处理流程
(清洗数据(缺失值、噪音数据、平滑处理)--->中文分词(将其转换成占位符,并且去掉一些可有可无的词)--->转换成数值特征提取(tfidf还有其他几种方法) --->特征选择(卡方互信息发IG法等等)--->用机器学习算法跑

中英文NLP最大的区别在于,因为每个词之间是空格分割,而中文都是粘到一起的,所以需要中文分词!Heuristic从字典中反复查阅,保证我们的词可以分成词。中文分词资料:结巴分词github主页 https://github.com/fxsjy/jieba;基于python的中文分词的实现及应用http://www.cnblogs.com/appler/archive/2012/02/02/2335834.html ;对Python中文分词模块结巴分词算法过程的理解和分析http://ddtcms.com/blog/archive/2013/2/4/69/jieba-fenci-suanfa-lijie/

1.Tokenize(把长句子,拆成有“意义”的小部件)
Import nltk
Sentence = “hello, world”
Tokens = nltk.word_tokenize(sentence)
Tokens
复杂的词形,表达相似的意思,需要归一化。其中nltk中提供了很多stemming(词干提取,把不影响词性的inflection的小尾巴砍掉比如walking砍成walk)的方式。


另外还有Lemmatization词形归一,把各种类型的变形都归为一个形式,比如went归一为go,are归一为be。nltk中也提供了Lemmatization。wordNetLemmatizer类似于一个字典网络,里面有各类词的归类,缺点是对于一些新词可能不知道。

Lemmatization还有些小问题,就比如把went认为是go,但实际可能是一个人名“温特”,所以需要指定词性,Part of Speech(POS) tag。

Nltk标注POS tag,然后把词性取出来放到lemmatize里面。

用正则保留一些词使其不被拆分
正则里面(?: )代表它是个大括号,[ ]代码的是里面任何一个,比如下面那个emoticons_str里面,第一个[ ]里面就是可能是: = ,第二个里面可能是- o,后面有个问号代表可以出现或不出现,第三个里面可能是P p D等,其实就是整个是描述表情符:-p :p :D这些。

得到regex_str后先compile一下形成token_re,然后利用token_re(s) s为原文本的str,把符合条件的都筛选出来,这样有些独特的东西就不会被拆分,比如网页这些
2. Stop停用词
一千个the有一千种指事
全体Stopwords列表http://www.ranks.nl/stopwords
Nltk去除停用词

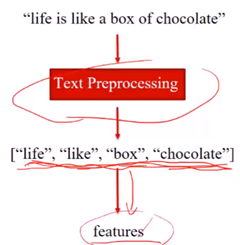
最终, 一条典型的文本处理流水线

三、自然语言处理
什么是自然语言处理,把自然语言处理成计算机能识别的数据
文本预处理得到wordlist后,我们需要得到一些能够表达出这个句子的特征
NLP的经典应用:
1.情感分析
最简单的sentimment dictionary,类似于打分机制,英文比如like 1分,good 2分,bad -2分,有人已经做好情感词典,
AFINN-111 http://www2.imm.dtu.dk/pubdb/views/publication_details.php?id=6010
sentiment_dictionary = {}
for line in open('data/AFINN-111.txt'):
word, score = line.split('/t')
sentiment_dictionary[word] = int(score)
#把打分表记录在一个dict上后
#跑一遍整个句子,把对应值相加
total_score = sum(sentiment_dictionary.get(word, 0) for word in words) #有值就是dict里面,没有就是0
#于是你就得到一个sentiment score
但这个方法仍然有很多缺点,比如新词怎么办?特殊词汇怎么办?更深层次的玩意怎么办?
配上ML的情感分析
from nltk.classify import NaiveBayesClassifier
#随手造点训练集
s1 = "this is a good book"
s2 = "this is a awesome book"
s3 = "this is a bad book"
s4 = "this is a terrible book" def preprocess(s):
return {word:True for word in s.lower().split())
#把训练集给成标准格式
training_data = [[preprocess(s1), 'pos'],[preprocess(s2), 'pos'],[preprocess(s3), 'pos'],[preprocess(s4), 'neg']]
#喂给model吃
model = NaiveBayesClassifier.train(training_data)
#打出结果
print(model.classifiy(preprocess("this is a good book"))
2. 文本相似度;文本分类
1. 高级的feature构造
-Levenshtein Distance(列文斯坦距离)
从string1到string2之间的距离,就是从string1变到string2需要做的删除、添加、替换的步骤数。或者使用Ratio(步骤数/总长度)。
-Frequency
用元素的频率表示文本特征

#TODO 词频统计
import nltk
from nltk import FreqDist
Corpus = 'this is my sentence'\
'this is my life'\
'this is the day'
tokens = nltk.word_tokenize(Corpus)
print(tokens)
fdist = FreqDist(tokens)
#把最常用的50个词取出
standard_freq_vector = fdist.most_common(50)
size = len(standard_freq_vector)
print(standard_freq_vector)
#按照频次出现的大小记录下位置
def position_lookup(v):
res = {}
counter = 0
for word in v:
res[word[0]] = counter
counter +=1
return res
standard_position_dict = position_lookup(standard_freq_vector)
print(standard_position_dict)
#这时如果有个新的句子
sentence = 'this is cool'
#新建一个跟我们标准vector同样大小的向量
freq_vector = [0] * size
#简单的对新句子处理下
tokens = nltk.word_tokenize(sentence)
for word in tokens:
try:
#如果在我们的词库里出现过 那么就在标准位置上+1
freq_vector[standard_position_dict[word]] +=1
except KeyError:
#如果是个新词,就Pass
continue
print(freq_vector)
但是存在另一个问题是词频的大小对于不同的文章是无法去归一化判断的,不像一个比例你知道在0到1之间,越大越好,比如一个单词在某篇文章里面出现100次,在另一个文章里出现1000次,可能100在第一个文章里面算很多,而在另一个文章里算很少,为了解决这个问题,我们产生了一个更严谨的计算方法方式。
-TFiDF
Tf 衡量一个term在文档中出现的有多频繁
TF(t)=(t出现在文档中的次数)/(文档中的term总数)
IDF: Inverse Document Frequency 衡量一个term有多重要,有些词出现很多,但并不重要,比如“is” “this”。为了平衡我们把罕见的词,重要性提高,把常见词的重要性搞低。
IDF(t)=log_e(文档总数/含有t的文档总数)
TF-IDF = TF*IDF

#TODO TFIDF
from nltk.text import TextCollection
#把所有的文档放到TextCollection类中,这个类会自动帮你断句,做统计,做计算
corpus = TextCollection(['this is sentence one','this is sentence two','this is sentence three'])
tokens = nltk.word_tokenize('this is sentence one'\
'this is sentence two' \
'this is sentence three')
fdist = FreqDist(tokens)
standard_freq_vector = fdist.most_common(50)
print(standard_freq_vector)
standard_vocab = []
for i in standard_freq_vector:
standard_vocab.append(i[0]) #直接能算出tfidf
# print (corpus.tf_idf('is','this is sentence four'))
new_sentence = 'this is sentence five'
for word in standard_vocab:
print(corpus.tf_idf(word, new_sentence))
-Word2Vec
#TODO 案例
#TODO Levenshtein
# import Levenshtein
# print(Levenshtein.ratio('hello','hello world'))
# df_all['dist_in_title'] = df_all.apply(lambda x: Levenshtein.ratio(x['serach_term'], x['product_title']))
#
# #TODO TFIDF
# df_all['all_texts'] = df_all['product_title'] + '.' + df_all['product_description'] + '.' #先把我们所有的文本变成一个大的语料库
from gensim.utils import tokenize
from gensim.corpora.dictionary import Dictionary
dictionary = Dictionary(list(tokenize(x, errors='ignore')) for x in df_all['all_texts'].values)
print(dictionary)
#扫遍我们所有语料,并且转换成简单的单词个数的计算
class MyCorpus(object):
def _iter_(self):
for x in df_all['all_texts'].values:
yield dictionary.doc2bow(list(tokenize(x, errors='ignore'))) #弄成类似于onehot [1,0,1,1,3,1]
corpus = MyCorpus()
#把已经变成BoW向量的数组,做一次TFIDF的计算
from gensim.models.tfidfmodel import TfidfModel
tfidf = TfidfModel(corpus)
#我们看一下放普通的句子长什么样 这里得到的值得size是,句子有多长,size就有多长,而我们要保证每个句子的size一样,所以单独可以写个方法
tfidf[dictionary.doc2bow(list(tokenize('hello world, good morning', errors='ignore')))] #把每个句子变回成总语料库那么长
from gensim.similarities import MatrixSimilarity
#先把刚刚那句话包装成一个方法
def to_tfidf(text):
res = tfidf[dictionary.doc2bow(list(tokenize(text, errors='ignore')))]
return res
#然后在计算出tfidf的基础上,我们创造一个cosine similarity的比较方法
def cos_sim(text1, text2):
tfidf1 = to_tfidf(text1)
tfidf2 = to_tfidf(text2)
index = MatrixSimilarity([tfidf1], num_features=len(dictionary))
sim = index[tfidf2]
return float(sim[0]) df_all['tfidf_cos_sim_in_title'] = df_all.apply(lambda x: cos_sim(x['search_term'], x['product_title']), axis=1)
NLTK1及NLP理论基础的更多相关文章
- NLP系列(2)_用朴素贝叶斯进行文本分类(上)
作者:龙心尘 && 寒小阳 时间:2016年1月. 出处: http://blog.csdn.net/longxinchen_ml/article/details/50597149 h ...
- NLP相关问题中文本数据特征表达初探
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- NLP VS NLU
NLP(Natural Language Processing )自然语言处理:是计算机科学,人工智能和语言学的交叉领域.目标是让计算机处理或“理解”自然语言,以执行语言翻译和问题回答等任务.NLU ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- 从NLP任务中文本向量的降维问题,引出LSH(Locality Sensitive Hash 局部敏感哈希)算法及其思想的讨论
1. 引言 - 近似近邻搜索被提出所在的时代背景和挑战 0x1:从NN(Neighbor Search)说起 ANN的前身技术是NN(Neighbor Search),简单地说,最近邻检索就是根据数据 ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 自然语言处理(NLP) - 数学基础(1) - 排列组合
正如我在<自然语言处理(NLP) - 数学基础(1) - 总述>一文中所提到的NLP所关联的概率论(Probability Theory)知识点是如此的多, 饭只能一口一口地吃了, 我们先 ...
随机推荐
- 【SPOJ116】Intervals
题目大意:有 N 个区间,在区间 [a, b] 中至少取任意互不相同的 c 个整数.求在满足 N 个区间约束的情况下,至少要取多少个正整数. 题解:差分约束系统模板题. 差分约束系统是对于 N 个变量 ...
- python常用的内置模块
1.import time time模块与时间相关的功能 在python中时间分为3种 1.时间戳timestamp从1970 1月 1日到现在的秒数 主要用于计算两个时间的差 2.localtime ...
- io系列之常用流二
一.对象的序列化.持久化. 将java的对象的基本数据类型和图形存入文件中,实现对象数据的序列化和持久化. 操作对象可以使用: ObjectOutPutStream 和 ObjectInPutStre ...
- STM32F407 ------ 使用定时器实现精确延时
测试环境:主频168M #include "delay.h" void delay_init() { TIM_TimeBaseInitTypeDef TIM_TimeBaseStr ...
- ajax 小练习
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta http-equiv="Con ...
- 关于MyBase 7.0 破解的方法
Mybase 是一个功能强劲且可随心所欲自定义格式及层次关系的通用资料管理软件, 可用于管理各种各样的信息,如一:各类文档.文件.资料.名片.事件.日记.项目.笔记.下载的精华.收集的各种资料等等,即 ...
- qml: 支持的基本类型
qml支持的基本类型有: bool unsigned int, int; float double qreal QString QUrl QColor QData, QTime QDat ...
- Vue.js 条件与循环
条件判断: v-if: 条件判断使用 v-if 指令: v-else-if:(其实和Java,c,js的语法差不多) v-show:
- python自动化开发-[第十七天]-django的ORM与其他
今日概要: 1.name别名 2.模版的深度查询 3.模版语言之filter 4.自定义过滤器,filter和simpletag的区别 5.orm进阶 扫盲:url的组成 URL:协议+域名+端口+路 ...
- python 函数基础及装饰器
没有参数的函数及return操作 def test1(): print ("welcome") def test2(): print ("welcomt test2&qu ...