y7000笔记本 darknet-yolo安装与测试(Ubuntu18.04+Cuda9.0+Cudnn7.1)
环境配置看上一贴
https://www.cnblogs.com/clemente/p/10386479.html
1 安装darknet
1-1 克隆darknet repo
git clone https://github.com/pjreddie/darknet.git
cd darknet
1-2 修改Makefile
注意提前备份一份 Makefile.bak
GPU环境下的编译配置都是在 /darknet/Makefile 文件中定义的,根据不同的GPU环境
有几处需要具体根据实际配置对Makefile进行修改
1-2-1.更改CUDA的路径
49-53行
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
endif
修改为
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/ #/usr/后面填你的cuda实际位置
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand #/usr/后面填你的cuda实际位置
endif
当然我们这里不需要修改,默认就是正确位置
1-2-2.修改ARCH配置
Loadingweights from yolo.weights…Done!
CUDA Error:invalid device function
darknet: ./src/cuda.c:21: check_error: Assertion `0’ failed.
Aborted (core dumped)
这是因为配置文件Makefile中配置的GPU架构和本机GPU型号不一致导致的。
更改前默认配置如下(不同版本可能有变):
7-10行
ARCH= -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
compute_30表示显卡的计算能力是3.0,几款主流GPU的compute capability列表:
显卡计算能力查询:https://blog.csdn.net/u010159842/article/details/56666158
我的是 笔记本版 gtx1060 对应的6.1
修改为
ARCH= -gencode arch=compute_61,code=sm_61 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
1-2-3.修改nvcc地址
NVCC=nvcc
修改为
NVCC=/usr/local/cuda/bin/nvcc
总结几处需要自己配置的地方
GPU=1 #如果使用GPU设置为1,CPU设置为0
CUDNN=1 #如果使用CUDNN设置为1,否则为0
OPENCV=1 #如果调用摄像头,还需要设置OPENCV为1,否则为0
OPENMP=0 #如果使用OPENMP设置为1,否则为0
DEBUG=0 #如果使用DEBUG设置为1,否则为0 ..... ARCH= -gencode arch=compute_61,code=sm_61 \ #根据自己的显卡的计算能力进行修改
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52] ......
CC=gcc
CPP=g++
NVCC=/usr/local/cuda/bin/nvcc #NVCC=nvcc 修改为自己的路径 .....
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/ #修改为自己的路径
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand #修改为自己的路径
endif
1-3 编译
make -j4
2 测试
2-1 测试OpenCV demo
./darknet imtest data/eagle.jpg
最后终端报错显示
./darknet: error while loading shared libraries: libcudart.so.9.0: cannot open shared object file: No such file or directory
输入
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
发现正常运行,故是系统路径问题
解决方法: 将相应的库文件复制到/usr/lib
sudo cp /usr/local/cuda/lib64/libcudart.so.9.0 /usr/local/lib/
sudo cp /usr/local/cuda/lib64/libcublas.so.9.0 /usr/local/lib/
sudo cp /usr/local/cuda/lib64/libcurand.so.9.0 /usr/local/lib/
#sudo cp /usr/local/cuda/lib64/libcudnn.so. /usr/local/lib/
sudo cp /usr/local/cuda/lib64/libcudnn.so.7.3. /usr/local/lib/
sudo ldconfig
ldconfig命令是一个动态链接库管理命令,是为了让动态链接库为系统共享
重新测试opencv demo
./darknet imtest data/eagle.jpg
2-2 在一张测试图片上测试yolov3和yolov2
# 下载yolov3-weights
wget https://pjreddie.com/media/files/yolov3.weights
# 下载yolov2-weights
wget https://pjreddie.com/media/files/yolov2.weights
# 测试yolov3
sudo ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
# 测试yolov2
sudo ./darknet detect cfg/yolov2.cfg yolov2.weights data/dog.jpg
yolov2运行正常
yolov3发现如下错误
CUDA Error: out of memory
darknet: ./src/cuda.c:: check_error: Assertion `' failed.
Aborted
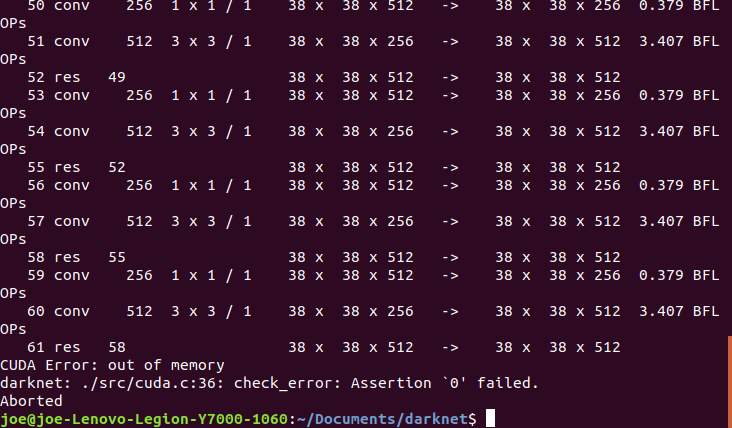
运行现存不足,需要修改yolo配置文件
../darknet/cfg/yolov3.cfg
[net]
# Testing
# batch=
# subdivisions=
# Training
batch=
subdivisions=64 #修改这里为64
width=
height=
channels=
momentum=0.9
decay=0.0005
angle=
saturation = 1.5
exposure = 1.5
hue=.
subdivisions:这个参数会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半,默认值16在笔记本显存水平会爆CUDA Error: out of memory,当然如果你的配置够强,是没有这个报错的
下面附一份yolo配置文件理解
[net]
batch= 每batch个样本更新一次参数。
subdivisions= 如果内存不够大,将batch分割为subdivisions个子batch,每个子batch的大小为batch/subdivisions。
在darknet代码中,会将batch/subdivisions命名为batch。
height= input图像的高
width= Input图像的宽
channels= Input图像的通道数
momentum=0.9 动量
decay=0.0005 权重衰减正则项,防止过拟合
angle= 通过旋转角度来生成更多训练样本
saturation = 1.5 通过调整饱和度来生成更多训练样本
exposure = 1.5 通过调整曝光量来生成更多训练样本
hue=. 通过调整色调来生成更多训练样本 learning_rate=0.0001 初始学习率
max_batches = 训练达到max_batches后停止学习
policy=steps 调整学习率的policy,有如下policy:CONSTANT, STEP, EXP, POLY, STEPS, SIG, RANDOM
steps=,, 根据batch_num调整学习率
scales=,.,. 学习率变化的比例,累计相乘 [convolutional]
batch_normalize= 是否做BN
filters= 输出多少个特征图
size= 卷积核的尺寸
stride= 做卷积运算的步长
pad= 如果pad为0,padding由 padding参数指定。如果pad为1,padding大小为size/
activation=leaky 激活函数:
logistic,loggy,relu,elu,relie,plse,hardtan,lhtan,linear,ramp,leaky,tanh,stair [maxpool]
size= 池化层尺寸
stride= 池化步进 [convolutional]
batch_normalize=
filters=
size=
stride=
pad=
activation=leaky [maxpool]
size=
stride= ......
...... ####### [convolutional]
batch_normalize=
size=
stride=
pad=
filters=
activation=leaky [convolutional]
batch_normalize=
size=
stride=
pad=
filters=
activation=leaky [route] the route layer is to bring finer grained features in from earlier in the network
layers=- [reorg] the reorg layer is to make these features match the feature map size at the later layer.
The end feature map is 13x13, the feature map from earlier is 26x26x512.
The reorg layer maps the 26x26x512 feature map onto a 13x13x2048 feature map
so that it can be concatenated with the feature maps at 13x13 resolution.
stride= [route]
layers=-,- [convolutional]
batch_normalize=
size=
stride=
pad=
filters=
activation=leaky [convolutional]
size=
stride=
pad=
filters= region前最后一个卷积层的filters数是特定的,计算公式为filter=num*(classes+)
5的意义是5个坐标,论文中的tx,ty,tw,th,to
activation=linear [region]
anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52 预选框,可以手工挑选,
也可以通过k means 从训练样本中学出
bias_match=
classes= 网络需要识别的物体种类数
coords= 每个box的4个坐标tx,ty,tw,th
num= 每个grid cell预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num,且如果调大num后训练时Obj趋近0的话可以尝试调大object_scale
softmax= 使用softmax做激活函数
jitter=. 通过抖动增加噪声来抑制过拟合
rescore= 暂理解为一个开关,非0时通过重打分来调整l.delta(预测值与真实值的差) object_scale= 栅格中有物体时,bbox的confidence loss对总loss计算贡献的权重
noobject_scale= 栅格中没有物体时,bbox的confidence loss对总loss计算贡献的权重
class_scale= 类别loss对总loss计算贡献的权重
coord_scale= bbox坐标预测loss对总loss计算贡献的权重 absolute=
thresh = .
random= random为1时会启用Multi-Scale Training,随机使用不同尺寸的图片进行训练。
2-3 在一张测试图片上测试yolov3-tiny
# 下载yolov3-tiny.weights
wget https://pjreddie.com/media/files/yolov3-tiny.weights
# 测试
sudo ./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg

速度非常快,在1060上fps147
2-4 使用网络摄像头上测试yolo
先检查摄像头是否正常工作
sudo apt-get install cheese
终端输入cheese,如果弹出摄像头窗口,说明摄像头正常
cheese
检查摄像头id,一般id为0
ls /dev/video*
yolov2
sudo ./darknet detector demo cfg/coco.data cfg/yolov2.cfg yolov2.weights
yolov3
sudo ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
yolov3-tiny
sudo ./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights
检测帧率似乎锁帧了 不管是yolov2还是yolov3,yolov3-tiny 一直在10FPS
如果要使用外部usb 摄像头 请用
sudo ./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -c 1
其中1替换成 ls /dev/video* 中显示的id 号(设备号)
2-5 使用yolo检测视频文件
yolov3检测视频
sudo ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights data/webwxgetvideo.mp4
yolov2检测视频
sudo ./darknet detector demo cfg/coco.data cfg/yolov2.cfg yolov2.weights data/webwxgetvideo.mp4
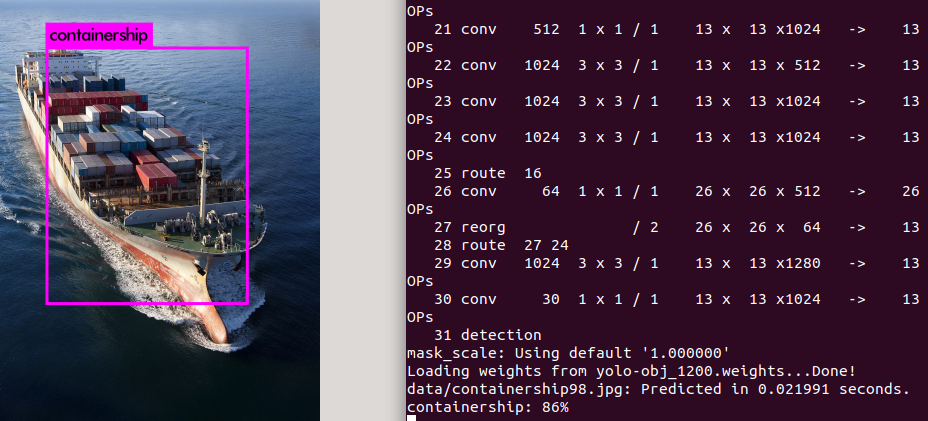
Yolov3 darknet训练后可能会检测不出物体 或者检测标示错误
sudo ./darknet detect cfg/yolo-obj.cfg yolo-obj_1200.weights data/containership98.jpg

发现检测位置正确,但标示错了
原因是 没有显式得指明你的xx.data文件 而使用了默认的coco.names文件的类别的cfg/coco.data文件
sudo ./darknet detector test cfg/obj.data cfg/yolo-obj.cfg yolo-obj_1200.weights data/containership98.jpg
整理了一下,随手记一下。
在终端里,直接运行时Yolo的Darknet的各项命令,/home/wp/darknet/cfg/coco.data文件,使用原件:
=======================================coco.data=====================================================
classes= 80
train = /home/pjreddie/data/coco/trainvalno5k.txt
valid = coco_testdev
#valid = data/coco_val_5k.list
names = data/coco.names
backup = /home/pjreddie/backup/
eval=coco
====================================================================================================
(1)检测一张图片
wp@wp-MS-7519:~/darknet$ ./darknet detect cfg/yolov3.cfg wp_data/yolov3.weights data/dog.jpg
出现问题:
./darknet detector test cfg/yolov3.cfg wp_data/yolov3.weights data/dog.jpg报错names: Using default 'data/names.list'。。。Couldn't open file: data/names.list
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg 没有结果出来。
(2)检测一段视频
接好usb后,直接运行usb视频检测
wp@wp-MS-7519:~/darknet$ ./darknet detector demo /home/wp/darknet/cfg/coco.data /home/wp/darknet/cfg/yolov3.cfg /home/wp/darknet/weights/yolov3.weights
说明:在CPU下,运行的特别卡。"直接接USB,然后执行:./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights就可以了啊,
官网https://pjreddie.com/darknet/yolo/说的很详细的。"
++++++++++++++++++++++++++++++++++++YOLO V3常用命令总结++++++++++++++++++++++++++++++++++++++++++++++
参考@http://www.cnblogs.com/pprp/p/9525508.html
(1)在GPU下训练自己的模型
1.1 单GPU训练:./darknet -i <gpu_id> detector train <data_cfg> <train_cfg> <weights>
$ ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
1.2 多GPU训练,格式为0,1,2,3:./darknet detector train <data_cfg> <model_cfg> <weights> -gpus <gpu_list>
$ ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpus 0,1,2,3
(2)单张测试命令:
$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
添加阈值:阈值范围0~1,By default, YOLO only displays objects detected with a confidence of .25 or higher. You can change this by passing the -thresh <val> flag to the yolo command. For example, to display all detection you can set the threshold to 0:
$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
(3)批量测试图片
官网的测试命令,只能单张测试,如果需要批量测试则yolov3-voc.cfg(cfg文件夹下)文件中batch和subdivisions两项必须为1,并修改detector.c文件中的相关地方,重新进行编译make clean,make。
开始批量测试:
$ ./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights
接着在终端中,输入Image Path(所有的测试文件的路径,可以复制voc.data中valid后边的路径):
/home/learner/darknet/data/voc/2007_test.txt # 完整路径。
结果都保存在./data/out(detector.c中设定路径)文件夹下。
(4)生成预测结果:
$ ./darknet detector valid <data_cfg> <test_cfg> <weights> <out_file>
yolov3-voc.cfg(cfg文件夹下)文件中batch和subdivisions两项必须为1。
结果生成在<data_cfg>的results指定的目录下以<out_file>开头的若干文件中,若<data_cfg>没有指定results,那么默认为<darknet_root>/results。
执行语句如下:在终端只返回用时,在./results/comp4_det_test_[类名].txt里保存测试结果
$ ./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights
(5)官网的测试命令作为入口 @https://pjreddie.com/darknet/yolo/
5.1 单张测试命令:
$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
./darknet 是执行当前文件下面已经编译好的darknet文件
detect 是命令 后面三个分别是参数: 网络模型 网络权重 需要检测的图片
命令“ ./darknet detect ”等同于“ ./darknet detector test ”,The detect command is shorthand for a more general version of the command. It is equivalent to the command:
$ ./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
5.2 多张测试命令:
$ ./darknet detect cfg/yolov3.cfg yolov3.weights
Enter Image Path: data/dog1.jpg
Enter Image Path: data/dog2.jpg
5.3 改变阈值
YOLO默认阈值0.25,可以自行设定:
$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
5.4 Real-Time Detection on a Webcam
实时视频检,测需要Darknet with CUDA and OpenCV,-c <num>,OpenCV默认为0:
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
本地视频检,直接输入视频:
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
5.5 在预训练的模型上继续训练
在 CPU 下训练:$ ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
在 多GPU下训练:$ ./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
从定点继续训练:$ ./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
5.6 测试公开数据
$ ./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
=====================================================
(6)对 视频 进行测试命令:
对本地视频进行测试 命令:
>>>Darknet环境中,$ ./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/xxx.mp4
>>>OpenCV 环境中, $ python3 object_detection_yolo.py --video=run.mp4
【a single image:
python3 object_detection_yolo.py --image=bird.jpg
a video file:
python3 object_detection_yolo.py --video=run.mp4 】
对USB摄像头视频进行测试 命令:
>>>Darknet环境中,$ ./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights
>>>OpenCV 环境中, $ (暂略)
对WebCam网络视频(比如大华、海康相机)进行测试 命令:
这里使用命令前需要作相应的修改,需要相机+电脑在同一局域网,这样才能访问。首先,要知道相机的IP,然后在电脑里添加相机的六段IP地址,在IPv4中添加类似:192.168.6.111,前二位表示在同一局域网,第三位1表示1段的IP、6表示6段的IP。接着获取相机的用户名、密码。这样才能使用 添加摄像机 命令,
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights rtsp://admin:hik12345@30.14.199.6:554/h265/ch1/main/av_stream
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights rtsp://admin:abcd12345@30.14.6.192:554/Streaming/Channels/1/
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights rtsp://admin:abcd12345@30.14.6.192:554/Streaming/Channels/101/
+++++++++++++++++++++++++++++++++《摄像机Rtsp地址格式大全》++++++++++++++++++++++++++++++
@https://www.cnblogs.com/dpf-10/p/5533698.html
@http://www.mamicode.com/info-detail-2190692.html
@https://blog.csdn.net/viola_lulu/article/details/53330727
一. 海康、中威摄像机
格式1
主码流:rtsp://admin:12345@192.168.1.64:554/Streaming/Channels/1
子码流:rtsp://admin:12345@192.168.1.64:554/Streaming/Channels/2
第三码流:rtsp://admin:12345@192.168.1.64:554/Streaming/Channels/3
格式2
rtsp://admin:12345@192.168.1.64:554/ch1/main/av_stream
如果摄像机密码是a12345678,IP是192.168.1.64,RTSP端口默认554未做改动,是H.264编码,那么
主码流取流:
rtsp://admin:a12345678@192.168.1.64:554/h264/ch1/main/av_stream
子码流取流:
rtsp://admin:a12345678@192.168.1.64:554/h264/ch1/sub/av_stream
【如果是H.265编码的,那么将H.264替换成H.265即可】
y7000笔记本 darknet-yolo安装与测试(Ubuntu18.04+Cuda9.0+Cudnn7.1)的更多相关文章
- Ubuntu18.04+CUDA9.0+cuDNN7.1.3+openface安装总结
目录 前言 编译工具CMake C++标准库安装 下载OpenFace代码 OpenCV安装 luarocks-Lua 包管理器,提供一个命令行的方式来管理 Lua 包依赖.安装第三方 Lua 包等功 ...
- Ubuntu18.04 + CUDA9.0 + cuDNN7.3 + Tensorflow-gpu-1.12 + Jupyter Notebook深度学习环境配置
目录 一.Ubuntu18.04 LTS系统的安装 1. 安装文件下载 2. 制作U盘安装镜像文件 3. 开始安装 二.设置软件源的国内镜像 1. 设置方法 2.关于ubuntu镜像的小知识 三.Nv ...
- Ubuntu18.04+CUDA9.0+cuDNN7.1.3+TensorFlow1.8 安装总结
Ubuntu18.04发行已经有一段时间了,正好最近Tensorflow也发布了1.8版本,于是决定两个一起装上,以下是安装总结,大致可 以分为5个步骤 确认当前软件和硬件环境.版本 更新显卡驱动,软 ...
- Ubuntu18.04 + cuda9.0+cudnn7.0
1 cannot find Toolkit in /usr/local/cuda-8.0 2017年05月27日 17:37:33 阅读数:2754 对于新版本ubuntukylin17.04安装C ...
- ubuntu18.04+ cuda9.0+opencv3.1+caffe-ssd安装
详细Ubuntu18.04,CUDA9.0,OpenCV3.1,Tensorflow完全配置指南 问题1:使用Cmake编译opencv源码 CMake Error: The following va ...
- ubuntun16.04+cuda9.0+cudnn7+anaconda3+pytorch+anaconda3下py2安装pytorch
一.电脑配置 说明: 电脑配置: LEGION笔记本CPU Inter Core i7 8代GPU NVIDIA GeForce GTX1060Windows10 所需的环境: Anaconda3(6 ...
- y7000笔记本 darknet-yolo安装与测试(Ubuntu16.04+Cuda9.0+Cudnn7.1)
https://zhuanlan.zhihu.com/p/41096599 1.先查看是否安装有以下组件,若有先考虑彻底删除再安装(安装严格按照下面顺序进行) 查看nvidia 版本 nvidia-s ...
- Ubuntu16.04 + cuda9.0 + cudnn7.1.4 + tensorflow安装
安装前的准备 UEFI 启动GPT分区 Win10和Ubuntu16.04双系统安装 ubuntu16.04 NVIDIA 驱动安装 ubuntu16.04 NVIDIA CUDA8.0 以及cuDN ...
- 问题记录 | 配置ubuntu18.04+cuda9.0+cudnn服务器tensorflow-gpu深度学习环境
因为实验室服务器资源有限,我被分配的服务器经常变化,但是常常就分到连显卡驱动以及cuda都没有装的服务器,真的很头疼,我已经配了四五台了,特此记录一下,以便以后直接照版本安装. Install nvi ...
随机推荐
- Android开发过程中的坑及解决方法收录(五)
1. 导入依赖库出现错误 因为使用的sdk版本不同,使用下列代码强制使用最低版本,25.3.1就是我当前使用的版本号,根据自己的情况修改 configurations.all { resolution ...
- 在html中使用特殊字体
目的:一首诗,要求从右往左读,垂直排列,类似古文 效果图: html内容: <!doctype html><html lang="en"><head& ...
- 鼠标滑过侧边弹出内容(JS)
效果展示 实现原理 1. html结构: <div id="contain"> <span id="share">分享</span ...
- [工具配置]requirejs 多页面,多入口js文件打包总结
需要明确以下几点: 1.本地前端调试代码肯定是调用原始的路径以及代码,但是线上运行的肯定是通过打包后的另一个路径,这儿就是生成的dist文件夹了. 2.requirejs的引入,线上跟线下的路径怎么控 ...
- HTML5为输入框添加语音输入功能
这里介绍的是大家以后要用到的html强大功能,可直接给输入框增加语音功能,下面我们先来看看实现方法. 大家可以看到在输入框右边的麦克风图标,点击麦克风就能够进行语音识别了. 其实很简单,语音识别是ht ...
- iOS ---------NSURLSession/NSURLConnection HTTP load failed (kCFStreamErrorDomainSSL, -9813)
遇到此问题的解决办法: 使用<NSURLSessionDelegate>中的didReceiveChallenge方法,方法中的代码如下: - (void)URLSession:(NSUR ...
- iOS---------如何搭建ipv6环境
第一步:首先打开共享 第二步:点击互联网共享,然后按option键.会出现创建NAT64网络 第三步:点击Wi-Fi共享,设置网络名称,频段:11.安全性:WPA2个人级.密码设置8位就可以了.然后在 ...
- Java的优先级任务队列的实践
队列的基本理解 在说队列之前说两个名词:Task是任务,TaskExecutor是任务执行器 而我们今天要说的队列就完全符合某机构这个情况,队列在有Task进来的时候TaskExecutor就立刻开始 ...
- 操作系统-进程通信(信号量、匿名管道、命名管道、Socket)
进程通信(信号量.匿名管道.命名管道.Socket) 具体的概念就没必要说了,参考以下链接. 信号量 匿名管道 命名管道 Socket Source Code: 1. 信号量(生产者消费者问题) #i ...
- Android getprop 读取的属性哪里来的?
Android getprop 和 setprop 可以对系统属性进行读取和设置. 通过串口执行以下 geyprop 打印出来的属性让你一目了然. 属性出来了,但是在哪里设置的呢,这里有两个 ...