WebMagic简介和使用
概览
WebMagic是一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。
WebMagic项目代码分为核心和扩展两部分。
- 核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。这部分提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫。
- 扩展部分(webmagic-extension)提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开发。
总体架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。
WebMagic总体架构图如下:

WebMagic的四个组件
- Downloader:Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
- PageProcessor:PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。在这四个组件中,
PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。 - Scheduler:Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
- Pipeline:Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
用于数据流转的对象
- Request:
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。 - Page:
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。 - ResultItems:
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
实例
Maven坐标
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
爬取安居客房价信息实例
需求是获取所有小区的房价,先看一下页面截图:
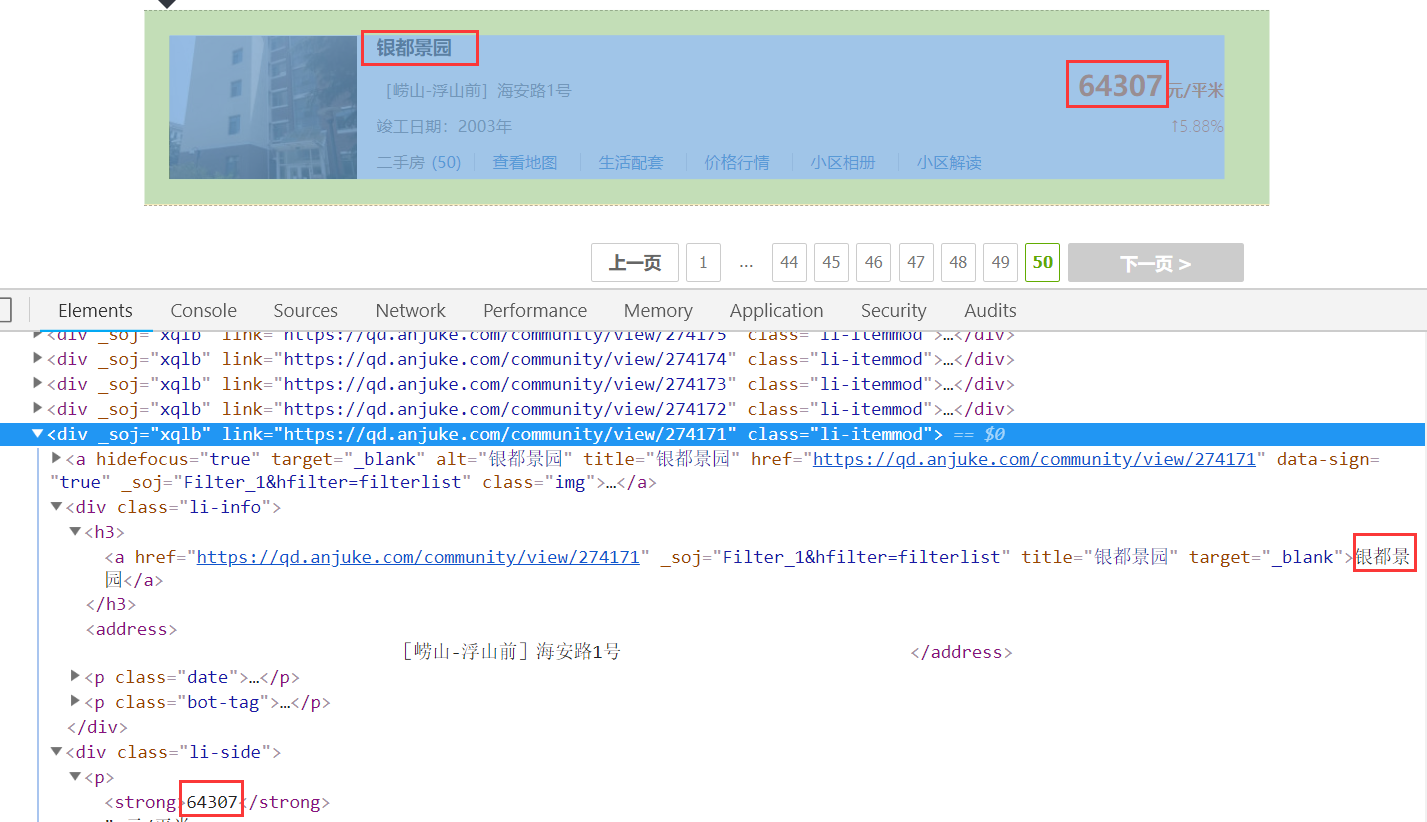
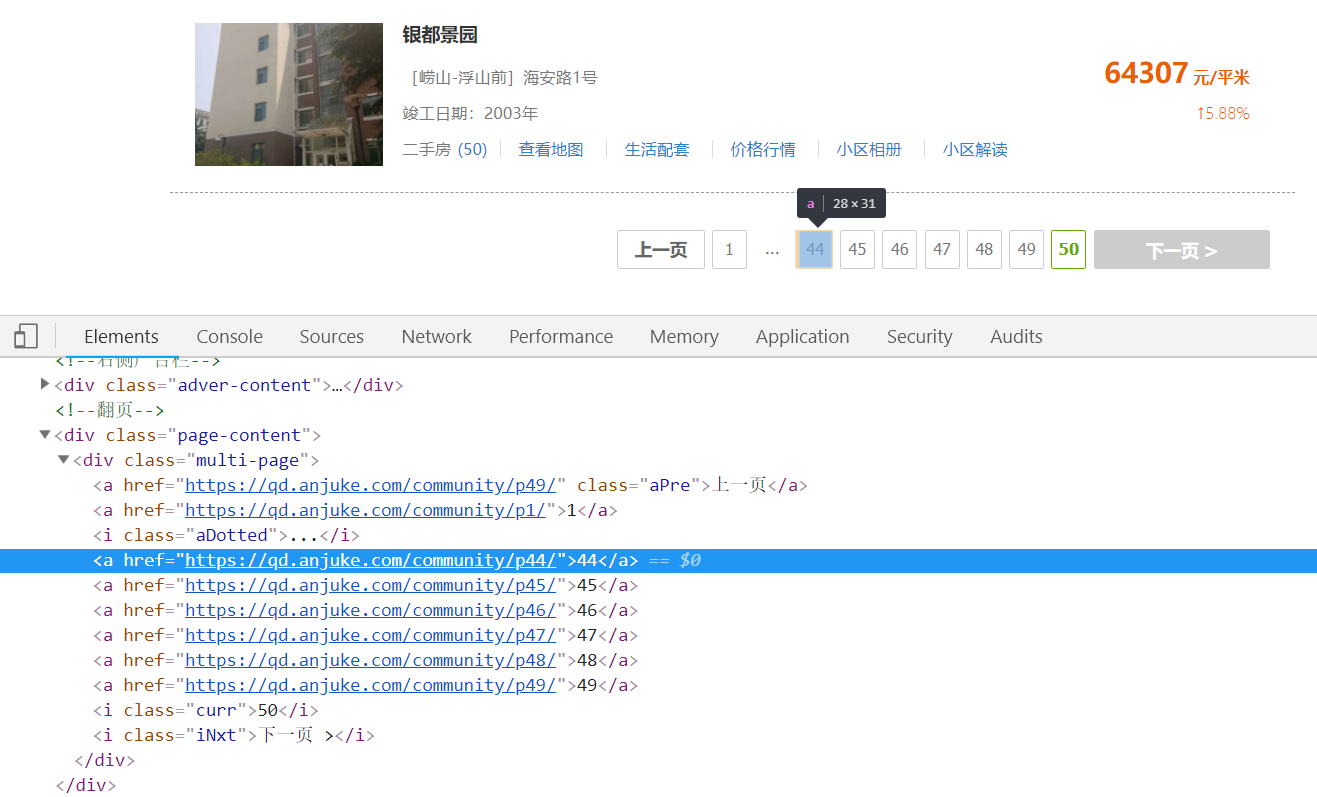
代码:
public class AnjukeProcessor implements PageProcessor {
//抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count = 0;
private static List<String> urlList = new ArrayList<>();
@Override
public void process(Page page) {
//从页面发现后续的url地址来抓取
page.addTargetRequests(
page.getHtml().xpath("//div[@class='page-content']/div[@class='multi-page']/a/@href").all());
//判断链接是否符合"https://qd.anjuke.com/community/p任意个数字"格式
if (page.getUrl().regex("https://qd.anjuke.com/community/p[0-9]+").match()) {
//定义如何抽取页面信息,并保存下来
List<Selectable> selectableList = page.getHtml().xpath("//div[@class='list-content']/div[@class='li-itemmod']").nodes();
List<HousePrice> list = new ArrayList<>();
for(Selectable selectable : selectableList){
String name = selectable.xpath("//div[@class='li-info']/h3/a/text()").toString();
String price = selectable.xpath("//div[@class='li-side']/p[1]/strong/text()").toString();
HousePrice housePrice = new HousePrice();
housePrice.setName(name.trim());
housePrice.setPriceStr(price.trim());
list.add(housePrice);
}
page.putField("housePriceList",list);
urlList.add(page.getUrl().toString());
count++;
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new AnjukeProcessor())
.addUrl("https://qd.anjuke.com/community/") //从https://qd.anjuke.com/community/开始爬取
.addPipeline(new HousePricePipeline()) //使用自定义的Pipeline
.thread(5)
.run();
System.out.println("----------抓取了"+count+"条记录");
}
}
public class HousePricePipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task task) {
System.out.println("----------get page: " + resultItems.getRequest().getUrl());
List<HousePrice> list = resultItems.get("housePriceList");
System.out.println("----------list size:" + list.size());
}
}
注意事项
在0.7.3版本中,爬取只支持TLS1.2的https站点的时候会报错:
javax.net.ssl.SSLException: Received fatal alert: protocol_version
解决办法:https://github.com/code4craft/webmagic/issues/701
相关文档
WebMagic简介和使用的更多相关文章
- java 之webmagic 网络爬虫
webmagic简介: WebMagic是一个简单灵活的Java爬虫框架.你可以快速开发出一个高效.易维护的爬虫. http://webmagic.io/ 准备工作: Maven依赖(我这里用的Mav ...
- webmagic源码浅析
webmagic简介 webmagic可以说是中国传播度最广的Java爬虫框架,https://github.com/code4craft/webmagic,阅读相关源码,获益良多.阅读作者博客[代码 ...
- 爬虫框架--webmagic
官方有详细的使用文档:http://webmagic.io/docs/zh/ 简介:这只是个java爬虫框架,具体使用需要个人去定制,没有图片验证,不能获取js渲染的网页,但简单易用,可以通过xpat ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- Java爬虫框架WebMagic——入门(爬取列表类网站文章)
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 简单搭建webMagic爬虫步骤
1.简介 WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个高效.易维护的爬虫. 官网:http://webmagic.io/ 中文官网:http://web ...
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 学校实训作业:Java爬虫(WebMagic框架)的简单操作
项目名称:java爬虫 项目技术选型:Java.Maven.Mysql.WebMagic.Jsp.Servlet 项目实施方式:以认知java爬虫框架WebMagic开发为主,用所学java知识完成指 ...
- ASP.NET Core 1.1 简介
ASP.NET Core 1.1 于2016年11月16日发布.这个版本包括许多伟大的新功能以及许多错误修复和一般的增强.这个版本包含了多个新的中间件组件.针对Windows的WebListener服 ...
随机推荐
- HEVC有损优化二
1 . HEVC有很些设置对速度的提升有很大的帮助,比如m_bUseEarlyCU,m_useEarlySkipDetection等. 把它们设置成true,会有意想不到的效果. 比如对于不同分辨率 ...
- cesium入门1
本教程将获得所有技能水平的开发人员和他们的第一个铯应用程序运行. 验证Cesium在您的Web浏览器中工作的最简单的方法是单击此处运行Hello World示例 (打开一个新窗口).如果你看到像下面的 ...
- GIS-004-Cesium版权信息隐藏
.cesium-widget-credits { display: none; } .cesium-viewer .cesium-widget-credits { display: none; }
- python2.0_s12_day9之day8遗留知识(queue队列&生产者消费者模型)
4.线程 1.语法 2.join 3.线程锁之Lock\Rlock\信号量 4.将线程变为守护进程 5.Event事件 * 6.queue队列 * 7.生产者消费者模型 4.6 queue队列 que ...
- Python urllib2 模块
urllib2.urlopen(url, data=None, timeout=<object object>) :用于打开一个URL,URL可以是一个字符串也可以是一个请求对象,data ...
- js里面函数的内部属性
1.arguments用來存放传输参数的集合,可以被调用多次,每次数組都不一样,增强了函数的强壮性 实例: function calc() { var sum = 0; /*参数为一个时候*/ if ...
- Android 多状态按钮ToggleButton
1.什么是ToggleButtonToggleButton有两种状态:选中和未选中状态并且需要为不同的状态设置不同的显示文本2.ToggleButton属性android:checked=" ...
- win7(64)使用vim碰到的奇怪问题
一直使用conemu做控制台使用vim,操作系统win7 64位,一直用的很好. 今天使用gvim打开文件发现c:\program file(x86)\vim\_vimrc不生效,最奇怪的是,采用控制 ...
- JS-制作留言提交系统(支持ctrl+回车)
弹出键值说明: //console.log(ev.keyCode)//回车:13//ctrl:17 <!DOCTYPE html> <html> <head> &l ...
- 310实验室(六)CMake学习心得
树形结构方式布局. OTL 中每一个文件中的CMakeLists.txt 有不同的作用:按查看文件的先后顺便进行分层理解, 根文件即第一次 中的.txt是 启用 CMAKE_MODULE_PATH模板 ...