Node爬虫之——使用async.mapLimit控制请求并发
一般我们在写爬虫的时候,很多网站会因为你并发请求数太多当做是在恶意请求,封掉你的IP,为了防止这种情况的发生,我们一般会在代码里控制并发请求数,Node里面一般借助async模块来实现。
1. async.mapLimit方法
mapLimit(arr, limit, iterator, callback)
arr中一般是多个请求的url,limit为并发限制次数,mapLimit方法将arr中的每一项依次拿给iterator去执行,执行结果传给最后的callback;
2. async.mapLimit方法应用
下面是之前写过的一个简单的爬虫示例,将爬取到的新闻标题和路径保存在一个Excel表格中,限制并发数为3,代码如下
webSpider.js:
//request调用url主函数 (mapLimit iterator)
function main(option, callback) {
n++;
timeline[option] = new Date().getTime();
console.log('现在的并发数是', n, ',正在抓取的是', option);
request(option, function(err, res, body) {
if(!err && res.statusCode == 200){
var $ = cheerio.load(body);
$('#post_list .post_item').each(function(index, element) {
// console.log(element);
var item = [$(element).find('.post_item_body h3 a').text(),$(element).find('.post_item_body h3 a').attr('href')];
dataArr[0].data.push(item);
});
console.log('抓取', option, '结束,耗时:', new Date().getTime()-timeline[option], '毫秒');
n--;
callback(null, 'done!');
}else{
console.log(err);
n--;
callback(err, null);
}
});
}
//限制请求并发数为3
async.mapLimit(options, 3, main.bind(this), function(err, result){
if(err) {
console.log(err);
} else {
fs.writeFile('data/cnbNews.xlsx', xlsx.build(dataArr), 'utf-8', function(err){
if(err){
console.log('write file error!');
}else{
console.log('write file success!');
}
});
}
});
这里迭代器里面第二个参数callback(即请求每一条url完成之后的回调方法)是关键,没有异常的情况下所有options中的url都请求完成之后会回调mapLimit方法的回调方法进行后续操作(如这里的生成文件),如果单条url请求异常,回调方法中会接收到err并报出错误,不能执行后续生成文件的操作。
async.mapLimit(options, 3, function(option, callback) {
request(option, main);
callback(null);
}, function(err, result) {
if(err) {
console.log(err);
} else {
console.log('done!');
}
});
如上,网上有些资料中是在迭代器中request方法执行完成之后调用callback,因为request方法异步接收请求数据,这种写法会使async.mapLimit方法limit参数无效,导致无法达到限制请求并发数的目的,这里需要注意下。
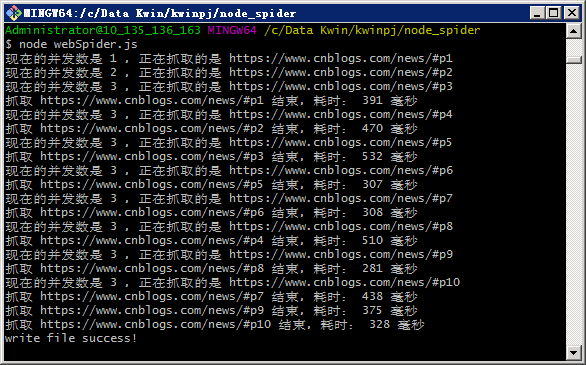
执行webSpider.js,
node webSpider.js
3. 总结
执行结果可以看到并发数依次增加,增加到3时不再继续增加,等待前面一条请求执行完成后才会请求下一条,这样的话,如果我们需要爬取1000条数据,就可以并发10条请求,慢慢爬完这1000个链接,这样就不用担心因并发太多被封IP这种情况发生了。完整代码已上传GitHub,有兴趣去试试吧!
Node爬虫之——使用async.mapLimit控制请求并发的更多相关文章
- node 爬虫 --- 批量下载图片
步骤一:创建项目 npm init 步骤二:安装 request,cheerio,async 三个模块 request 用于请求地址和快速下载图片流. https://github.com/reque ...
- node爬虫扒小说
Step 1: 万年不变的初始化项目,安装依赖 cnpm i express cheerio superagent superagent-charset async -S express 就不用多说 ...
- node爬虫(转)
我们先来看看今天的目标: mmjpg.com的美腿频道下的图片 一.实现步骤 使用superagent库来获取页面分析页面结构,使用cheerio 获取有效信息保存图片到本地开撸不断优化 这儿我们用到 ...
- 简单的node爬虫练手,循环中的异步转同步
简单的node爬虫练手,循环中的异步转同步 转载:https://blog.csdn.net/qq_24504525/article/details/77856989 看到网上一些基于node做的爬虫 ...
- 继续node爬虫 — 百行代码自制自动AC机器人日解千题攻占HDOJ
前言 不说话,先猛戳 Ranklist 看我排名. 这是用 node 自动刷题大概半天的 "战绩",本文就来为大家简单讲解下如何用 node 做一个 "自动AC机&quo ...
- Node爬虫
Node爬虫 参考 http://www.cnblogs.com/edwardstudy/p/4133421.html 所谓的爬虫就是发送请求,并将响应的数据做一些处理 只不过不用浏览器来发送请求 需 ...
- node爬虫(简版)
做node爬虫,首先像如何的去做这个爬虫,首先先想下思路,我这里要爬取一个页面的数据,要调取网页的数据,转换成页面格式(html+div)格式,然后提取里面独特的属性值,再把你提取的值,传送给你的页面 ...
- node爬虫的几种简易实现方式
说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的.在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node 爬虫的方式.第一种方式,采用node,js中的 s ...
- 自己写的服务出现"服务没有及时响应启动或控制请求 1053" 错误
自己写了一个服务,安装到电脑上后 启动时发现报"服务没有及时响应启动或控制请求 1053" 这个错误 在网上找了一些方法,都没有解决 后来,看了下,原来有个写文件的方法读取文件没有 ...
随机推荐
- C# DataTable Compute方法的使用
在开发中需要对DataTable的数据进行处理,比如累加,求最大最小及平均值等,以前都采用手工对DataTable进行循环并计算的方式,现在发现DataTable的Compute方法可以轻松实现这些功 ...
- mysqlbinlog初识
mysql-binlog->解析mysql的binlog日志 mysql的binlog日志是什么? 数据目录下的日下文件就是mysql的binlog日志 mysql-bin.00001 mysq ...
- 我的octopress配置
在github上用octopress搭建了自己的blog,octopress号称是"专门给黑客打造的博客(A blogging framework for 把hackers)",使 ...
- oracle创建定时器详解|interval属性
定时任务首先先创建定时任务中的存储过程 create or replace procedure pro_jggl as ...
- timer Compliant Controller project (2)--Project Demonstration
1software flow diagram As we know, Embedded design is the core of Electronic Product Design. Di ...
- 再谈Spring AOP
1.AOP的基本概念 在进行AOP开发前,先熟悉几个概念: 连接点(Jointpoint):表示需要在程序中插入横切关注点的扩展点,连接点可能是类初始化.方法执行.方法调用.字段调用或处理异常等等,S ...
- iOS-----使用addressBook管理联系人之修改联系人
使用addressBook管理联系人之修改联系人 修改联系人 修改联系人先从底层地址簿中加载一条ABRecordRef记录,然后对这条ABRecordRef记录的属性值进行修改,修改完成后把这条修改后 ...
- Struts2中StrutsRequestWrapper类
该类可获取一些请求地址,在自定义struts2标签时用到 //获取值栈 Map cont= this.getStack().getContext(); StrutsRequestWrapper req ...
- Android实现带图标的ListView
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/bear_huangzhen/article/details/23991119 Android实现带图 ...
- docker 数据卷 ---- 基础篇
用户在使用 Docker 的过程中,往往需要能查看容器内应用产生的数据,或者需要把容器内的数据进行备份,甚至多个容器之间进行数据的共享,这必然涉及容器的数据管理操作.容器中管理数据主要有两种方式:数据 ...