深度学习(十三) R-CNN Fast RCNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。object detection要解决的问题就是物体在哪里,是什么这整个流程的问题。然而,这个问题可不是那么容易解决的,物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,更何况物体还可以是多个类别。
object detection技术的演进:
RCNN->SppNET->Fast-RCNN->Faster-RCNN
从图像识别的任务说起
这里有一个图像任务:
既要把图中的物体识别出来,又要用方框框出它的位置。
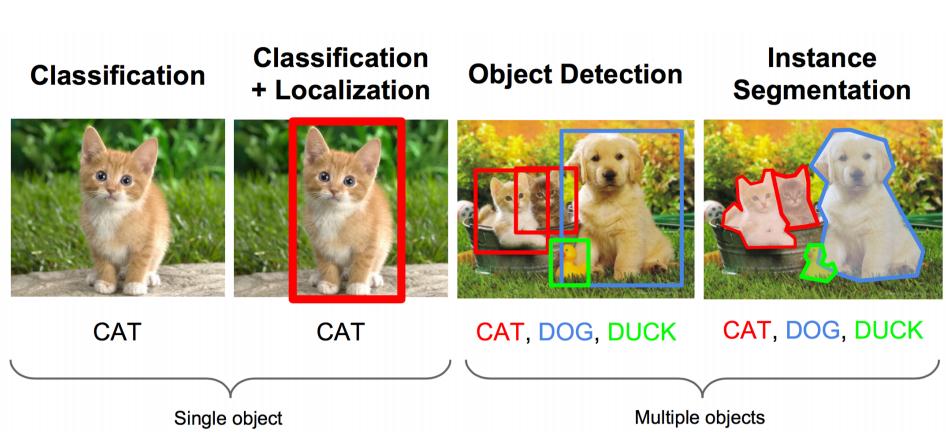
上面的任务用专业的说法就是:图像识别+定位
图像识别(classification):
输入:图片
输出:物体的类别
评估方法:准确率

定位(localization):
输入:图片
输出:方框在图片中的位置(x,y,w,h)
评估方法:检测评价函数 intersection-over-union ( IOU )

IOU的定义
因为没有搞过物体检测不懂IOU这个概念,所以就简单介绍一下。物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。

IOU定义了两个bounding box的重叠度,如下图所示:
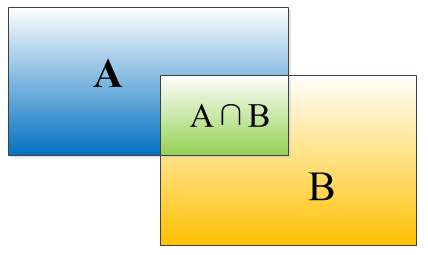
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=SI/(SA+SB-SI)
例子:
先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
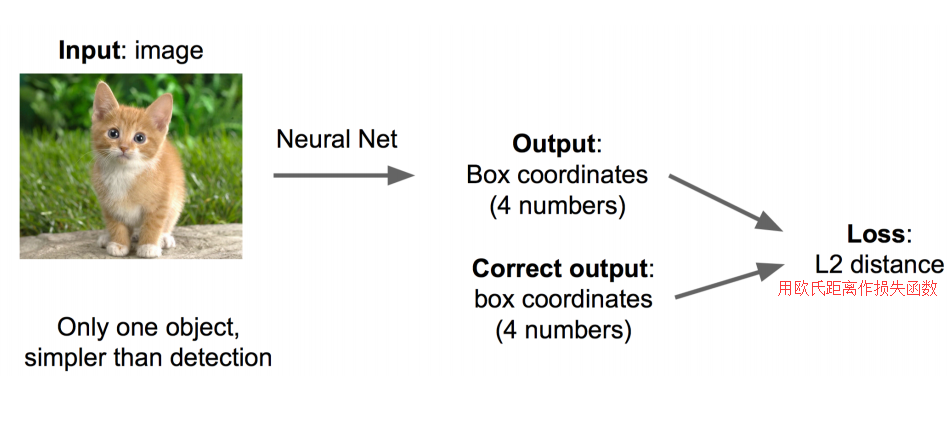
思路一:看做回归问题
看做回归问题,我们需要预测出(x,y,w,h)四个参数的值,从而得出方框的位置。
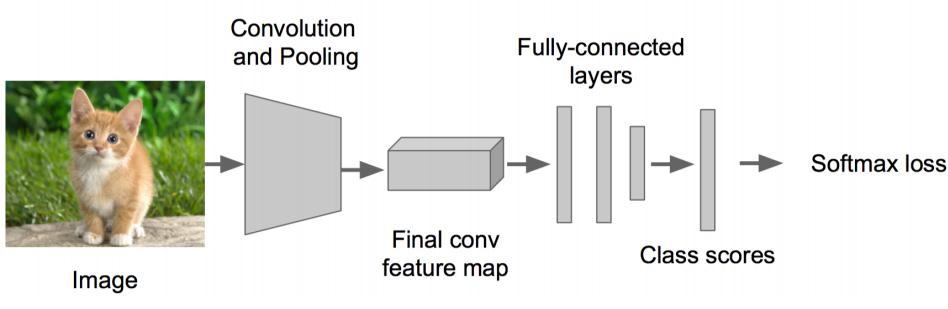
步骤1:
• 先解决简单问题, 搭一个识别图像的神经网络
• 在AlexNet VGG GoogleLenet上fine-tuning一下
步骤2:
• 在上述神经网络的尾部展开(也就说CNN前面保持不变,我们对CNN的结尾处作出改进:加了两个头:“分类头”和“回归头”)
• 成为classification + regression模式

步骤3:
• Regression那个部分用欧氏距离损失
• 使用SGD训练
步骤4:
• 预测阶段把2个头部拼上
• 完成不同的功能
这里需要进行两次fine-tuning
第一次在ALexNet上做,第二次将头部改成regression head,前面不变,做一次fine-tuning
Regression的部分加在哪?
有两种处理方法:
• 加在最后一个卷积层后面(如VGG)
• 加在最后一个全连接层后面(如R-CNN)
regression太难做了,应想方设法转换为classification问题。
regression的训练参数收敛的时间要长得多,所以上面的网络采取了用classification的网络来计算出网络共同部分的连接权值。
思路二:取图像窗口
• 还是刚才的classification + regression思路
• 咱们取不同的大小的“框”
• 让框出现在不同的位置,得出这个框的判定得分
• 取得分最高的那个框
左上角的黑框:得分0.5

右上角的黑框:得分0.75

左下角的黑框:得分0.6

右下角的黑框:得分0.8

根据得分的高低,我们选择了右下角的黑框作为目标位置的预测。
注:有的时候也会选择得分最高的两个框,然后取两框的交集作为最终的位置预测。
疑惑:框要取多大?
取不同的框,依次从左上角扫到右下角。非常粗暴啊。
总结一下思路:
对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出这个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)
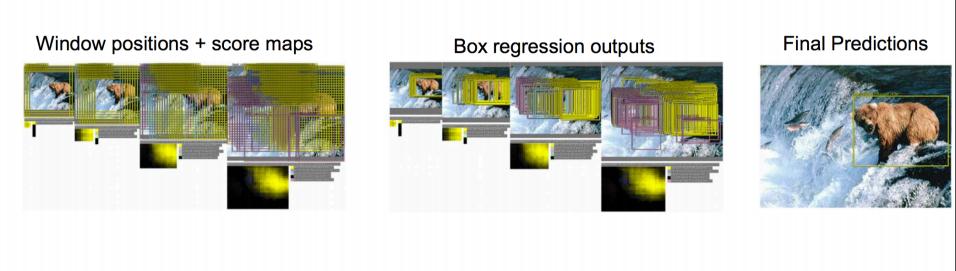
这方法实在太耗时间了,做个优化。
原来网络是这样的:
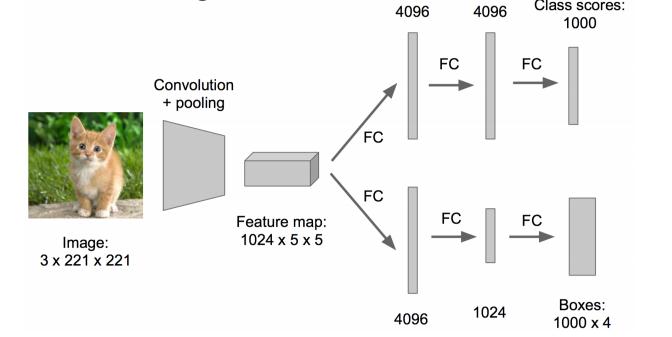
优化成这样:把全连接层改为卷积层,这样可以提提速
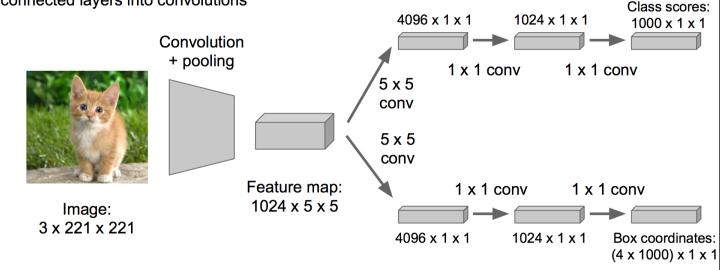
物体检测(Object Detection)
当图像有很多物体怎么办的?难度可是一下暴增啊。
那任务就变成了:多物体识别+定位多个物体
那把这个任务看做分类问题?

看成分类问题有何不妥?
• 你需要找很多位置, 给很多个不同大小的框
• 你还需要对框内的图像分类
• 当然, 如果你的GPU很强大, 恩, 那加油做吧…
看做classification, 有没有办法优化下?我可不想试那么多框那么多位置啊!
有人想到一个好方法:
找出可能含有物体的框(也就是候选框,比如选1000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举的所有框了。

大牛们发明好多选定候选框的方法,比如EdgeBoxes和Selective Search。
以下是各种选定候选框的方法的性能对比。
R-CNN
基于以上的思路,RCNN的出现了。
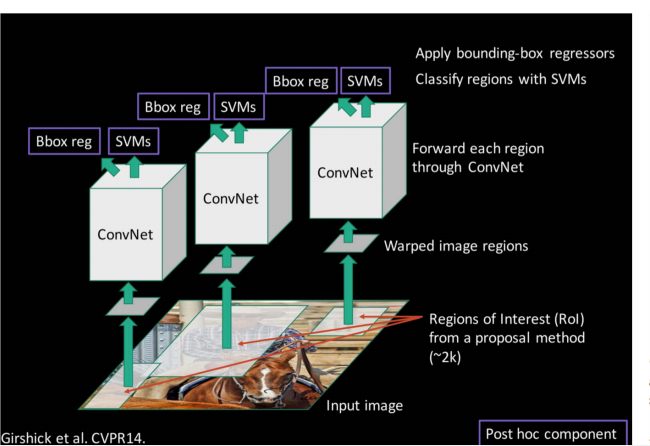
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
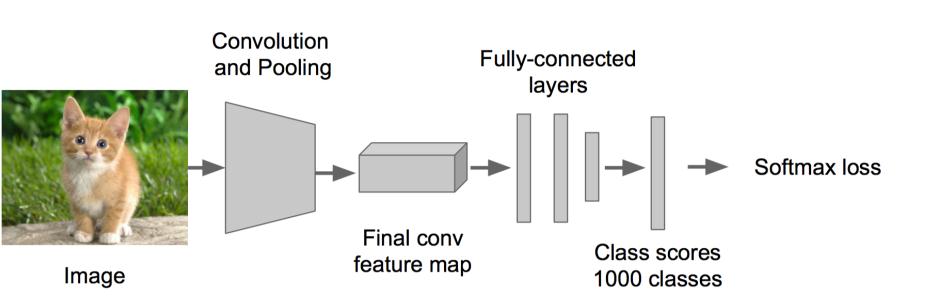
步骤二:对该模型做fine-tuning
• 将分类数从1000改为20(21位20个类别加上整张图片背景)
• 去掉最后一个全连接层
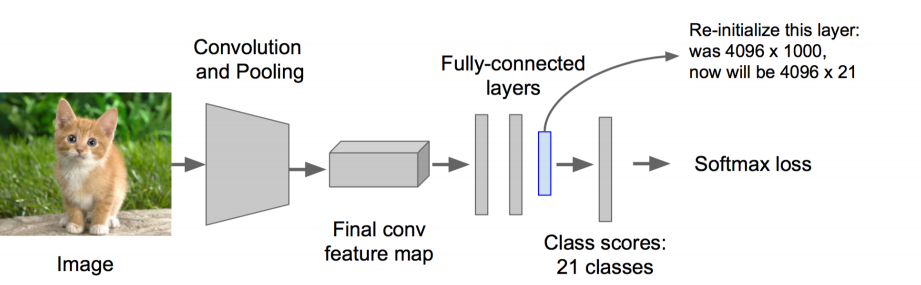
步骤三:特征提取
• 提取图像的所有候选框(选择性搜索)
• 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘

步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative
比如下图,就是狗分类的SVM

步骤五:使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。

RCNN的进化中SPP Net的思想对其贡献很大,这里也简单介绍一下SPP Net。
SPP Net
SPP:Spatial Pyramid Pooling(空间金字塔池化)
它的特点有两个:
1.结合空间金字塔方法实现CNNs的对尺度输入。
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。
如下图所示,在卷积层和全连接层之间加入了SPP layer。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
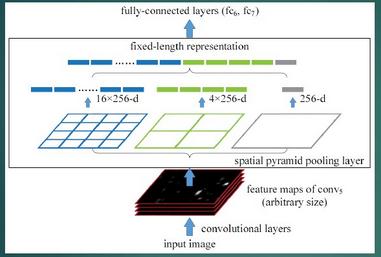
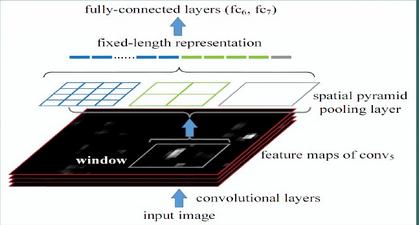
2.只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。
所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框zaifeature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。
Fast R-CNN
SPP Net真是个好方法,R-CNN的进阶版Fast R-CNN就是在RCNN的基础上采纳了SPP Net方法,对RCNN作了改进,使得性能进一步提高。
R-CNN与Fast RCNN的区别有哪些呢?
先说RCNN的缺点:即使使用了selective search等预处理步骤来提取潜在的bounding box作为输入,但是RCNN仍会有严重的速度瓶颈,原因也很明显,就是计算机对所有region进行特征提取时会有重复计算,Fast-RCNN正是为了解决这个问题诞生的。
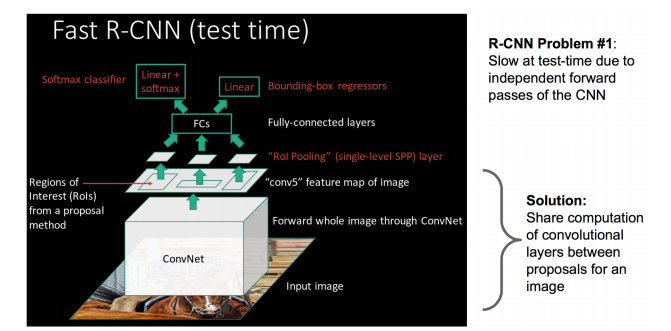
大牛提出了一个可以看做单层sppnet的网络层,叫做ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,而我们知道,conv、pooling、relu等操作都不需要固定size的输入,因此,在原始图片上执行这些操作后,虽然输入图片size不同导致得到的feature map尺寸也不同,不能直接接到一个全连接层进行分类,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,再通过正常的softmax进行类型识别。另外,之前RCNN的处理流程是先选图,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast-RCNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。
画一画重点:
R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。
大缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
原来的方法:许多候选框(比如两千个)-->CNN-->得到每个候选框的特征-->分类+回归
现在的方法:一张完整图片-->CNN-->得到每张候选框的特征-->分类+回归
所以容易看见,Fast RCNN相对于RCNN的提速原因就在于:不过不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
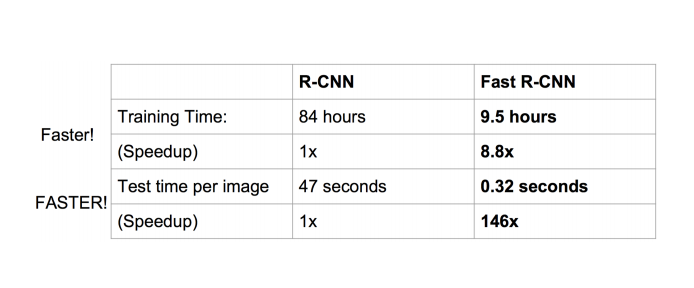
在性能上提升也是相当明显的:
深度学习(十三) R-CNN Fast RCNN的更多相关文章
- 深度学习论文笔记:Fast R-CNN
知识点 mAP:detection quality. Abstract 本文提出一种基于快速区域的卷积网络方法(快速R-CNN)用于对象检测. 快速R-CNN采用多项创新技术来提高训练和测试速度,同时 ...
- 使用colab运行深度学习gpu应用(Mask R-CNN)实践
1,目的 Google Colaboratory(https://colab.research.google.com)是谷歌开放的一款研究工具,主要用于机器学习的开发和研究.这款工具现在可以免费使用, ...
- 深度学习系列之CNN核心内容
导读 怎么样来理解近期异常火热的深度学习网络?深度学习有什么亮点呢?答案事实上非常简答.今年十月份有幸參加了深圳高交会的中科院院士论坛.IEEE fellow汤晓欧做了一场精彩的报告,这个问题被汤大神 ...
- 【深度学习篇】---CNN和RNN结合与对比,实例讲解
一.前述 CNN和RNN几乎占据着深度学习的半壁江山,所以本文将着重讲解CNN+RNN的各种组合方式,以及CNN和RNN的对比. 二.CNN与RNN对比 1.CNN卷积神经网络与RNN递归神经网络直观 ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- 深度学习笔记之CNN(卷积神经网络)基础
不多说,直接上干货! 卷积神经网络(ConvolutionalNeural Networks,简称CNN)提出于20世纪60年代,由Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经 ...
- 深度学习二、CNN(卷积神经网络)概念及理论
一.卷积神经网络(CNN) 1.常见的CNN结构有:LeNet-5.AlexNet.ZFNet.VGGNet.ResNet等.目前效率最高的是ResNet. 2.主要的层次: 数据输入层:Input ...
- 【深度学习系列】CNN模型的可视化
前面几篇文章讲到了卷积神经网络CNN,但是对于它在每一层提取到的特征以及训练的过程可能还是不太明白,所以这节主要通过模型的可视化来神经网络在每一层中是如何训练的.我们知道,神经网络本身包含了一系列特征 ...
- 学习笔记︱深度学习以及R中并行算法的应用(GPU)
笔记源于一次微课堂,由数据人网主办,英伟达高级工程师ParallerR原创.大牛的博客链接:http://www.parallelr.com/training/ 由于本人白痴,不能全部听懂,所以只能把 ...
- 深度学习论文翻译解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 标题翻译:基于区域提议(Regi ...
随机推荐
- redis修改端口号
为redis分配一个8888端口,操作步骤如下: 1.$REDIS_HOME/redis.conf重新复制一份,重命名为redis8888.conf. 2.打开redis8888.conf配置文件,找 ...
- CAS实战の获取多用户信息
先列出版本号: 服务端版本:cas server 4.0.0 客户端版本:cas client 3.3.3 cas server step1:先将primaryPrincipalResolver be ...
- 咏南树形下拉列表数据敏感控件--TYNdbTreeList
咏南树形下拉列表数据敏感控件--TYNdbTreeList 软件系统拥有自己通用的下拉列表控件可以大大地加速系统的开发和易用性. 控件支持DELPHI5及以上版本安装并使用. 控件的用法: proce ...
- .Net工程师面试笔试宝典
.Net工程师面试笔试宝典 传智播客.Net培训班内部资料 http://net.itcast.cn 这套面试笔试宝典是传智播客在多年的教学和学生就业指导过程中积累下来的宝贵资料,大部分来自于学员从面 ...
- EJB3.0 EJB开发消息驱动bean
(7)EJB3.0 EJB开发消息驱动bean JMS 一: Java消息服务(Java Message Service) 二:jms中的消息 消息传递系统的中心就是消息.一条 Message 由三个 ...
- nginx 用户登录认证
1.配置nginx server { listen ; server_name kibana.×××.com; location / { auth_basic "secret"; ...
- linux bash变量替换(# ## % %% / //)
VAR=hahaha echo ${VAR#*h} # ahaha 从前向后匹配删除 VAR=hahaha echo ${VAR##*h} # a 贪婪模式,从前向后匹配删除所有 VAR=hahaha ...
- UWP开发入门(七)——下拉刷新
本篇意在给这几天Win10 Mobile负面新闻不断的某软洗地,想要证明实现一个简单的下拉刷新并不困难.UWP开发更大的困难在于懒惰,缺乏学习的意愿.而不是“某软连下拉刷新控件都没有”这样的想法. 之 ...
- Java - io输入输出流 --转换流
转换流 转换输出流 OutputStreamWriter: 说明: /* * OutputStreamWriter 这个类的作用 * 就是指定输出流的编码格式 * 这个类的构造方法 需要传递 一个输 ...
- Jetty实战之 嵌入式Jetty运行web app
Jetty实战之 嵌入式Jetty运行web app 博客分类: 应用服务器 jettywar 转载地址:http://blog.csdn.net/kongxx/article/details/72 ...