Caffe入门随笔
Caffe入门随笔
分享一下自己入门机器学习的一些资料:
(1)课程,最推荐Coursera上的Andrew NG的Machine Learning,最好注册课程,然后跟下来。
其次是华盛顿大学的Machine Learning系列课程,一共有6门,包括毕业设计
(2)书籍: 机器学习(周志华西瓜书)、机器学习实战、统计学习方法(李航)、集体智慧编程、数学之美(吴军)
(3)微博
@余凯_西二旗民工;@老师木;@梁斌penny;@张栋_机器学习;@邓侃;@大数据皮东;@djvu9;@陈天奇怪
(4)知乎
@贾扬清;@Naiyan Wang; @李文哲;@陈然
热门回答 机器学习该怎么入门?<https://www.zhihu.com/question/20691338>
安装和配置caffe
环境:台式机 + 无GPU + Ubuntu14.04
纯CPU简易安装过程:
(1) 下载相关依赖包(在ubuntu下都由apt-get大法搞定)
sudo apt-get install libatlas-base-dev
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev
sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler
(2) github上下载最新的caffe源码
git clone https://github.com/BVLC/caffe.git
cd caffe
cp Makefile.config.example Makefile.config
(3) 修改Makefile.config,选择CPU_ONLY选项,保存
(4) 测试
make all -j4
make test
make runtest
安装配置心得
纯CPU版因为不涉及显卡和Cuda安装的问题,因此安装过程中比较简单。主要遇到的问题是相关依赖包的缺失问题。
整理了下用到的依赖包和作用:
(1) Protobuffer
谷歌开发的一种可以实现内存与非易失存储介质(如硬盘)交换的协议接口。Caffe源码中大量使用protobuffer作为权值和模型参数的载体。使用protobuffer可以跨语言(C++/java/python)传递相同的数据结构。
(2) Boost
C++准标准库,功能强大,跨平台,构造精巧,开源免费。在caffe中主要使用了Boost库中的智能指针,其自带引用计数功能,可避免共享指针时造成的内存泄漏和多次释放。
(3) GFLAGS
主要起到命令行参数解析的作用,与protobuffer功能类似,只是参数输入源不同。
(4) GLOG
谷歌开发的用于记录应用程序日志的实用库,提供基于C++标准输入输出的流形式接口,记录可以选择的不同的日志级别,将重要日志和普通日志分开。
(5) BLAS
基本线性代数库。最常用的有Openblas, Atlas, Intel Mkl等,安装相应的版本后,可以在caffe的config文件中配置
(6) HDF5
美国国家高级计算中心为了满足各种领域研究需求而研制的一种能高效存储和分发科学数据的新型数据格式。可以存储不同类型的图像和数码数据文件,在不同的机器上传输。Caffe训练模型可以保存为默认的protobuffer格式或者hdf5格式。
(7) Lmdb和leveldb
在caffe中主要的作用是数据库管理,将形形色色的原始数据转换为统一的key-value存储,方便caffe的datalayer进行读取。
Caffe Demo
http://blog.sina.com.cn/s/blog_5d36d8e00102uya1.html
参照薛开宇的博客,在caffe的example下跑一些demo
以caffe/example/cifar10目录下的cifar数据集demo为例,我的安装目录是~/software/caffe
(1)获取数据集和计算均值文件
cd ~/software/caffe/data/cifar10
./get_cifar10.sh
cd ~/software/caffe/examples/cifar10
./create_cifar10.sh
运行之后,将会在cifar10目录下会出现:
两个文件夹
cifar10_train_lmdb/
cifar10_test_lmdb/
一个数据库图像均值二进制文件
mean.binaryproto
(2)训练cifar10数据集
写好参数设置的文件cifar10_quick_solver.prototxt和定义的文件cifar10_quick_train.prototxt和cifar10_quick_test.prototxt后运行 train_quick.sh即可
(3)观察结果
当5000次迭代之后,正确率约为75%,模型的参数存储在二进制protobuf格式在cifar10_quick_iter_5000,然后,这个模型就可以用来运行在新数据上了。
Caffe源码阅读
参考知乎上的一个问题,深度学习caffe的代码怎么读
https://www.zhihu.com/question/27982282
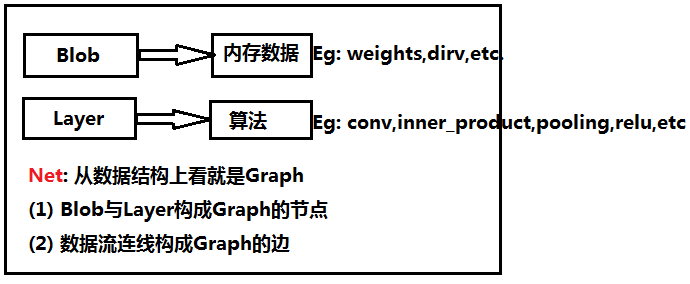
要读懂caffe,首先要熟悉Blob,Layer,Net,Solver这几个大类。这四个大类自下而上,环环相扣,贯穿了整个caffe的结构。
(1)Blob:
作为数据传输的媒介,无论是网络权重参数,还是输入数据,都是转化为Blob数据结构来存储
(2)Layer:
作为网络的基础单元,神经网络中层与层间的数据节点、前后传递都在该数据结构中被实现,层类种类丰富,比如常用的卷积层、全连接层、pooling层等等,大大地增加了网络的多样性
(3)Net:
作为网络的整体骨架,决定了网络中的层次数目以及各个层的类别等信息
Blob,Layer和Net的关系可以用下图来描述:
(4)Solver:
作为网络的求解策略,涉及到求解优化问题的策略选择以及参数确定方面,修改这个模块的话一般都会是研究DL的优化求解的方向。
prototxt文件
在caffe中,要训练一个网络,至少要包含2个prototxt文件:
1. 一个是描述Net结构(“Blob+Layers+数据流”构成)的文件
2. 一个是描述训练算法的Solver文件
例如,cifar10中的描述Solver的prototxt

1 # reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
2 # The train/test net protocol buffer definition
3 net: "examples/cifar10/cifar10_quick_train_test.prototxt"
4 # test_iter specifies how many forward passes the test should carry out.
5 # In the case of MNIST, we have test batch size 100 and 100 test iterations,
6 # covering the full 10,000 testing images.
7 test_iter: 100
8 # Carry out testing every 500 training iterations.
9 test_interval: 500
10 # The base learning rate, momentum and the weight decay of the network.
11 base_lr: 0.001
12 momentum: 0.9
13 weight_decay: 0.004
14 # The learning rate policy
15 lr_policy: "fixed"
16 # Display every 100 iterations
17 display: 100
18 # The maximum number of iterations
19 max_iter: 4000
20 # snapshot intermediate results
21 snapshot: 4000
22 snapshot_format: HDF5
23 snapshot_prefix: "examples/cifar10/cifar10_quick"
24 # solver mode: CPU or GPU
25 solver_mode: CPU
Caffe代码快速梳理
Caffe是基于C++编写的深度学习框架,大量使用了类的封装、继承、多态,阅读Caffe的源码也可以很好的学习C++。
参考《21天实战Caffe》,开始阅读Caffe的源码
在Caffe的根目录下执行 tree 命令,即可查看caffe的整个目录结构:
tree -d
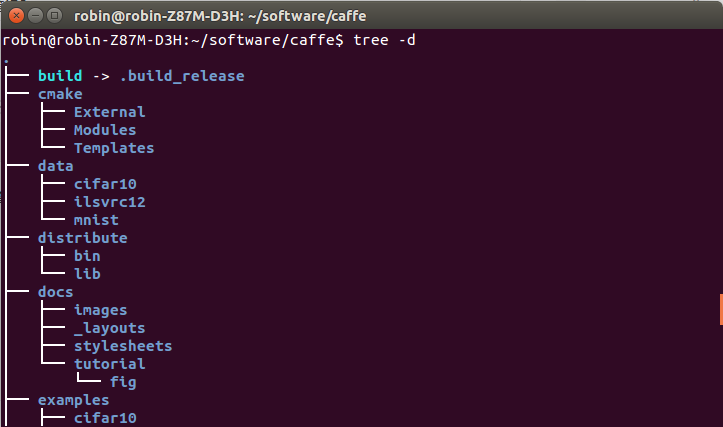
重点关注include/ src/ 和 tool/3个子目录
借鉴别人经验,一般来说,阅读Caffe源码的4步:
(1)看src/caffe/proto/caffe.proto,了解基本的数据结构内存对象和磁盘文件的映射关系
(2)看头文件
(3)有针对性地看cpp和cu文件
(4)编写各类工具,集成到caffe内部
菜鸟刚刚起步,感觉Caffe的源码写的还是很清晰的,希望以后可以耐心的好好啃吧。
Caffe网络结构可视化
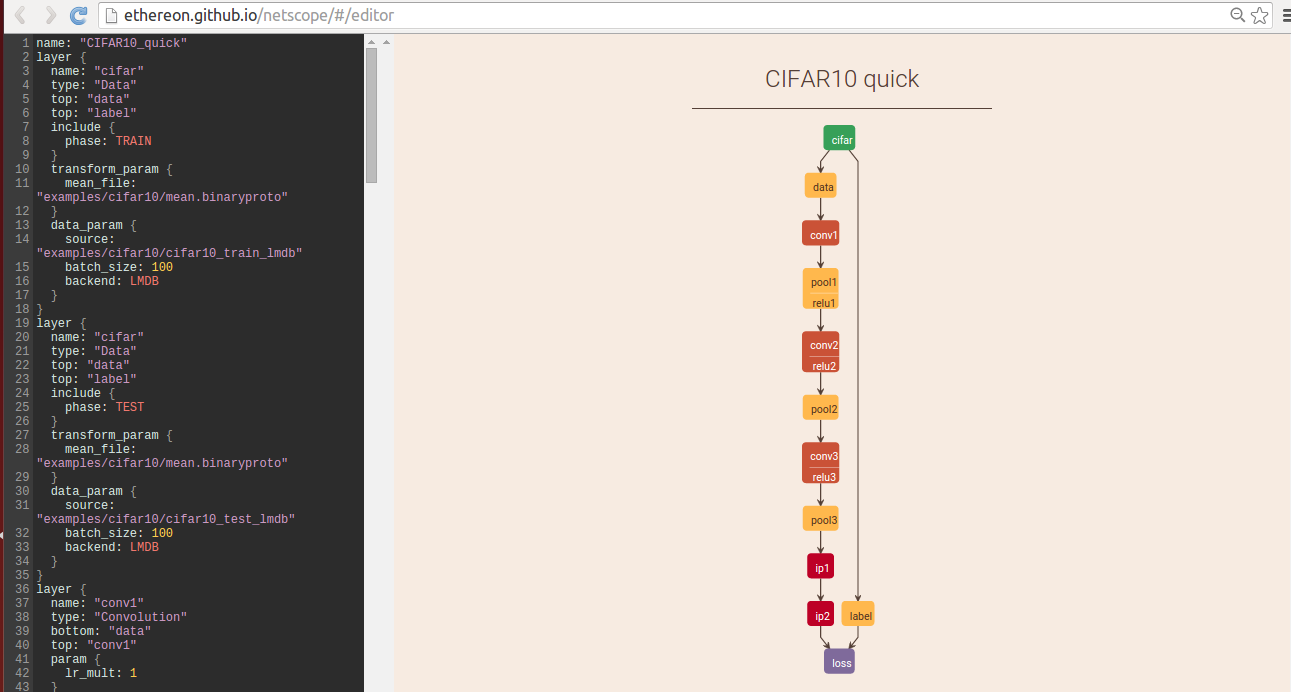
推荐可视化网站 <http://ethereon.github.io/netscope/#/editor>
CNN model的具体设置在prototxt文件里面,将其内容复制到上面的网站即可看到网络结构,方便调整和检查网络连接
就拿Cifar10数据集来说,找到caffe/examples/cifar10下的网络定义prototxt文件,粘贴到网上左边,然后Shilf+Enter,即可直观看到网络结构:
Caffe的Python开发
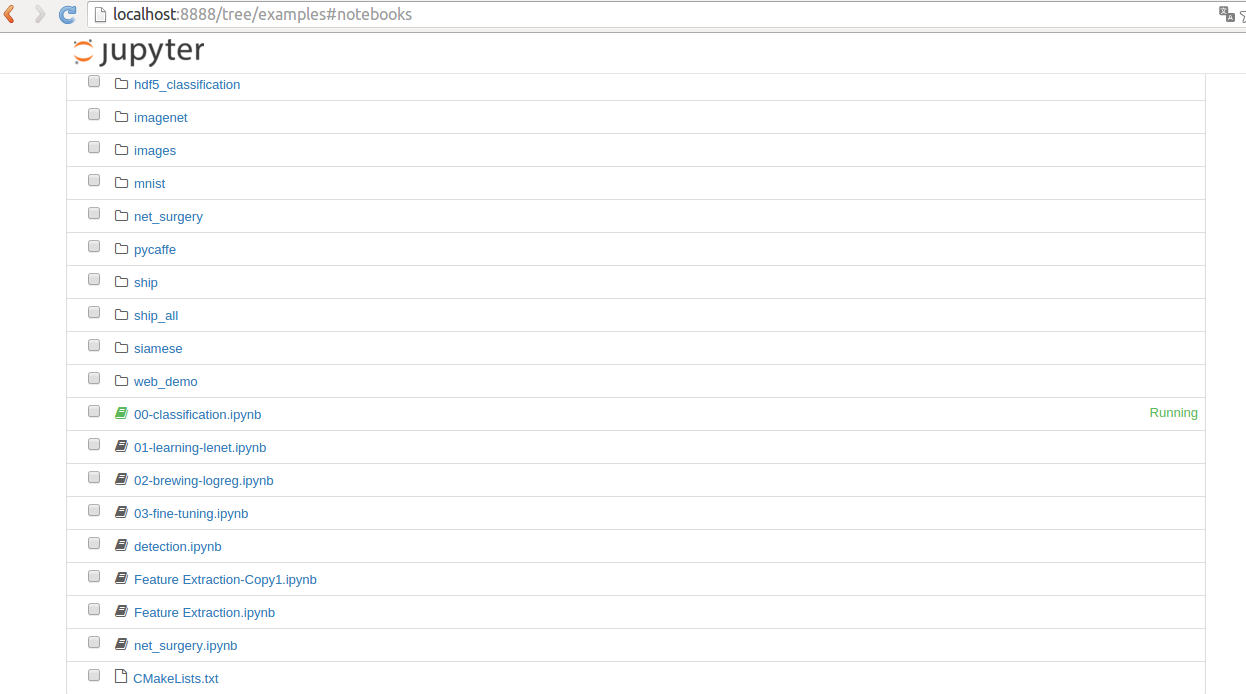
ipython notebook可以说是python开发深度学习的一个利器了
进入caffe的根目录,输入:
ipython notebook &
然后进入caffe的example目录,自带了一些python写的demo
Caffe入门随笔的更多相关文章
- Deep Learning 29: caffe入门学习
1.跑教程:深度学习(六)caffe入门学习,上面有比较好的注释 .prototxt文件:网络结构文件 solver.prototxt:网络求解文件 net: "examples/mnist ...
- html标签学习入门 随笔
Html学习入门 随笔1: HTML 标题 HTML 标题(Heading)是通过 <h1> - <h6> 等标签进行定义的. 标题仅用于标题文本 不应该被使用在加粗字 ...
- caffe入门-人脸检测1
最近刚入门caffe,跟着视频做了一个简单人脸检测.包括人脸二分类模型+方框框出人脸. 人脸二分类模型 1. 收集数据 我用的是lfw数据集,总共有13233张人脸图片.非人脸数据有两种选择.1. 用 ...
- Caffe入门:对于抽象概念的图解分析
Caffe的几个重要文件 用了这么久Caffe都没好好写过一篇新手入门的博客,最近应实验室小师妹要求,打算写一篇简单.快熟入门的科普文. 利用Caffe进行深度神经网络训练第一步需要搞懂几个重要文件: ...
- Caffe入门与应用 by GX
深度学习几大工具:Theano(基于python),Torch,Caffe(用c++写的),Tensor flow,CNTK:caffe是比较流行的深度学习的框架 caffe特点:特别适合于新手,由于 ...
- ASP.NET前端解决方案之一:Ext.Net入门随笔1
最近因为公司需要,进一步研发了Ext.Net技术,这里先做一个简明的介绍,给自己和大家记录一个初步的概念. 什么是Ext Ext就是ExtJS,引用下百度的解释:“ExtJS是一种主要用于创建前端用户 ...
- caffe学习--caffe入门classification00学习--ipython
首先,数据文件和模型文件都已经下载并处理好,不提. cd "caffe-root-dir " ----------------------------------分割线---- ...
- git for windows 入门随笔
引言: Git 是当前最流行的集中化的版本控制程序之一(版本控制是一种记录若干文件内容变化,以便将来查阅特定版本修订情况的系统),Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件 ...
- nodejs调试工具node-inspector入门随笔
最近打算玩玩node. 众所周知,在前端,调试代码有一众天然好工具——浏览器!特别是 chrome,使得 jser 们如鱼得水,玩得风生水起.但是到了node,情况就不一样了,js 代码不再运行在单纯 ...
随机推荐
- Default style sheet for HTML 4
http://www.w3.org/TR/CSS21/sample.html html, address, blockquote, body, dd, div, dl, dt, fieldset, f ...
- cron和crontab
crontab -l 列出目前的计划任务(时程表) crontab -e 编辑计划任务 计划任务的格式如下: f1 f2 f3 f4 f5 program 其中 f1 是表示分钟,f2 表示小时, ...
- 手动编译安装lamp之php
转自马哥教育讲课文档 三.编译安装php-5.4.8 1.解决依赖关系: 请配置好yum源(可以是本地系统光盘)后执行如下命令: # yum -y groupinstall "X Softw ...
- C#基础笔记(第二十二天)
1.单例模式1)将构造函数私有化2)提供一个静态方法,返回一个对象3)创建一个单例 2.XML可扩展的标记语言 HTMLXML:存储数据 不是单独.net的东西,是一个单独的,JAVA什么的都也用不需 ...
- Android App的破解技术有哪些?如何防止反编译?
现在最流行的App破解技术大多是基于一定相关技术的基础:如一定阅读Java代码的能力.有一些Android基础.会使用eclipse的一些Android调试的相关工具以及了解一些smali的语法规范 ...
- Ceph 的基础数据结构 [Pool, Image, Snapshot, Clone]
原文链接:http://www.cnblogs.com/sammyliu/p/4843812.html?utm_source=tuicool&utm_medium=referral 1 Poo ...
- python网络编程--管道,信号量,Event,进程池,回调函数
1.管道 加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行任务修改,即串行修改,速度慢了,但牺牲了速度却保证了数据安全. 文件共享数据实现进程间的通信,但问题是: 1.效率低(共享 ...
- 【12c OCP】CUUG OCP认证071考试原题解析(34)
34.choose two View the Exhibit and examine the structure of the PRODUCT_INFORMATION and INVENTORIES ...
- Python装饰器(函数)
闭包 1.作用域L_E_G_B(局部.内嵌.全局...): x=10#全局 def f(): a=5 #嵌套作用域 def inner(): count = 7 #局部变量 print a retur ...
- css 做幻灯片效果
设置一个div 盒子 <div class="ani"></div> 设置css 样式 .ani{ width:480px; height:320px; ...