MapReduce详解和WordCount模拟
最早接触大数据,常萦绕耳边的一个词「MapReduce」。它到底是什么,能做什么,原理又是什么?且听下文讲解。
是什么
MapReduce 即是一个编程模型,又是一个计算框架,它充分采用了分治的思想,将数据处理过程拆分成两步:Map 和 Reduce。用户只需要编写 map() 和 reduce() 函数,就能使问题的计算实现分布式,并在Hadoop上执行。
数据处理
MapReduce 操作数据的最小单位是一个键值对。map 端的主要输入是一对<key,value>值,经过 map 计算后输出一对<key,value>,然后将相同的 key 合并,形成<key,value 集合>,再将这个<key,value 集合>输入 reduce ,经过计算输出零个或多个<key,value>对。
两个重要的进程
JobTracker
JobTracker 在集群中负责任务调度和集群资源监控这两个功能。TaskTracker 通过周期性的心跳向 JobTracker 汇报当前的健康状况和状态,心跳中包括自身计算资源的信息、被占用的计算资源的信息和正在运行中的任务的状态信息。JobTracker 会根据各个 TaskTracker 周期性发送过来的心跳信息综合考虑TaskTracker 的资源余量、作业优先级、作业提交时间等因素,为 TaskTracker 分配合适的任务。
JobTracker 提供了一个基于 web 的管理界面,可以通过 JobTracker:50030 端口访问。
TaskTracker
TaskTracker 主要负责汇报心跳和执行 JobTracker 命令这两个功能。命令主要包括5种:启动命令、提交命令、杀死任务、杀死作业和重新初始化。
几个概念
作业(Job) 和 任务(Task)
MapReduce 作业是用户提交的最小单位,任务是 MapReduce 计算的最小单位。 简单讲,用户提交的是一个MapReduce作业,一个 MapReduce 作业可以被拆分成两种——Map 任务和 Reduce 任务。
槽(slot)
槽是Hadoop计算资源的表示模型,Hadoop 将各个节点上的多维度资源(CPU、内存等)抽象成一维度的槽。一个TaskTracker 能够启动的任务数量是由 TaskTracker 配置的任务槽决定的。
MapReduce 过程
一个MapReduce作业通常经过 input、map、combine、reduce、output 五个阶段。combine 阶段不一定发生,map输出的中间结果分发到 reduce 的过程被称为 shuffle。shuffle 阶段还会发生 copy 和 sort。

两幅重要的流程图
- map任务流程图
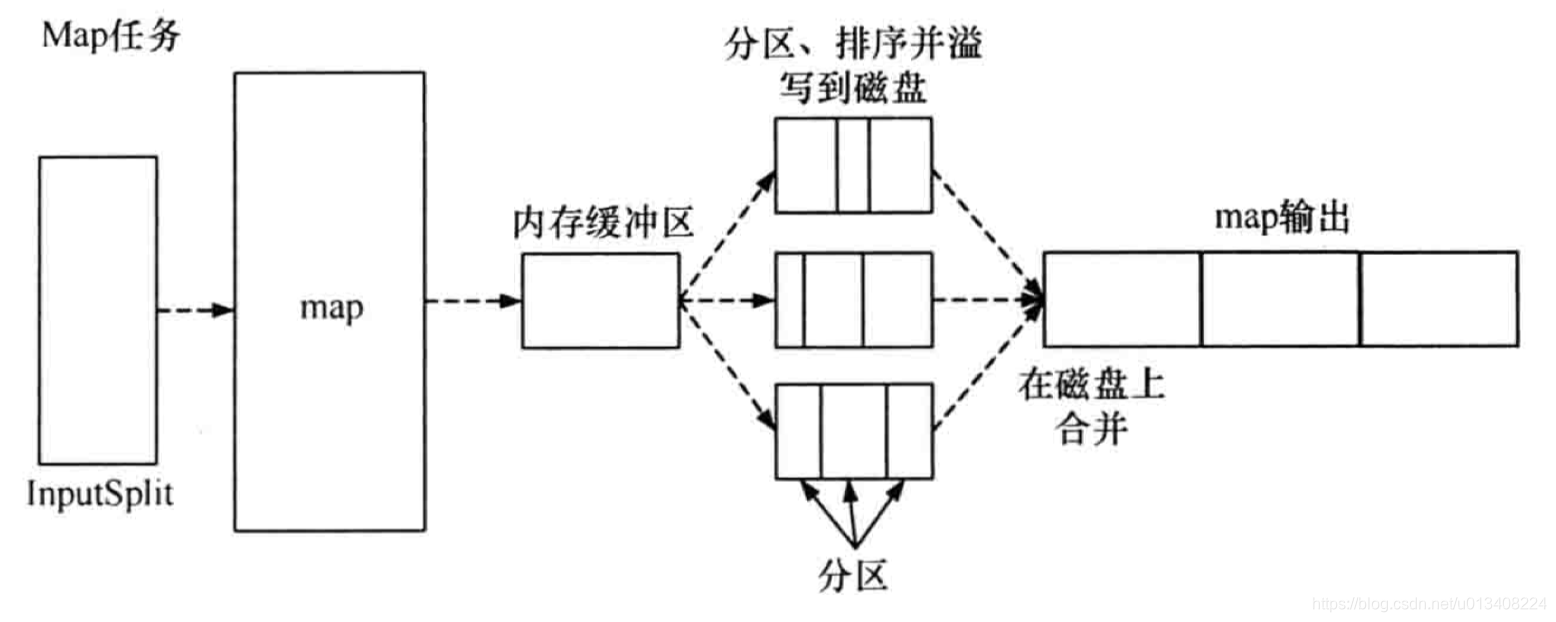
- reduce 任务流程图
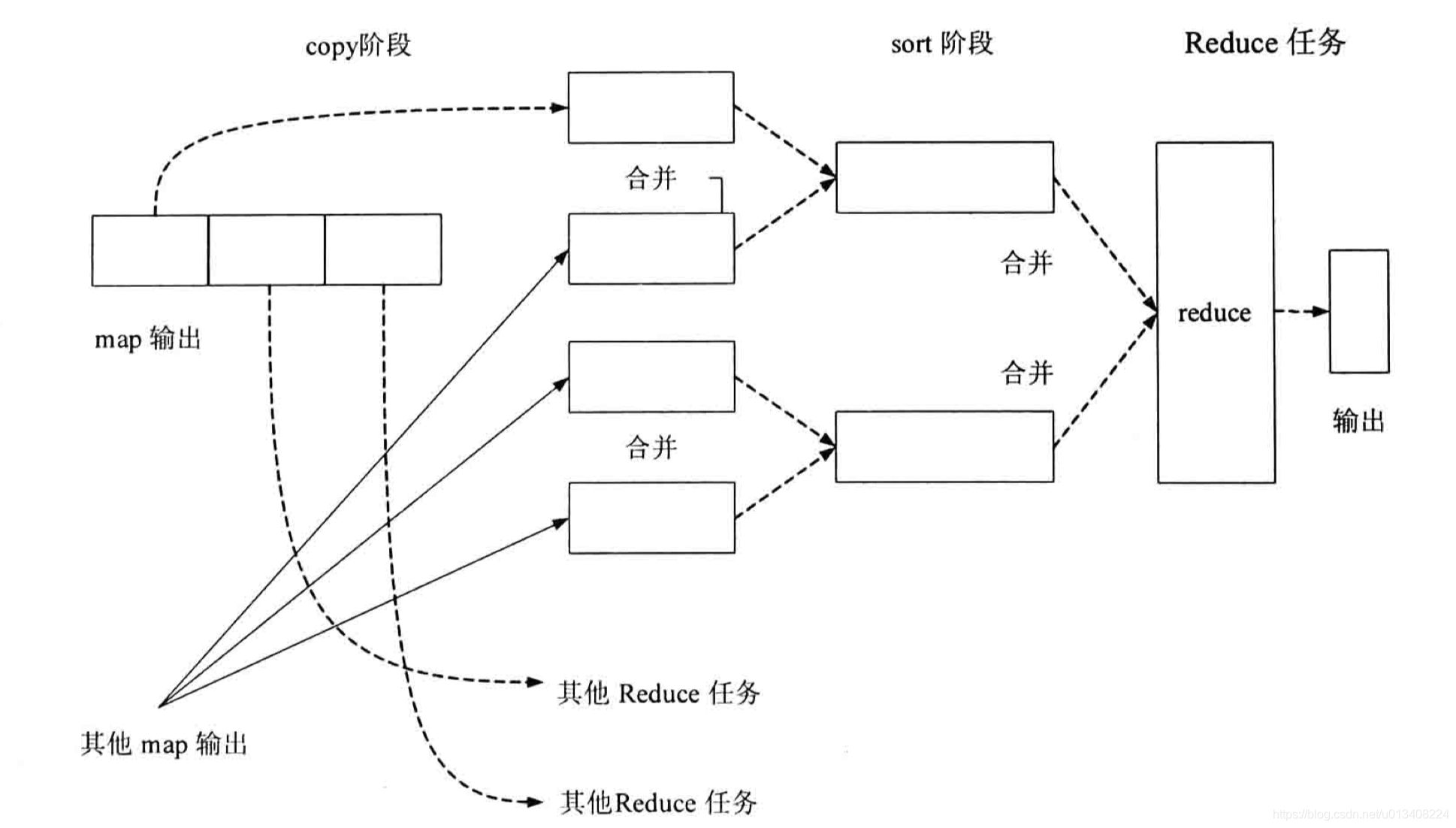
几个重要的阶段说明
map 函数处理后的中间结果会写到本地磁盘上,在刷写磁盘的过程中,还做了 partition 和 sort 操作。
map 函数输出时,并不是简单地刷写磁盘,为了保证 I/O 效率,采取了先写到内存的环形缓冲区,并做一次预排序。请结合map任务流程图理解。
partition
在分区阶段,通过对 key 取模,生成<partition,key,value>三元组,分区阶段进行了一次内排序。
MemoryBuffer
内存缓冲区,保存 map 的结果和 partition 处理后的结果,默认大小为100M,溢写阈值为80M。
spill(溢写)
内存缓冲区达到阈值时,溢写线程锁住这80M的缓冲区,开始将数据写到本地磁盘中,然后释放内存。
每次溢写都会生成一个数据文件,溢出的数据写到磁盘前会对数据进行 sort 以及合并(combine)。
combine
combine 对map 函数的输出结果进行早期聚合以减少传输的数据量,其作用其实和reduce 函数一样。combine 的过程发生在 spill(溢写) 阶段。
combine 能够提升程序性能,但并不是所有常见都适合使用 combine ,例如:求中值。
sort
MapReduce 计算框架主要用到了两种排序:快速排序和归并排序。在 Map 任务和 Reduce 任务的过程中,一共发生了三次排序操作:
- partition 过程中按照键值进行的内排序。
- map 任务完成之前,合并溢写文件产生输出文件时进行的一次 sort 操作。
- shuffle 过程的 sort 操作。
wordcount 实验模拟
map 端编程代码(map_a.py):
import sys
import re
p =re.compile(r'\w+')
for line in sys.stdin:
world_list =line.strip().split()
for word in world_list:
if len(word)<2:
continue
w_list =p.findall(word)
if len(w_list)>0:
w =w_list[0].lower()
print "%s\t%d"%(w,1)
reduce 端编程代码(red_b.py)
import sys
wt =0
cur_word =None
for line in sys.stdin:
word,cnt =line.strip().split('\t')
if cur_word ==None:
cur_word =word
if cur_word !=word:
print "%s\t%d"%(cur_word,wt)
wt =0
cur_word =word
wt =wt+int(cnt)
print "%s\t%d"%(cur_word,wt)
模拟命令
cat The_man_of_property.txt |python ./project/map_a.py | sort -k 1 |python ./project/red_b.py
输出显示
MapReduce详解和WordCount模拟的更多相关文章
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- 【大数据】Linux下安装Hadoop(2.7.1)详解及WordCount运行
一.引言 在完成了Storm的环境配置之后,想着鼓捣一下Hadoop的安装,网上面的教程好多,但是没有一个特别切合的,所以在安装的过程中还是遇到了很多的麻烦,并且最后不断的查阅资料,终于解决了问题,感 ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- 大数据入门第七天——MapReduce详解(一)入门与简单示例
一.概述 1.map-reduce是什么 Hadoop MapReduce is a software framework for easily writing applications which ...
- hadoop之mapreduce详解(基础篇)
本篇文章主要从mapreduce运行作业的过程,shuffle,以及mapreduce作业失败的容错几个方面进行详解. 一.mapreduce作业运行过程 1.1.mapreduce介绍 MapRed ...
- MapReduce 过程详解 (用WordCount作为例子)
本文转自 http://www.cnblogs.com/npumenglei/ .... 先创建两个文本文件, 作为我们例子的输入: File 1 内容: My name is Tony My com ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
- MapReduce:详解Shuffle过程(转)
/** * author : 冶秀刚 * mail : dennyy99@gmail.com */ Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapRedu ...
- MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
随机推荐
- Linux磁盘及文件系统(三)Linux文件系统
一.文件系统的组成 Linux常见的文件系统类型有ReiserFS,ext2,ext3,ext4,vfat,XFS等,文件系统是对一个存储设备上数据和元数据进行组织的机制.他的最终目的是把大量数据有组 ...
- Azure 部署K8S(二)
在"China Azure中部署Kubernetes(K8S)集群"一文中,我们使用的ACS Version及Kubernete Version版本都比较低,ACS Version ...
- 架构师养成记--22.客户端与服务器端保持连接的解决方案,netty的ReadTimeoutHandler
概述 保持客户端与服务器端连接的方案常用的有3种 1.长连接,也就是客户端与服务器端一直保持连接,适用于客户端比较少的情况. 2.定时段连接,比如在某一天的凌晨建立连接,适用于对实时性要求不高的情况. ...
- 索引(Awakening!)
orz写个索引,方便日后复习和补充. 目前笔记还不是很多,而且写得比较烂,望各位到访的巨佬谅解. 大概可以算作一个归纳总结? ……没链接的还没开始写或者没写完,而且不知道什么时候才能写完(咕咕咕) 一 ...
- SVN解决冲突的方法
SVN管理代码工具在群组合作开发的过程中,若多人同时修改一个文件,就会出现冲突的情况. 冲突演示: 有A.B两个用户,他们各自从svn服务器中检出了file.txt文件,此时A.B.服务器三个地方的f ...
- Mac 10.12为打开终端增加快捷键(转)
1.在实用工具中打开Automator.app 2.选择新建,然后选择服务 3.服务收到选择为没有输入 然后在左边侧栏中双击Run AppleScript(有些系统会显示运行 AppleScript) ...
- 关于Java的权限修饰符(public,private,protected,默认friendly)
以前对访问修饰符总是模棱两可,让自己仔细解释也是经常说不很清楚.这次要彻底的搞清楚. 现在总结如下: 一.概括总结 各个访问修饰符对不同包及其子类,非子类的访问权限 Java访问权限修饰符包含四个:p ...
- 【ORACLE】oracle 日志文件管理
修改Oracle重做日志文件大小 创建新的日志组1 删除旧的日志组0(旧的日志组状态需要是INACTIVE) 创建新的日志组2,组名为旧的日志组0的组名 删除日志组1 ---------------- ...
- (转)Centos7上部署openstack ocata配置详解
原文:http://www.cnblogs.com/yaohong/p/7601470.html 随笔-124 文章-2 评论-82 Centos7上部署openstack ocata配置详解 ...
- 微服务Kong(二)——快速入门
在本节中,您将学习如何管理您的KONG实例.首先,我们将指导您如何启动Kong,以便您能访问KONG的RESTful形式的管理界面,您可以通过它来管理您的API,consumers等.通过管理型API ...