【hive】count() count(if) count(distinct if) sum(if)的区别
表名: user_active_day (用户日活表)
表内容:
user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地区) partition_date(日期分区)
需求:
找出20180901至今的xxx地区的用户日活量以及新增用户量
思路:
筛选日期分区和地区,统计user_id的数量为用户日活量,统计user_is_new = 1的数量为新增用户量.
最开始写的hql语句
select partition_date,count(user_id),
count(if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
我们使用count(if())来进行筛选统计,但是效果并没有达到,出现的结果如下
20180901 16737 16737
根本就没有达到筛选的目的,为什么?
这就要从count的机制说起
首先count()是对数据进行计数,说白了就是你来一条数据我计数一条,我不关心你怎么分类,我只对数据计数
每条数据从if()函数出来,还是一条数据,所以count+1
所以count(user_id)跟count(if(user_id))没有任何的区别.
我们稍做修改
select partition_date,count(user_id),
count(distinct if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计,加了distinct去重
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 261
这次看着就像是对了吧,我们加了distinct进行去重
每次来一条数据先过if()然后再进行去重最后统计.但是实际上结果依旧是错误的.
我们来模拟一下筛选统计的过程
我们有这样四条数据
user_id user_is_new
1 1
2 0
3 1
4 0
表中的数据是一条一条遍历的,
(1)当user_id = 1的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 1),
然后我们把user_id = 1进行重复判断,我们用一个模拟容器来模拟去重,
从容器里找user_id = 1的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 1的数据放入,用于下条去重
(2)当user_id = 2的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现没有,不重复,所以通过我们把count+1,然后把0的数据放入,用于下条去重
(3)当user_id = 3的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 3),
然后我们把user_id = 3进行重复判断,
从容器里找user_id = 3的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 3的数据放入,用于下条去重
(4)当user_id = 4的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现重复,是之前user_id = 2的时候过if()转化成0的那条数据,所以count不执行
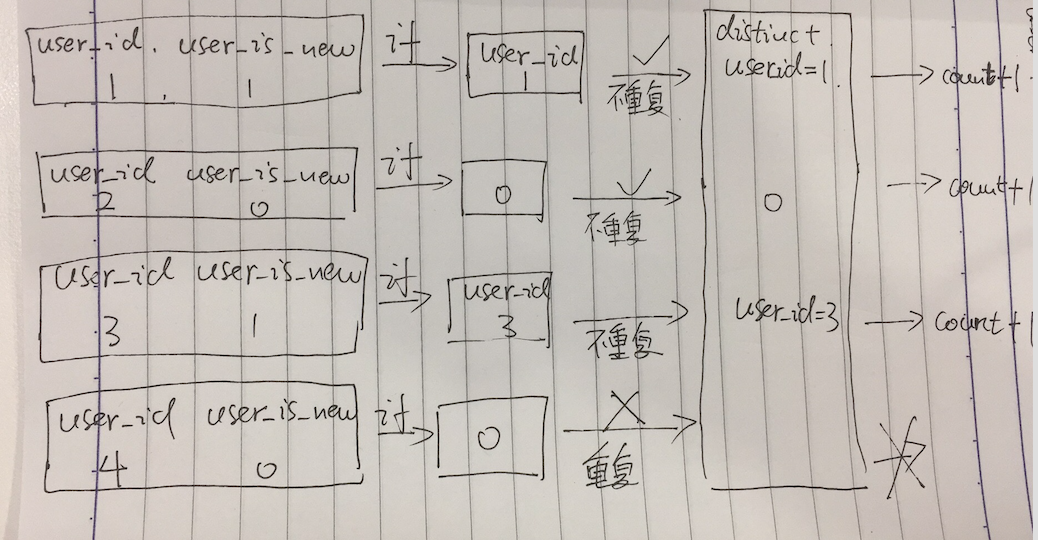
我们通过模拟count(distinct if)过程发现,在count的时候我们把不符合条件的最开始的那条语句也count进去了一次
导致最终结果比正确结果多了1.
我们在原基础语句上再减去1就是正确的hql语句
其实在日常中我们做分类筛选统计的时候一般是用sum来完成的,符合条件sum+1,不符合条件sum+0
select partition_date,count(user_id),
sum(if(user_is_new = 1, 1, 0)) --用sum进行筛选统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 260
sum(if)只试用于单个条件判断,如果筛选条件很多,我们可以用sum(case when then else end)来进行多条件筛选
注意,hive中并没有sum(distinct col1)这种使用方式,我们可以使用sum(col) group by col来达到相同效果.
【hive】count() count(if) count(distinct if) sum(if)的区别的更多相关文章
- 【MySQL】汇总数据 - avg()、count()、max()、min()、sum()函数的使用
第12章 汇总数据 文章目录 第12章 汇总数据 1.聚集函数 1.1.AVG()函数 avg() 1.2.COUNT()函数 count() 1.3. MAX()函数 max() 1.4.MIN() ...
- [MongoDB]count,gourp,distinct
摘要 上篇文章介绍了CRUD的操作,会了这些,基本上可以完成很多工作了.但如果遇到统计类的操作,那么就需要学习下本篇的内容了. 相关文章 [MongoDB]入门操作 [MongoDB]增删改查 cou ...
- 【优化】COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)
[优化]COUNT(1).COUNT(*).COUNT(常量).COUNT(主键).COUNT(ROWID).COUNT(非空列).COUNT(允许为空列).COUNT(DISTINCT 列名) 1. ...
- Django学习路17_聚合函数(Avg平均值,Count数量,Max最大,Min最小,Sum求和)基本使用
使用方法: 类名.objects.aggregate(聚合函数名('表的列名')) 聚合函数名: Avg 平均值 Count数量 Max 最大 Min 最小 Sum 求和 示例: Student.ob ...
- Oracle 中count(1) 和count(*) 的区别
count()与count(*)比较: 如果你的数据表没有主键,那么count()比count(*)快 如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快 如果你的表只有一 ...
- 【MySQL】技巧 之 count(*)、count(1)、count(col)
只看结果的话,Select Count(*) 和 Select Count(1) 两着返回结果是一样的. 假如表沒有主键(Primary key), 那么count(1)比count(*)快,如果有主 ...
- 关于count(1) 和 count(*)
Q:What is the difference between count(1) and count(*) in a sql queryeg.select count(1) from emp; an ...
- select count(*)和select count(1)的区别 (转)
A 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键 ...
- 【转载】Oracle 中count(1) 、count(*) 和count(列名) 函数的区别
1)count(1)与count(*)比较: 1.如果你的数据表没有主键,那么count(1)比count(*)快2.如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快3. ...
随机推荐
- Supermarket---poj456(贪心并查集优化)
题目链接:http://poj.org/problem?id=1456 题意是现有n个物品,每个物品有一个保质期和一个利润,现在每天只能卖一个商品,问最大的利润是多少,商品如果过期了就不能卖了: 暴力 ...
- Idea的注入和自动编译配置
实时编译: 第二个(防止编译时Autowired报错): 修改成:
- win安装mysql
在这讲解的是有关于通过zip解压安装MySQL的方法.有看了网上的其它的教程,讲的有些不够完善,也自己写一篇简述一下.个人还是建议看官方的参考文档非常之详细:https://dev.mysql.com ...
- mysql 表的增删改查
一.表介绍 表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段 对于一张表来说,字段是必须要有的. 数据表 类似于excel id,name,qq, ...
- python 面向对象 类 __doc__
用来打印类的描述信息 class A1(object): '''类的描述信息''' print(A1.__doc__) # 类的描述信息
- WebMagic简介和使用
概览 WebMagic是一款简单灵活的爬虫框架.基于它你可以很容易的编写一个爬虫. WebMagic项目代码分为核心和扩展两部分. 核心部分(webmagic-core)是一个精简的.模块化的爬虫实现 ...
- poi根据模板导出word文档
POI结构与常用类 Apache POI是Apache软件基金会的开源项目,POI提供API给Java程序对Microsoft Office格式档案读和写的功能. .NET的开发人员则可以利用NPOI ...
- POJ2115:C Looooops(一元线性同余方程)
题目: http://poj.org/problem?id=2115 要求: 会求最优解,会求这d个解,即(x+(i-1)*b/d)modm;(看最后那个博客的链接地址) 前两天用二元一次线性方程解过 ...
- POJ1523:SPF(无向连通图求割点)
题目:http://poj.org/problem?id=1523 题目解析: 注意题目输入输入,防止PE,题目就是求割点,并问割点将这个连通图分成了几个子图,算是模版题吧. #include < ...
- 【转】Deep Learning(深度学习)学习笔记整理系列之(七)
9.5.Convolutional Neural Networks卷积神经网络 卷积神经网络是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点.它的权值共享网络结构使之更类似于生物神经网 ...