Python 3 Anaconda 下爬虫学习与爬虫实践 (2)
下面研究如何让<html>内容更加“友好”的显示
之前略微接触的prettify能为显示增加换行符,提高可阅读性,用法如下:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.prettify())
同样,它也可以为其中的个别标签做专门的处理,比如对a标签进行处理
代码如下:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.a.prettify())
其输出结果如下:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">
新闻
</a>
可以发现a标签被清晰的打印了出来
关于bs4库的总结

下面进行信息标记的学习
信息标记的三种形式:
XML,YAML,JSON(JavaScript Object Notation)
XML是使用尖括号(最早通用标记语言,较为繁琐)
JSON(常用于接口处理,但其无法注释)
是有类型的键值对 key:value
比如 "name":"北京邮电大学"
"name"是键(key) “北京邮电大学”是值(value)
当值有多个的时候使用[,]组织,例如
"name":["北京邮电大学","清华大学"]
键值对之间可以嵌套使用,比如:
"name" : {
"newName":"北京理工大学",
"oldName":"延安自然科学院"
}
YAML(用于各类系统的配置文件,有注释易读)
无类型键值对(用缩进表达所属关系)
下面学习信息提取的一般方法
实例:
提取HTML中所有URL链接
思路:
1.搜索到所有<a>标签
2.解析<a>标签格式,提取href后的链接内容
下面是代码部分:
from bs4 import BeautifulSoup
import requests r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
效果为:
http://news.baidu.com
https://www.hao123.com
http://map.baidu.com
http://v.baidu.com
http://tieba.baidu.com
等等
成功爬取到所有链接。
这其中非常重要的查找函数为:
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串
attrs:对标签属性值的检索字符串,可标注属性检索
recursice:是否对子孙全部检索,默认True。
string: <>...</>中字符串区域的检索字符串
比如
print(soup.find_all(string=re.compile('Li')))
这里如果是soup.find_all('a')就可以找到所有a标签
soup.find_all(['a','b'])就可以找到所有的a标签和b标签
下面想找到b开头的所有式子,这时需要使用正则表达式,也就是re库,后面会详细学习,先用一下,代码如下:
from bs4 import BeautifulSoup
import requests
import re r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for tag in soup.find_all(re.compile('b')):
print(tag.name)
下面是查找
soup.find_all('p','course')查找p标签下类名为course的
suop.find_all(id='link1')查找id为link1的
由于find_all非常常见,所以
<tag>(...)等价于<tag>.find_all(...)
soup(...)等价于soup.find_all(...)
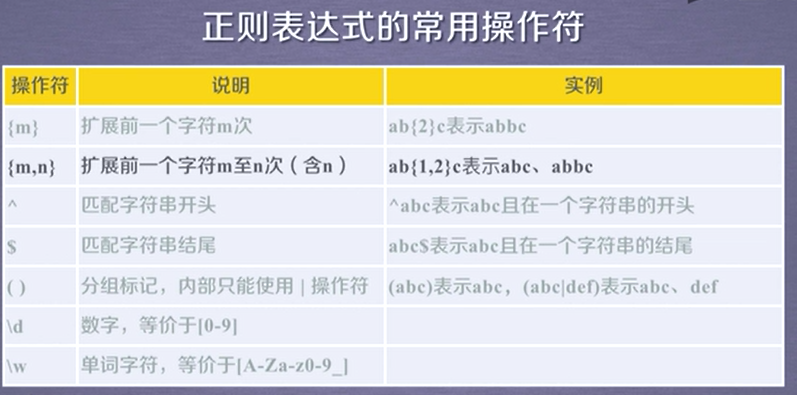
正则表达式:
regular expression RE
比如 'PY'开头,后续存在不多于10个字符,后续字符不能是'P'或者'Y'
正则表达式:PY[^PY]{0,10}
. 表示单个字符
[] 字符集,[abc]表示a,b,c


Python 3 Anaconda 下爬虫学习与爬虫实践 (2)的更多相关文章
- Python 3 Anaconda 下爬虫学习与爬虫实践 (1)
环境python 3 anaconda pip 以及各种库 1.requests库的使用 主要是如何获得一个网页信息 重点是 r=requests.get("https://www.goog ...
- Python爬虫学习——1.爬虫入门
HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法. HTTPS(Hypertext Transfer ...
- Python爬虫学习二------爬虫基本原理
爬虫是什么?爬虫其实就是获取网页的内容经过解析来获得有用数据并将数据存储到数据库中的程序. 基本步骤: 1.获取网页的内容,通过构造请求给服务器端,让服务器端认为是真正的浏览器在请求,于是返回响应.p ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- python 学习之爬虫练习
通过学习python,写两个简单的爬虫,没用线程,本地抓取速度还不错,有些瑕疵就是抓的图片有些显示不出来,代码做个笔记记录下: # -*- coding:utf-8 -*- import re imp ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- Django-CSRF的使用
1. 为什么要有csrf_token? 防止跨站请求伪造 2. Django中如何使用? urls.py: urlpatterns = [ # 测试跨站请求伪造 (CSRF) url(r'^csrf_ ...
- MPI编程——分块矩阵乘法(cannon算法)
https://blog.csdn.net/a429367172/article/details/88933877
- WinDbg调试 C# dmp
WinDbg C#调试 打开windbg,加载需要调试的c# dmp. 设置好sympath等. 查看蹦会的c#主进程依赖的.Net环境 可以查看进程名对应的*.config文件. 开始加载符号,假设 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- Nginx配置文件及模块解析
一.Nginx是什么? Nginx是一个基于c语言开发的高性能http服务器及反向代理服务器.由俄罗斯的程序设计师Igor Sysoev所开发,官方测试nginx能够支支撑5万并发链接,并且cpu.内 ...
- redis安装,windows,linux版本并部署服务
一.使用场景 项目中采用数据库访问量过大或访问过于频繁,将会对数据库带来很大的压力.redis数据库是以非关系数据库的出现,后来redis的迭代版本支持了缓存数据.登录session状 ...
- 如何不使用loop循环创建连续的数组
ES5 Array.apply(null,{length:100}) Object.keys(Array.apply(null,{length:100})); ES6 [...Array(100)]
- JS(JAVASCRIPT)
2018-08-17 * JAVASCRIPT(JavaScript简写js,文件的后缀名也是 demo.js)(*****) * javascript的简介 * js是基于对象和事件驱动的脚本语言, ...
- C# 使用密码连接Redis
单个Redis客户端: // 以StackOverflow.Redis的开源项目为例 ConnectionMultiplexer redis = ConnectionMultiplexer.Conne ...
- 本地搭建Apache Tomcat服务器
首先说下Apache和Tomcat的区别: 相同点:1.两者都是apache组织开发的 2.两者都有HTTP服务的功能 3.两者都是免费的 不同点:Apache是web服务器,专门提供HTTP服务的, ...