htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载
上次学了jsoup之后,发现一些动态生成的网页内容是无法抓取的,于是又学习了htmlunit,下面是抓取酷狗音乐与qq音乐链接的例子:
酷狗音乐:
import java.io.BufferedInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.URL;
import java.net.URLEncoder;
import java.util.UUID;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.jsoup.nodes.Element; import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient; public class worm7 {
private static String name="离骚";
public static WebClient getWebClient(boolean flag){
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_45);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setJavaScriptEnabled(flag);
webClient.getOptions().setTimeout(60000);
webClient.getOptions().setPrintContentOnFailingStatusCode(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
return webClient;
}
public static String getMp3Url(WebClient webClient){
FileOutputStream outputStream = null;
InputStream inputStream = null;
BufferedInputStream bis = null;
try {
Page page=webClient.getPage("http://songsearch.kugou.com/song_search_v2?"
+ "callback=jQuery112408395432201569397_1532930925600"
+ "&keyword="+URLEncoder.encode(name, "utf-8")
+ "&page=1"
+ "&pagesize=30"
+ "&userid=-1"
+ "&clientver="
+ "&platform=WebFilter"
+ "&tag=em"
+ "&filter=2"
+ "&iscorrection=1"
+ "&privilege_filter=0"
+ "&_="+System.currentTimeMillis());
//System.out.println(page.getWebResponse().getContentAsString());
//System.out.println(zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))"));
JSONObject job=JSONObject.parseObject("{"+zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("data");
System.out.println("job:"+job);
JSONArray list=job.getJSONArray("lists");
System.out.println("list"+list);
for(int i=0;i<list.size();i++){
String id1=list.getJSONObject(i).getString("FileHash");
String id2=list.getJSONObject(i).getString("AlbumID");
String detailUrl="http://www.kugou.com/yy/index.php?r=play/getdata"
+ "&hash="+id1
+ "&album_id="+id2
+ "&_="+System.currentTimeMillis();
Page page2=webClient.getPage(detailUrl);
JSONObject job2=JSONObject.parseObject(page2.getWebResponse().getContentAsString()).getJSONObject("data");
System.out.println("标题:"+job2.getString("audio_name"));
//System.out.println("歌词:"+job2.getString("lyrics"));
System.out.println("mp3:"+job2.getString("play_url")); String outImage = job2.getString("audio_name")+ ".mp3";
URL imgUrl = new URL(job2.getString("play_url"));//获取输入流
inputStream = imgUrl.openConnection().getInputStream();
//将输入流信息放入缓冲流提升读写速度
bis = new BufferedInputStream(inputStream);
//读取字节娄
byte[] buf = new byte[1024];
//生成文件
outputStream = new FileOutputStream("f://"+ outImage);
int size = 0;
//边读边写
while ((size = bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush(); }
} catch (Exception e) {
e.printStackTrace();
}
return name; }
private static String zzee(String str, String zz) {
String list = null;
Pattern p = Pattern.compile(zz);
Matcher m = p.matcher(str);
while (m.find()) {
list = m.group();
} return list;
}
public static void main(String[] args) {
WebClient webClient=getWebClient(false);
getMp3Url(webClient);
}
}
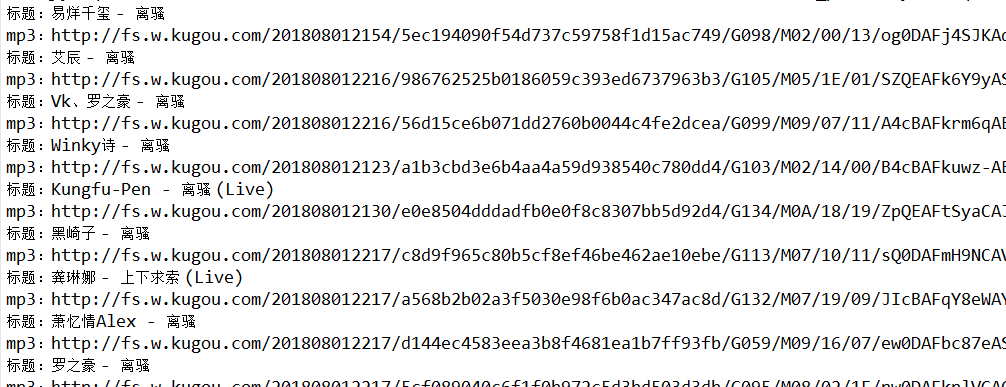
运行结果:
qq音乐抓取实例:
import java.io.BufferedInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.UUID;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.jsoup.nodes.Element; import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient; public class worm6 {
private static String name="离骚";
static String id1=null;
static String id2=null;
static String id3=null;
static String id4=null;
static String name1=null;
static String name2=null;
static String url = null;
static JSONObject job2=null;
public static WebClient getWebClient(boolean flag){
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_45);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setJavaScriptEnabled(flag);
webClient.getOptions().setTimeout(60000);
webClient.getOptions().setPrintContentOnFailingStatusCode(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
return webClient;
}
public static String getMp3Url(WebClient webClient){ try {
Page page=webClient.getPage("https://c.y.qq.com/soso/fcgi-bin/client_search_cp?"
+ "ct=24"
+ "&qqmusic_ver=1298"
+ "&new_json=1"
+ "&remoteplace=txt.yqq.center"
+ "&searchid=36047978388657978"
+ "&t=0"
+ "&aggr=1"
+ "&cr=1"
+ "&catZhida=1"
+ "&lossless=0"
+ "&p=1"
+ "&n=20"
+ "&w="+URLEncoder.encode(name, "utf-8")
+ "&g_tk=5381"
+ "&jsonpCallback=MusicJsonCallback6176591962889693"
+ "&loginUin=0"
+ "&hostUin=0"
+ "&format=jsonp"
+ "&inCharset=utf8"
+ "&outCharset=utf-8"
+ "¬ice=0"
+ "&platform=yqq"
+ "&needNewCode=0"
);
//System.out.println("page:"+page);
//System.out.println("------"+page.getWebResponse().getContentAsString());
//System.out.println("======"+zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")); JSONObject job=JSONObject.parseObject("{"+zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("data");
//System.out.println("job:"+job);
String job0=job.getString("song");
//System.out.println("job0"+job0);
job=JSON.parseObject(job0);
JSONArray list=job.getJSONArray("list");
//System.out.println("list:"+list);
for(int i=0;i<list.size();i++){
id1=list.getJSONObject(i).getString("mid");
//System.out.println("id1"+id1);
id2=list.getJSONObject(i).getString("file");
//System.out.println("id"+id2);
id2="C400"+JSONObject.parseObject(id2).getString("media_mid")+".m4a";
//System.out.println("id"+id2);
name1=list.getJSONObject(i).getString("title");
name2=list.getJSONObject(i).getString("singer");
//System.out.println(name2);
JSONArray name=JSON.parseArray(name2);
//System.out.println("job4:"+name);
name2=name.getJSONObject(0).getString("name");
//System.out.println(name.getJSONObject(0).getString("name")); /*String detailUrl="https://c.y.qq.com/v8/fcg-bin/fcg_play_single_song.fcg?"
+ "songmid="+id1
+ "&tpl=yqq_song_detail&format=jsonp&callback=getOneSongInfoCallback&g_tk=5381&jsonpCallback=getOneSongInfoCallback&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0"
;
Page page2=webClient.getPage(detailUrl);
//System.out.println(page2);
String b="{"+zzee(page2.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}";
//System.out.println("b"+b);
JSONObject job1=JSONObject.parseObject("{"+zzee(page2.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("url");
System.out.println("job1:"+job1);
String job2=job1.getString(id2); System.out.println("job2"+job2);*/
String url1="https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=5381&jsonpCallback=MusicJsonCallback32651599216689386&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback32651599216689386&uin=0"
+"&songmid="+id1
+"&filename="+id2
+"&guid=2241489759";
;
Page page2=webClient.getPage(url1);
//System.out.println("page2"+page2);
JSONObject job2=JSONObject.parseObject("{"+zzee(page2.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("data");
//System.out.println("标题:"+job2.getString("items"));
String job3=job2.getString("items");
JSONArray job4=JSON.parseArray(job3);
//System.out.println("job4:"+job4);
//System.out.println(job4.getJSONObject(0).getString("vkey"));
url ="http://dl.stream.qqmusic.qq.com/"+id2+"?vkey="+job4.getJSONObject(0).getString("vkey")+"&guid=2241489759&uin=0&fromtag=66";
System.out.println("name:"+name1+"--"+name2);
System.out.println("url:"+url); download();
} } catch (Exception e) {
e.printStackTrace();
}
return name; }
private static String zzee(String str, String zz) {
String list = null;
Pattern p = Pattern.compile(zz);
Matcher m = p.matcher(str);
while (m.find()) {
list = m.group();
} return list;
}
private static void download() throws IOException{
FileOutputStream outputStream = null;
InputStream inputStream = null;
BufferedInputStream bis = null;
String outImage = name1+"--"+name2+ ".mp3";
URL imgUrl = new URL(url);//获取输入流
inputStream = imgUrl.openConnection().getInputStream();
//将输入流信息放入缓冲流提升读写速度
bis = new BufferedInputStream(inputStream);
//读取字节娄
byte[] buf = new byte[1024];
//生成文件
outputStream = new FileOutputStream("f://"+ outImage);
int size = 0;
//边读边写
while ((size = bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush();
}
public static void main(String[] args) {
WebClient webClient=getWebClient(false);
getMp3Url(webClient);
}
}
运行结果: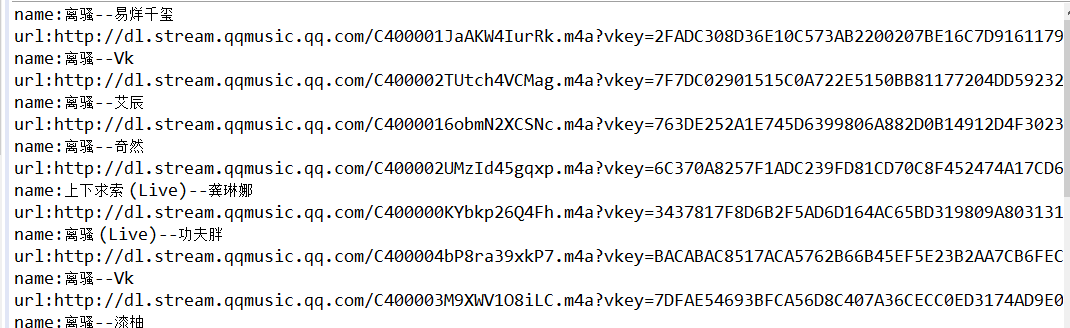
相比之下,酷狗音乐相对好爬一些,QQ音乐有些繁琐。。。
htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载的更多相关文章
- Python 爬虫-抓取中小企业股份转让系统公司公告的链接并下载
系统运行系统:MAC 用到的python库:selenium.phantomjs等 由于中小企业股份转让系统网页使用了javasvript,无法用传统的requests.BeautifulSoup库获 ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- 酷狗、QQ、天天动听——手机音乐播放器竞品对比
如果说什么艺术与人们生活最贴近,那应该属音乐了,因此当代人不离身的手机里必然会有自己喜欢的音乐播放器APP存在. 在当今无论PC端还是手机端音乐播放器都越来越同质化,我们应该选择哪款手机音乐播放器?它 ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
随机推荐
- 用标准3层神经网络实现MNIST识别
一.MINIST数据集下载 1.https://pjreddie.com/projects/mnist-in-csv/ 此网站提供了mnist_train.csv和mnist_test.cs ...
- dp回文
.dp回文子串 通常在dp数组中存放的是 从i到j是否是回文子串 1.动态规划 2.中心扩展法 #include<iostream> #include<algorithm> # ...
- ansible命令
ansible 默认提供了很多模块来供我们使用.在 Linux 中,我们可以通过 ansible-doc -l 命令查看到当前 ansible 都支持哪些模块,通过 ansible-doc -s ...
- 修改MAC地址的方法 破解MAC地址绑定(抄)
修改MAC地址的方法 破解MAC地址绑定 网卡的MAC地址是固化在网上EPROM中的物理地址,是一块网卡的“身份证”,通常为48位.在平常的应用中,有很多方面与MAC地址相关,如有些软件是和MAC ...
- Python 实现 Html 转 Markdown(支持 MathJax 数学公式)
因为需要转 html 到 markdown,找了个 python 的库,该库主要是利用正则表达式实现将 Html 转为 Markdown. 数学公式需要自己修改代码来处理. 我 fork 的项目地址: ...
- ES6中的Array.from()函数的用法
ES6为Array增加了from函数用来将其他对象转换成数组. 当然,其他对象也是有要求,也不是所有的,可以将两种对象转换成数组. 1.部署了Iterator(迭代器)接口的对象,比如:Set,Map ...
- django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.13 or newer is required; you have 0.9.3.
异常汇总:https://www.cnblogs.com/dotnetcrazy/p/9192089.html 这个是Django对MySQLdb版本的限制,我们使用的是PyMySQL,所以不用管它 ...
- 洛谷P2179 骑行川藏
什么毒瘤... 解:n = 1的,发现就是一个二次函数,解出来一个v的取值范围,选最大的即可. n = 2的,猜测可以三分.于是先二分给第一段路多少能量,然后用上面的方法求第二段路的最短时间.注意剩余 ...
- golang中使用Redis
一.golang中安装Redis github地址:https://github.com/garyburd/redigo 文档地址:http://godoc.org/github.com/garybu ...
- sed命令(二)
转自:https://www.cnblogs.com/maxincai/p/5146338.html sed命令用法 sed是一种流编辑器,它是文本处理中非常有用的工具,能够完美的配合正则表达式使用, ...