Azkaban实战,Command类型单一job示例,任务中执行外部shell脚本,Command类型多job工作flow,HDFS操作任务,MapReduce任务,HIVE任务
本文转载自:https://blog.csdn.net/tototuzuoquan/article/details/73251616
1.Azkaban实战
Azkaba内置的任务类型支持command、java
Command类型单一job示例
1、创建job描述文件
vi command.job
#command.job
type=command
command=echo 'hello'
2、将job资源文件打包成zip文件
zip command.job
3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
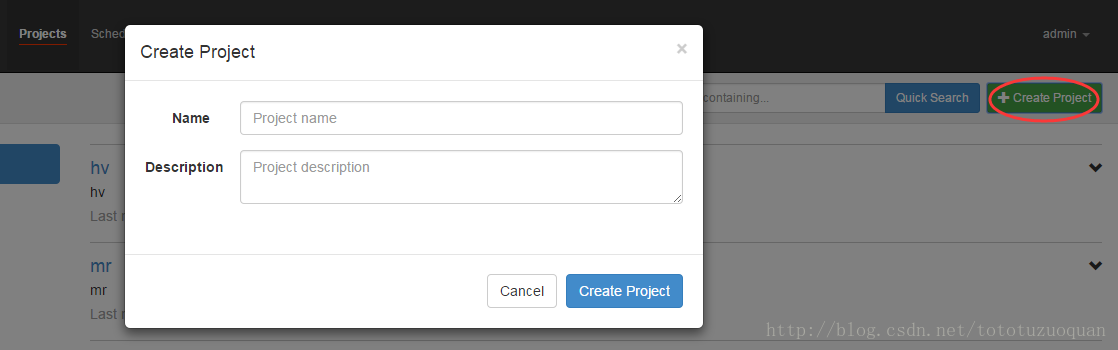
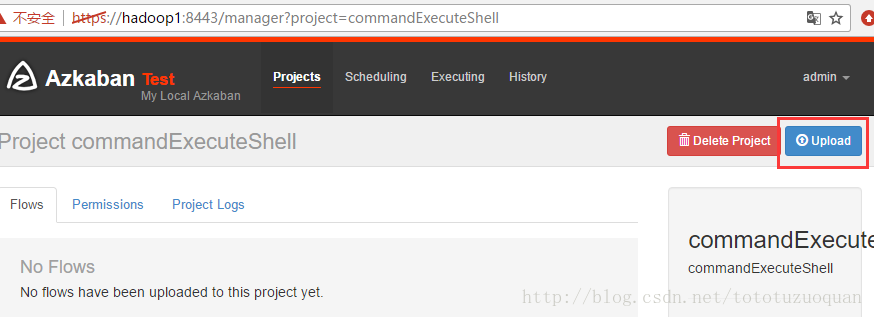
上传zip包,例如:

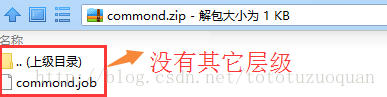
zip包中的内容如下:
上传界面:

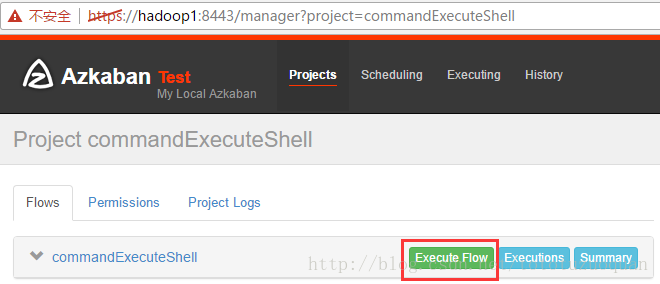
4、启动执行该job
可以查看脚本的内容:
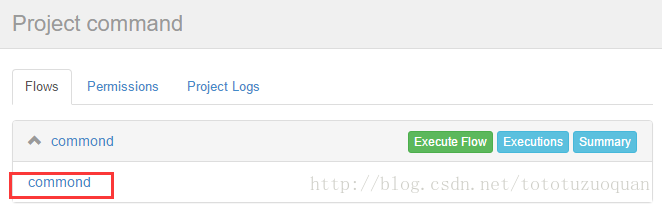
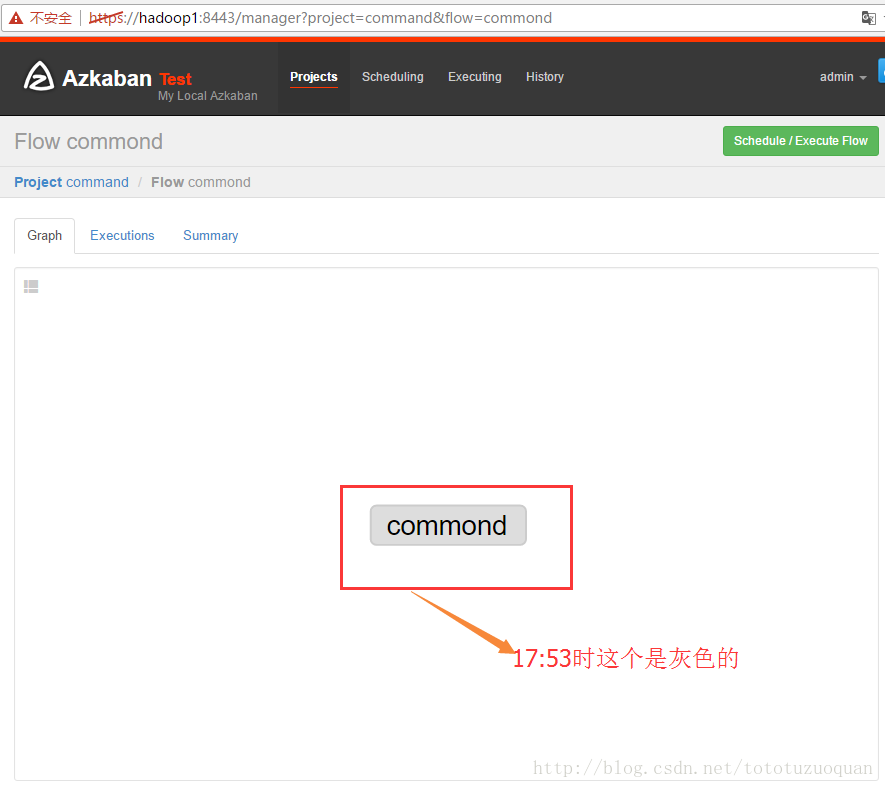
执行工作流:

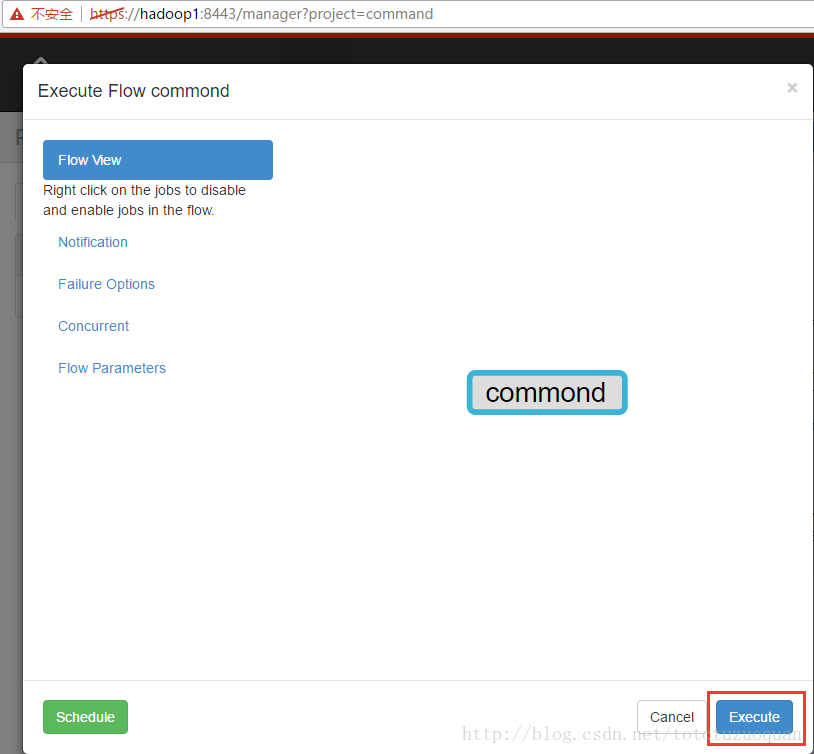
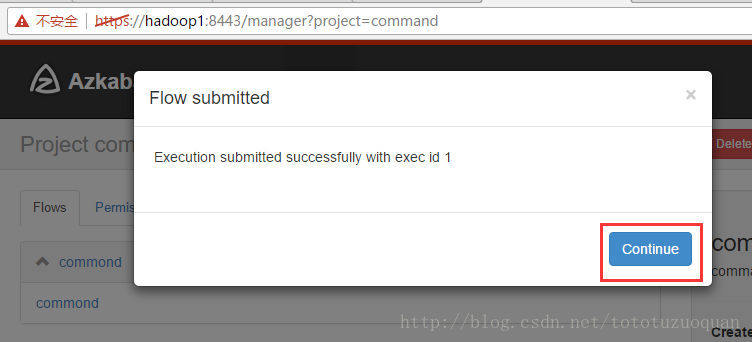
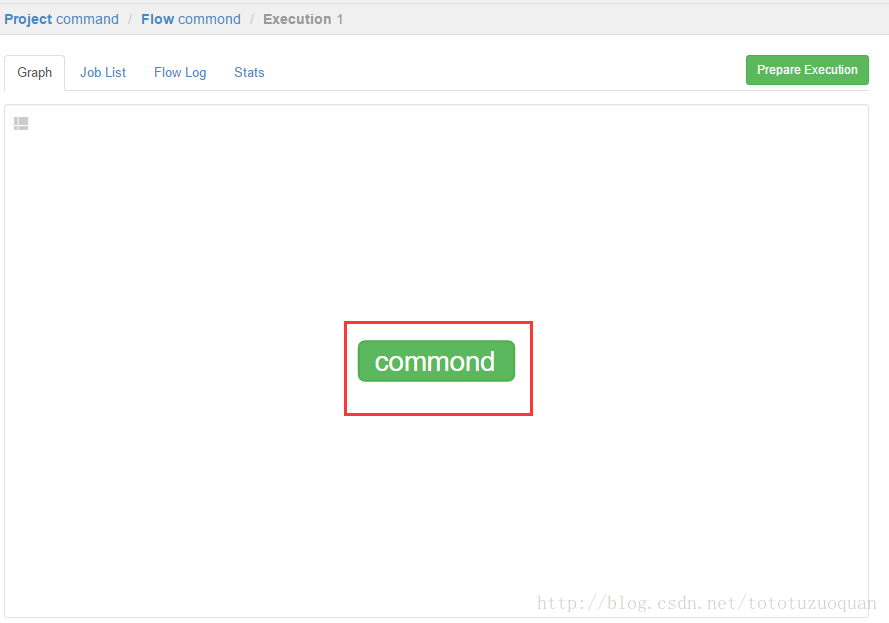
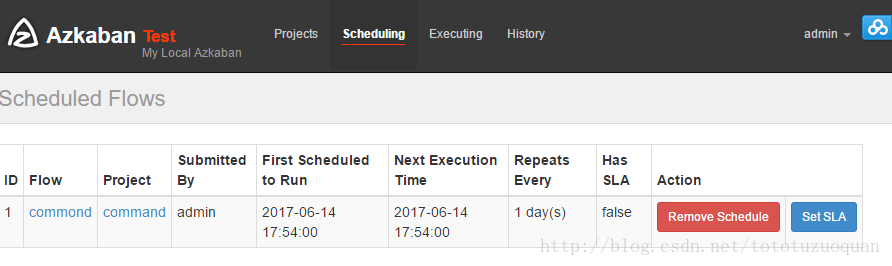
上面的已经变成了绿色了,表示已经执行完成了。
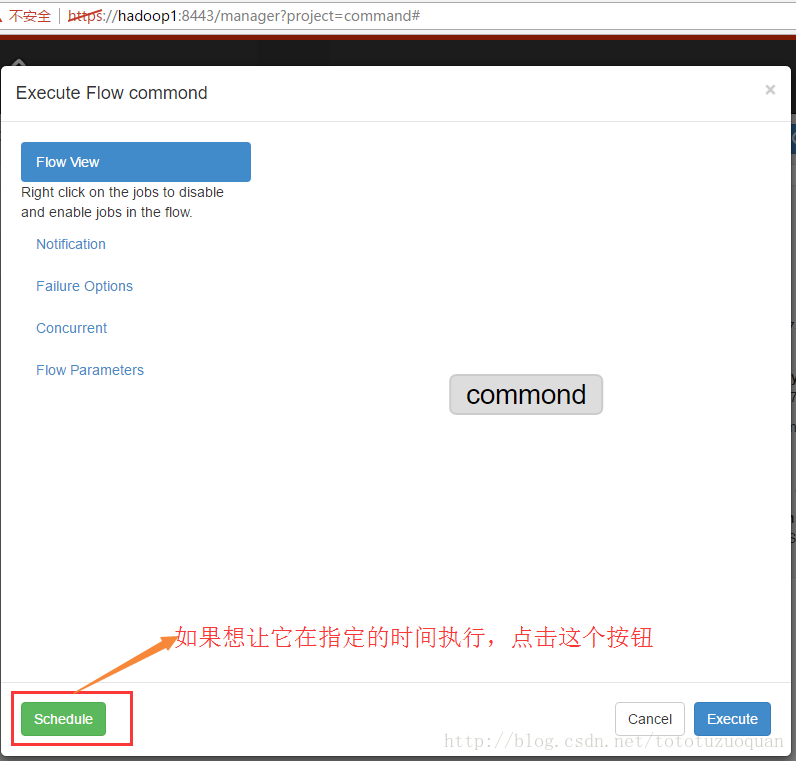
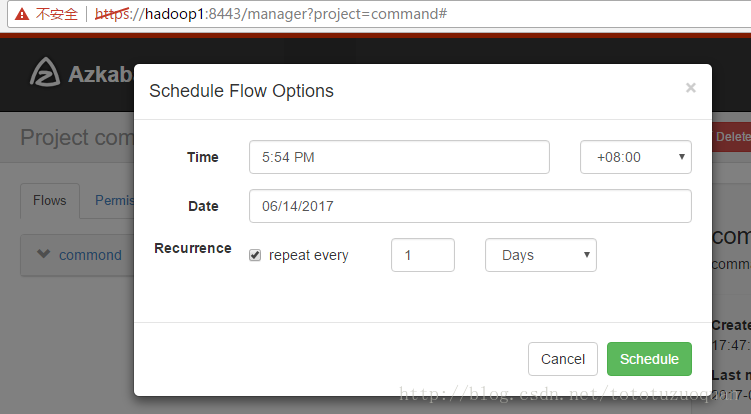
上面的repeat表示每天执行一次
1.2.通过任务执行shell脚本
编写command.job文件
内容如下:
#command.job
type=command
command=sh hello.sh
上面的command=sh hello.sh表示的意思是执行hello.sh脚本,其中hello.sh的脚本如下:
#!/bin/bash
echo 'hello' > /home/tuzq/software/azkabandata/hello.txt
按照上面的案例,上传上去,并且执行。
上传任务的脚本

执行工作流:

进入/home/tuzq/software/azkabandata查看是否有文件:
[root@hadoop1 azkabandata]# cd /home/tuzq/software/azkabandata
[root@hadoop1 azkabandata]# ls
hello.txt
[root@hadoop1 azkabandata]# cat hello.txt
hello
[root@hadoop1 azkabandata]#
1.3.Command类型多job工作流flow
1、创建有依赖关系的多个job描述
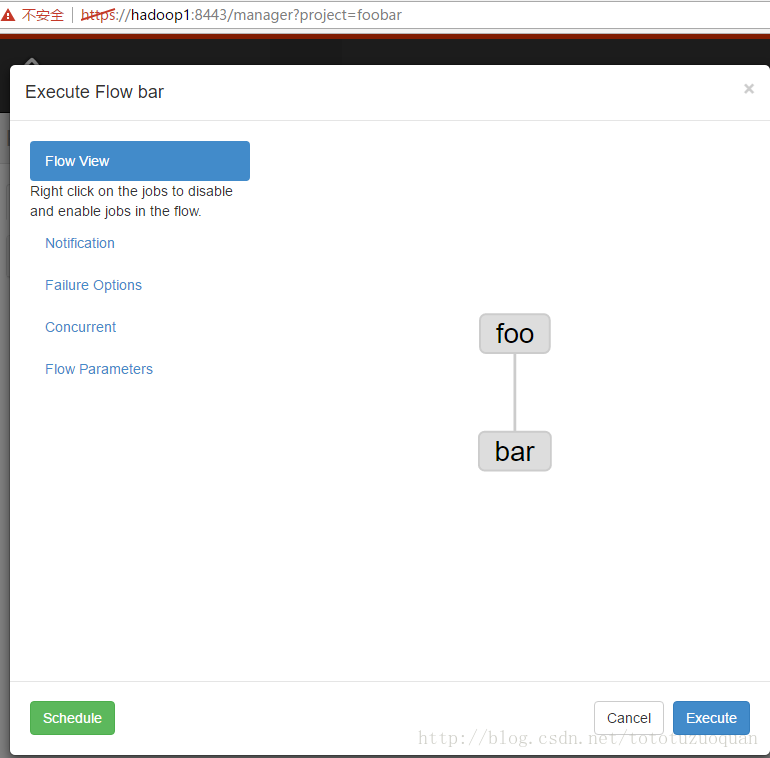
第一个job:foo.job
# foo.job
type=command
command=echo foo
第二个job:bar.job依赖foo.job
# bar.job
type=command
#表示这个命令依赖foo这个任务
dependencies=foo
command=echo bar
2、将所有job资源文件打到一个zip包中

3、在azkaban的web管理界面创建工程并上传zip包
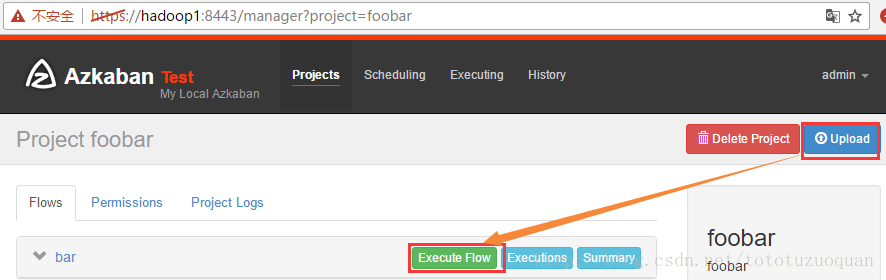
4、启动工作流flow




1.4.HDFS操作任务
1、创建job描述文件
# fs.job
type=command
command=/home/tuzq/software/hadoop-2.8.0/bin/hdfs dfs -mkdir /azaz
2、将job资源文件打包成zip文件
3、通过azkaban的web管理平台创建project并上传job压缩包
4、启动执行该job
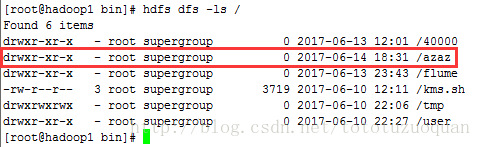
通过上满的结果可以证明,可以通过job来自行hdfs的命令
1.5.MAPREDUCE任务
Mr任务依然可以使用command的job类型来执行
1、创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
# mrwc.job
type=command
command=/home/tuzq/software/hadoop-2.8.0/bin/hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordc
2、将所有job资源文件打到一个zip包中
其中hadoop-mapreduce-examples-2.8.0.jar 在$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar
3、在azkaban的web管理界面创建工程并上传zip包
上传之后的准备工作是:
将wordcount/input上传到hdfs,命令如下:
[root@hadoop1 software]# hdfs dfs -put wordcount / [root@hadoop1 software]# hdfs dfs -ls / Found 8 items drwxr-xr-x - root supergroup 0 2017-06-13 12:01 /40000 drwxr-xr-x - root supergroup 0 2017-06-14 18:31 /azaz drwxr-xr-x - root supergroup 0 2017-06-13 23:43 /flume drwxr-xr-x - root supergroup 0 2017-06-14 18:46 /input -rw-r--r-- 3 root supergroup 3719 2017-06-10 12:11 /kms.sh
drwxrwxrwx - root supergroup 0 2017-06-14 18:43 /tmp drwxr-xr-x - root supergroup 0 2017-06-10 22:27 /user drwxr-xr-x - root supergroup 0 2017-06-14 18:47 /wordcount [root@hadoop1 software]# hdfs dfs -ls hdfs:/wordcount/input Found 9 items -rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/1.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/2.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/3.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/4.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/5.txt
-rw-r--r-- 3 root supergroup 27209520 2017-06-14 18:47 hdfs:///wordcount/input/a.txt
-rw-r--r-- 3 root supergroup 27209520 2017-06-14 18:47 hdfs:///wordcount/input/aaa.txt
-rw-r--r-- 3 root supergroup 27787264 2017-06-14 18:47 hdfs:///wordcount/input/b.txt
-rw-r--r-- 3 root supergroup 26738688 2017-06-14 18:47 hdfs:///wordcount/input/c.txt
其中1.txt中内容类似:
4、启动job
现象:
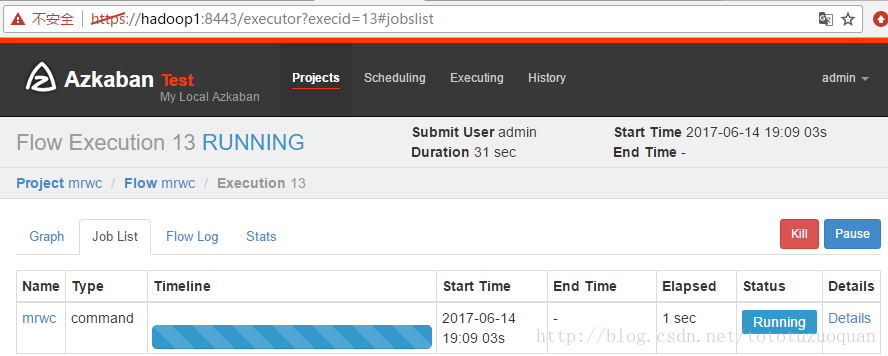
执行完成之后的状态是:

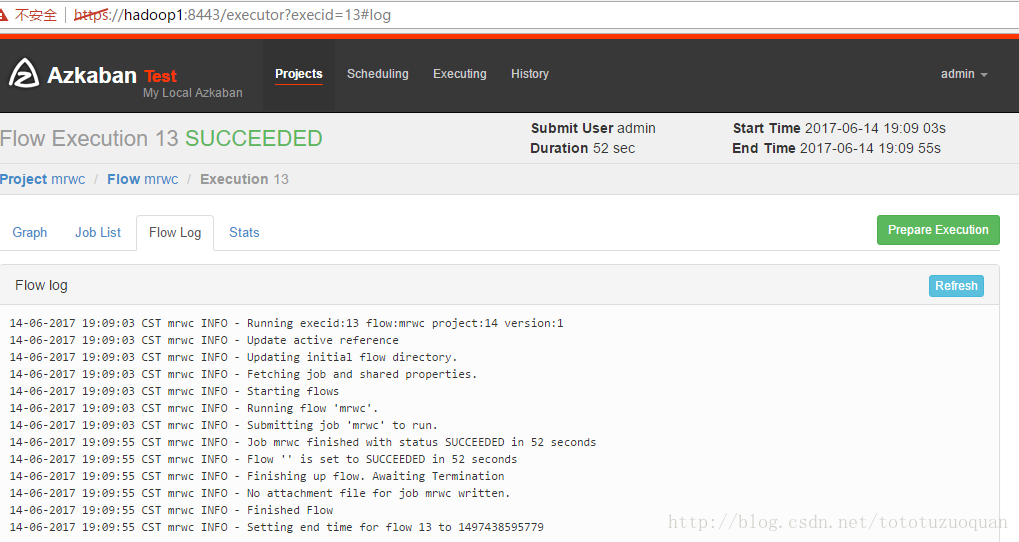

查看hdfs上的内容:
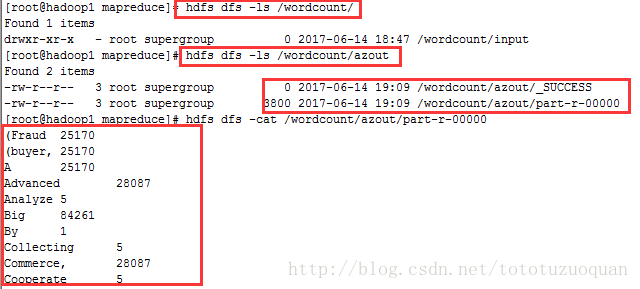
开始的时候发现在/wordcount下只有input这个文件夹,当执行完成之后,发现有了azout这个文件夹。
综上所述,说明通过azkaban在hdfs上生成了文件
1.5.HIVE脚本任务
创建job描述文件和hive脚本
Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
Job描述文件:hivef.job
#hivef.job
type=command
command=/home/tuzq/software/hive/apache-hive-1.2.1-bin/bin/hive -f 'test.sql'
2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
准备工作(在hdfs上创建一个hive执行sql后依赖的文件夹):
[root@hadoop1 apache-hive-1.2.1-bin]# hdfs dfs -mkdir -p /aztest/hiveoutput
执行完成之后效果如下:

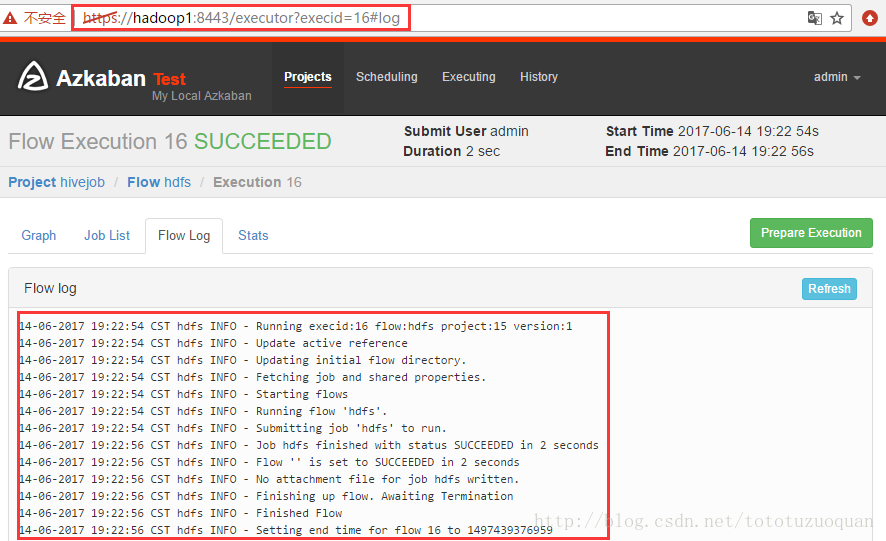
特别注意的是:如果执行错了,可以查看任务的日志输出:
Azkaban实战,Command类型单一job示例,任务中执行外部shell脚本,Command类型多job工作flow,HDFS操作任务,MapReduce任务,HIVE任务的更多相关文章
- Java 学习笔记 执行外部命令 包装类 枚举类型
执行外部命令 Runtime只能通过静态方法getRuntime获得,可以用来执行外部的命令 Runtime runtime = Runtime.getRuntime(); runtime.exec( ...
- MySQL执行外部sql脚本文件命令是报错:unknown command
使用source导入外部sql文件: mysql> source F:\php\bookorama.sql; -------------- source F: -------------- ER ...
- MySQL执行外部sql脚本文件命令报错:unknown command '\'
由于编码不一致导致的 虽然大部分导出是没有问题的 但是数据表中存储包含一些脚本(富文本内容)会出现该问题,强制指定编码即可解决. mysql导入时指定编码: mysql -u root -p --de ...
- shell 脚本文件类型.sh ,变量
1. shell脚本编程的基本过程 (1)建立shell文件,以 .sh 结尾的文件 (2)赋予shell文件执行权限,chmod 0777 文件名 (3)执行shell文件, ./ 文件名 或者ba ...
- Hadoop生态圈-Azkaban实战之Command类型多job工作流flow
Hadoop生态圈-Azkaban实战之Command类型多job工作流flow 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Azkaban内置的任务类型支持command.ja ...
- 08_Azkaban案例实践1_Command单一job示例
1.Azkaban实战 Azkaba内置的任务类型支持command.java 2.Command类型单一job示例 1.创建job描述文件:vi command.job #command.job t ...
- 在 SharePoint Server 2013 中配置建议和使用率事件类型
http://technet.microsoft.com/zh-cn/library/jj715889.aspx 适用于: SharePoint Server 2013 利用使用事件,您可以跟踪用户与 ...
- MySql数据库类型bit等与JAVA中的对应类型【布尔类型怎么存】
用char(1):可以表示字符或者数字,但是不能直接计算同列的值.存储消耗1个字节 用tinyint:只能表示数字,可以直接计算,存储消耗2个字节 用bit: 只能表示0或1,不能计算,存储消耗小于等 ...
- 一个简单的linux下设置定时执行shell脚本的示例
很多时候我们有希望服务器定时去运行一个脚本来触发一个操作,比如说定时去备份服务器数据.数据库数据等 不适合人工经常做的一些操作这里简单说下 shell Shell俗称壳,类似于DOS下的command ...
随机推荐
- 使用__slots__ __str__ __iter__
__slots__ 为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性. __str__ 用这个命令定义方法,可以返 ...
- iOS开发之UIGestureRecognizer
一:首先查看一下关于UIGestureRecognizer的定义 //当前手势状态 typedef NS_ENUM(NSInteger, UIGestureRecognizerState) { //尚 ...
- read读文件
FILE *fp=fopen("F:\\QQBrowser_Setup_DNF.exe", "rb"); fseek(fp, , SEEK_END); long ...
- 机器视觉:MobileNet 和 ShuffleNet
虽然很多CNN模型在图像识别领域取得了巨大的成功,但是一个越来越突出的问题就是模型的复杂度太高,无法在手机端使用,为了能在手机端将CNN模型跑起来,并且能取得不错的效果,有很多研究人员做了很多有意义的 ...
- Python 列表(List)
Python 列表(List) 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. Python有6个序列的内置类型 ...
- MSP430G2553 TimerA中断说明
一.TimerA中断向量. G2553一共有2个TimerA,分别是TimerA0和TimerA1,中断入口地址分别是: TimerA0中断向量名称 <--> 中断源 ------ ...
- 20175120彭宇辰 《Java程序设计》第九周学习总结
教材内容总结 一.mysql数据库管理系统(windows) 1.官网下载安装解压mysql社区版 2.启动mysql 用cmd进入mysql解压包,输入 mysqld --initialize-in ...
- onvif 框架代码生成
1:gsoap官网(http://gsoap2.sourceforge.net/)下载最新版gsoap(本次版本为gsoap_2.8.17)并解压. 2:新建一个文件夹(OnvifFramework) ...
- 离线安装Eclipse插件-Vrapper
首先下载Vrapper的资源文件:https://sourceforge.net/projects/vrapper/ 下载完成后解压,将features和plugins文件夹内的文件复制到eclips ...
- gdb 调试 python
gdb 版本 >7 的 对python调试有特别支持,参考: https://docs.python.org/devguide/gdb.html?highlight=gdb https://bl ...