RabbitMQ tutorial
一、安装RabbitMQ
RabbitMQ是一套开源(MPL)的消息队列服务软件,是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开源实现,由以高性能、健壮以及可伸缩性出名的 Erlang 写成。
所以我们要先安装Erlang
Erlang:http://www.erlang.org/downloads
RabbitMQ:https://www.rabbitmq.com/download.html
还可以启动一个后台插件,运行命令
rabbitmq-plugins enable rabbitmq_management
可以通过浏览器访问后台管理页面,默认账户密码: guest/guest
二、简单队列
我们只需要创建一个队列 往里面送一个消息 然后在取出他 多么简单的需求。let`s do it !!!
import pika # 建立连接
conn = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1',port=5672))
# 建立管道
channel = conn.channel() # 创建hello消息队列
channel.queue_declare(queue='hello') # 在RabbitMQ中信息不能直接被发送到队列,它需要通过一个 exchange
# 现在我们只需要知道如何使用由默认的exchange
# routing_key 指定要通信的队列
channel.basic_publish(exchange='',routing_key='hello',body='Hello World!')
print("---- Sent 'Hello World!' -----") # 在退出程序之前,我们需要确保网络缓冲区已被刷新.
# 并且我们的消息实际上已传递到RabbitMQ,我们可以轻轻地关闭连接.
conn.close()
output
---- Sent 'Hello World!' -----
如果你没看到这条信息,可能的原因之一是你的磁盘空间剩余不多了,最少需要200mb你才能正常运行它。
好了现在可以让我们来取回消息队列中的信息了。
import pika # 建立连接
conn = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1',port=5672))
# 建立管道
channel = conn.channel()
# 你可能疑惑为什么再建立一次队列,因为通常这么做可以保证队列一定被创建了
# 通常是多个程序访问一个队列,我们不知道他们哪个可能先跑起来
channel.queue_declare(queue='hello') # 定义一个回调函数,从队列中收到信息后调用它
def callback(ch, method, properties, body):
print(" [x] Received %r" % body) channel.basic_consume(queue='hello',auto_ack=True,on_message_callback=callback) while True:
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
output
[*] Waiting for messages. To exit press CTRL+C
[x] Received b'Hello World!'
此时再看消息队列的状况,这回用命令行来看
rabbit list_queues
output
Timeout: 60.0 seconds ...
Listing queues for vhost / ...
name messages
hello 0
消息从队列中被取出,就是pop出来了,所以消息队列里的messages已经空了。
三、work模式
上面的简单队列是简单的 一个生产者,一个消费者的模型。而通常我们可能有很多个消费者,就考虑了竞争的元素,一个进程向队列发布消息,多个进程从队列获取消息,而消息是唯一的。
简单的改变一下前面的代码
producer.py
import pika
import time
conn = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672))
channel = conn.channel()
channel.queue_declare(queue='hello')
print("---- Sent 'Hello World!' -----") for i in range(100):
message = str(i) + ' msg is sent'
channel.basic_publish(exchange='',routing_key='hello', body=message)
print(" [x] Sent %r" % message)
time.sleep(1)
worker.py
import pika conn = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672))
channel = conn.channel()
channel.queue_declare(queue='hello') def callback(ch, method, properties, body):
print(" [x] Received %r" % body) channel.basic_consume(queue='hello',auto_ack=True,on_message_callback=callback) while True:
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
再shell 1里面启动一个worker, shell 2里面再启动一个worker, shell 3 启动producer来观察一下
# shell 3
[x] Sent '0msg is sent'
[x] Sent '1msg is sent'
[x] Sent '2msg is sent'
[x] Sent '3msg is sent'
[x] Sent '4msg is sent'
[x] Sent '5msg is sent'
[x] Sent '6msg is sent'
[x] Sent '7msg is sent'
[x] Sent '8msg is sent'
[x] Sent '9msg is sent'
[x] Sent '10msg is sent'
....
# shell 1
[*] Waiting for messages. To exit press CTRL+C
[x] Received b'0msg is sent'
[x] Received b'2msg is sent'
[x] Received b'4msg is sent'
[x] Received b'6msg is sent'
[x] Received b'8msg is sent'
[x] Received b'10msg is sent'
# shell 2
[*] Waiting for messages. To exit press CTRL+C
[x] Received b'1msg is sent'
[x] Received b'3msg is sent'
[x] Received b'5msg is sent'
[x] Received b'7msg is sent'
[x] Received b'9msg is sent'
默认情况下,RabbitMQ将按顺序将每个消息发送给下一个使用者。平均每个消费者将得到相同数量的消息。这种分发消息的方式称为round-robin。可以自行尝试让三个或更多的员工来工作。
消息确认
通常情况下,进程处理完一个消息可能需要一些时间。您可能想知道,如果其中一个消费者启动了一个很长的任务,但只完成了一部分就挂掉了,会发生什么情况。使用我们当前的代码,一旦RabbitMQ将消息传递给消费者,它立即将其标记为删除。在这种情况下,如果您杀死一个工作中的进程,我们将丢失它正在处理的消息。我们还将丢失发送给这个特定工作人员但尚未处理的所有消息。但我们不想失去任何任务。如果一个进程崩溃了,我们希望把任务交给另一个进程。
为了确保消息永远不会丢失,RabbitMQ支持消息确认。使用者返回一个ack(nowledgement),告诉RabbitMQ已经接收、处理了一条特定的消息,并且RabbitMQ可以自由地删除它。如果使用者在不发送ack的情况下死亡(其通道关闭、连接关闭或TCP连接丢失),RabbitMQ将理解消息没有被完全处理,并将重新排队。如果同时有其他消费者在线,它会很快将其重新发送给另一个消费者。这样你可以确保没有信息丢失,即使工人偶尔死亡。没有任何消息超时;当使用者死亡时,RabbitMQ将重新传递消息。即使处理一条消息需要非常、非常长的时间,也没关系。默认情况下,将打开手动消息确认。在前面的示例中,我们通过 auto_ack=True 标志显式地关闭了它们。一旦我们完成了一个任务,就应该删除这个标志并从worker那里发送一个适当的确认。
稍微改变一下worker.py的代码
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(5)
print(" [x] Done")
ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(queue='hello', on_message_callback=callback)
发布一串消息后再运行worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received b'0msg is sent'
[x] Done
[x] Received b'1msg is sent'
此时 1msg is sent已经收到但没完成处理,来看一下队列里它还在不在
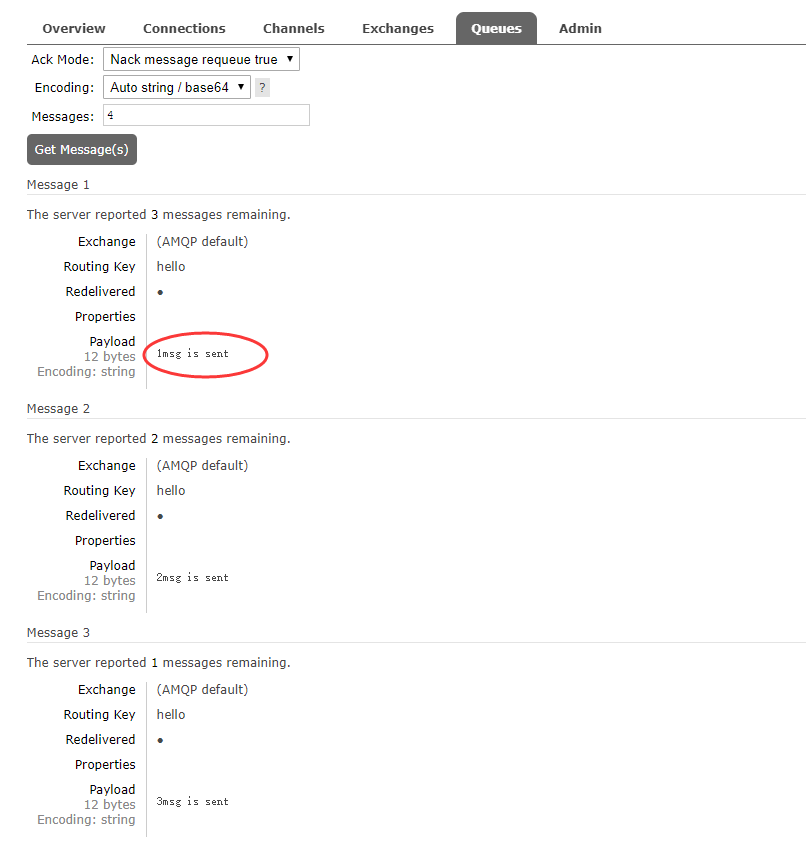
成功的保留下来了没有处理完的结果。
消息的耐久性
我们已经学会了如何确保即使用户死亡,任务也不会丢失。但是,如果RabbitMQ服务器停止,我们的任务仍然会丢失。当RabbitMQ退出或崩溃时,它将忘记队列和消息,除非您告诉它不要这样做。确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久的。首先,我们需要确保RabbitMQ永远不会丢失我们的队列。为了做到这一点,我们需要配置它:
channel.queue_declare(queue='hello', durable=True)
虽然这个命令本身是正确的,但是它在我们的设置中不能工作。这是因为我们已经定义了一个名为hello的队列,它不是持久的。RabbitMQ不允许您使用不同的参数重新定义现有队列,并且将向任何试图这样做的程序返回一个错误。但是有一个快速的解决方案——让我们声明一个不同名称的队列。例如new_queue:
channel.queue_declare(queue='new_queue', durable=True)
同时还需要改变worker.py中的代码,我们需要将消息标记为persistent—通过提供一个值为2的delivery_mode属性。
channel.basic_publish(exchange='',
routing_key="new_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
将消息标记为持久性并不能完全保证消息不会丢失。虽然它告诉RabbitMQ将消息保存到磁盘,但是当RabbitMQ接受了一条消息并且还没有保存它时,仍然有一个短时间窗口。此外,RabbitMQ不会对每条消息执行fsync(2)——它可能只是保存到缓存中,而不是真正写到磁盘上。持久性保证并不强,但对于我们的简单任务队列来说已经足够了。如果需要更强的保证,可以使用publisher confirm
公平分发
您可能已经注意到,分派仍然不能完全按照我们希望的方式工作。例如,在两个工人的情况下,当所有奇数的消息处理很慢,而偶数消息处理很快,一个工人会一直很忙,而另一个工人几乎不做任何工作。好吧,RabbitMQ对此一无所知,仍然会均匀地分发消息。这是因为RabbitMQ只在消息进入队列时发送消息。它不会查看消费者未确认的消息的数量。它只是盲目地将第n条消息发送给第n个消费者。
解决方法很简单,设置为prefetch_count=1的qos方法。这告诉RabbitMQ一次不要向工作人员发送一条以上的消息。或者,换句话说,在工作人员处理并确认前一条消息之前,不要向其发送新消息。相反,它将把它发送给下一个不太忙的工人。
channel.basic_qos(prefetch_count=1)
四、订阅模式
exchange
RabbitMQ消息传递模型的核心思想是,生产者永远不会将任何消息直接发送到队列。实际上,通常生产者甚至不知道消息是否会被传递到任何队列。相反,生产者只能向交换器发送消息。exchange是一件非常简单的事情。一边接收来自生产者的消息,另一边将消息推送到队列。exchange必须确切地知道如何处理它接收到的消息。它应该被附加到一个特定的队列中吗?它应该添加到许多队列中吗?或者它应该被丢弃。这些规则由exchange类型定义。
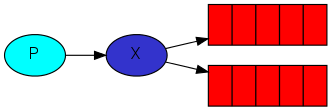
有几种可用的exchange类型:direct、topic、header和fanout。我们将关注最后一个——fanout。让我们创建一个这种类型的exchange,并命名为radio.
channel.exchange_declare(exchange='radio', exchange_type='fanout')
fanout 非常简单。它是将接收到的所有消息广播给它所知道的所有队列。这正是我们需要的记录器
现在我们需要告诉exchange向队列发送消息。exchange和队列之间的关系称为绑定。
channel.queue_bind(exchange='radio',queue=result.method.queue)
之后由它发布的信息,所有被绑定的消息队列都会接收到消息。让我们来看看完整的示例
import pika connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 创建exchange radio
channel.exchange_declare(exchange='radio', exchange_type='fanout')
# 创建消息队列radio1 radio2
radio1 = channel.queue_declare(queue='radio1')
radio2 = channel.queue_declare(queue='radio2')
# 绑定radio与 radio1 radio2
channel.queue_bind(exchange='radio',queue=radio1.method.queue)
channel.queue_bind(exchange='radio',queue=radio2.method.queue) message = 'xxx msg is sent'
channel.basic_publish(exchange='radio', routing_key='', body=message)
print(" [x] Sent %r" % message) connection.close()
来看看消息队列中的情况
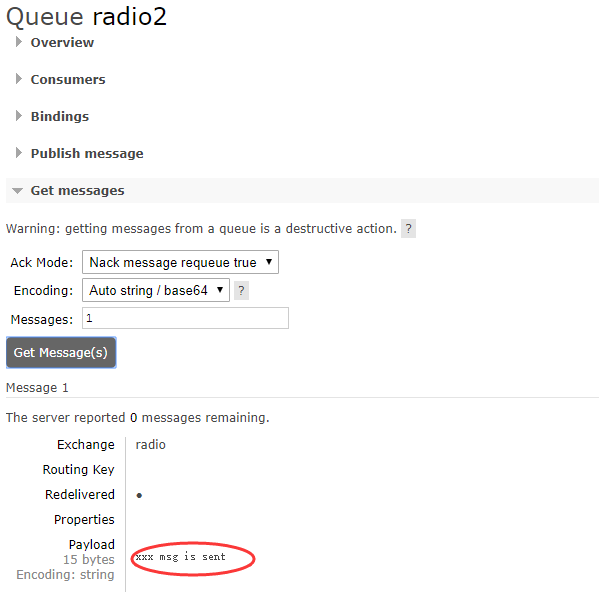
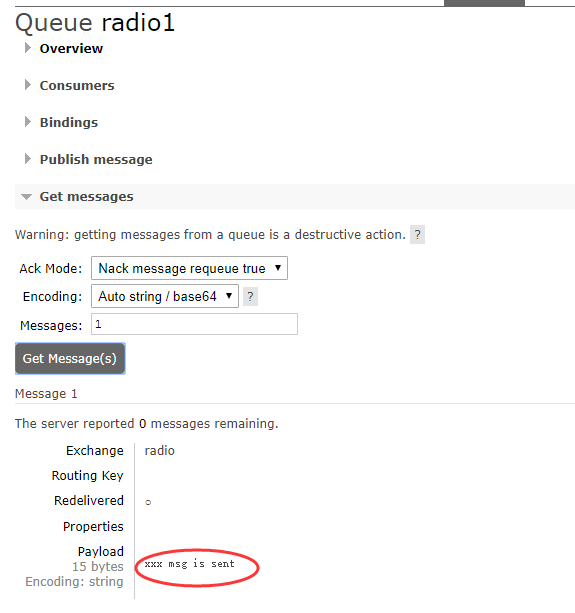
两个消息队列都收到了信息。 来自名为radio的exchange的数据转到两个具有服务器指定名称的队列。这正是我们想要的。
五、选择性的发送信息
有时候我们希望可以对绑定关系做出一些约束,如产生的日志信息,c1进程只获得error信息,而c2进程可以收到info,erro,warning
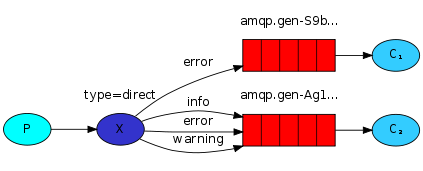
只需要在绑定关系时,指定routing_key就可以了。
channel.queue_bind(exchange='log',queue='c1', routing_key=key)
发布消息时也指定routing_key
channel.basic_publish(exchange='log', routing_key='ERROR', body='message')
这样exchange就会根据绑定关系和routing_key来发往对应的消息队列
完整展示
import pika log_level = ['INFO','DEBUG','WARNING','ERROR']
conn = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
channel = conn.channel()
channel.exchange_declare(exchange='log', exchange_type='direct')
channel.queue_declare(queue='c1')
channel.queue_declare(queue='c2') channel.queue_bind(exchange='log',queue='c1', routing_key=log_level[0])
channel.queue_bind(exchange='log',queue='c1', routing_key=log_level[1])
channel.queue_bind(exchange='log',queue='c1', routing_key=log_level[2])
channel.queue_bind(exchange='log',queue='c1', routing_key=log_level[3])
channel.queue_bind(exchange='log',queue='c2', routing_key=log_level[3]) e_msg = 'Error, move move'
w_msg = 'WARNING,ok, work on'
channel.basic_publish(exchange='log', routing_key=log_level[3], body=e_msg)
print(" [x] Sent %r:%r" % ('Error', e_msg)) channel.basic_publish(exchange='log', routing_key=log_level[2], body=w_msg)
print(" [x] Sent %r:%r" % ('Error',w_msg)) conn.close()
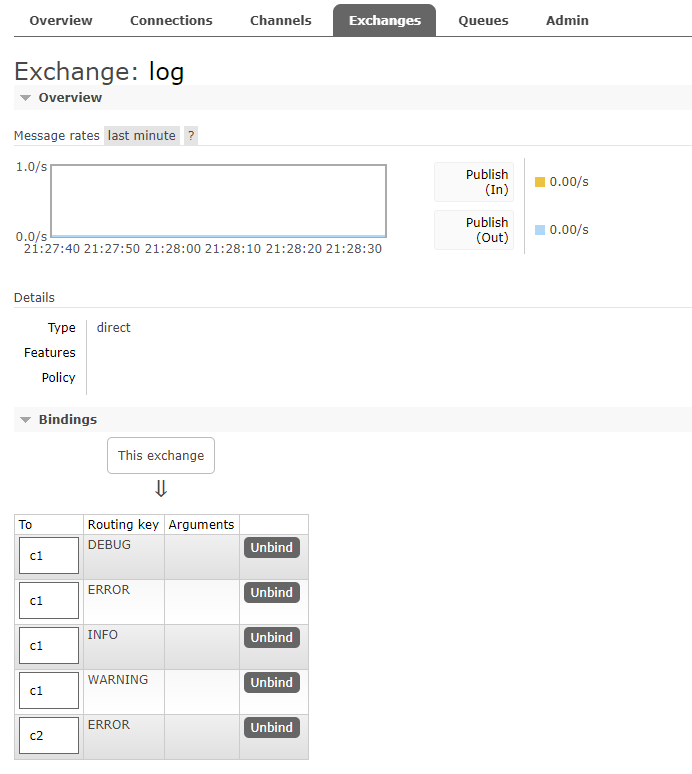
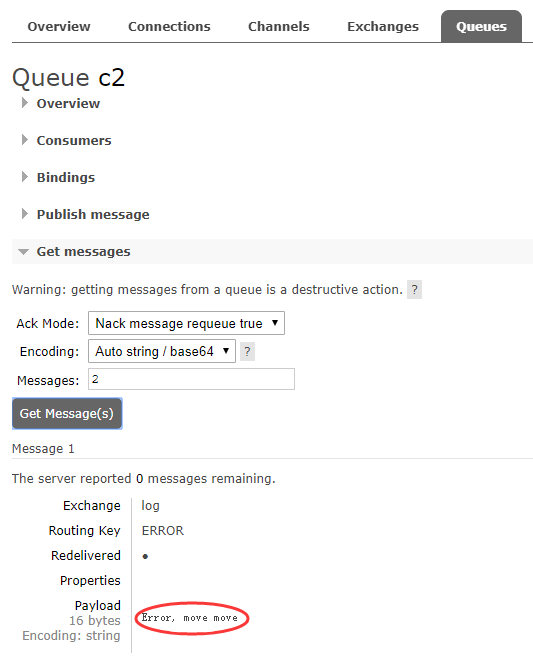
后台可以看到我们的绑定关系,来看看结果。

按规则模式匹配
可能还不够,如果我想让他按规则匹配,然后我的规则又有一定逻辑关系而且很多怎么办。我们可以用topic类型的exchange
channel.exchange_declare(exchange='topic_logs', exchange_type='topic')

这里用官方的图
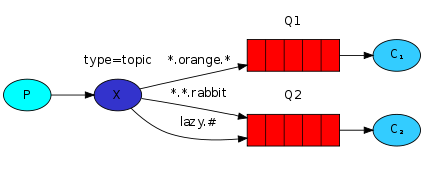
将routing_key设置为quick.orange.rabbit的消息,将被发送到两个队列。消息lazy.orange.elephant。也会去他们两个。另一方面,quick.orange.fox只会去第一个队列,lazy.brown.fox,只会去第二个。lazy.pink.rabbit将只被传递到第二个队列一次,即使它匹配两个绑定。
像quick.orange.male.rabbit和orange不会发向任何一个队列。
RabbitMQ tutorial的更多相关文章
- 《RabbitMQ Tutorial》第 1 章 简介
本文来自英文官网,其示例代码采用了 .NET C# 语言. <RabbitMQ Tutorial>第 1 章 简介(Introduction) RabbitMQ is a message ...
- 《RabbitMQ Tutorial》译文 第 2 章 工作队列
源文来自 RabbitMQ 英文官网的教程(2.Work Queues),其示例代码采用了 .NET C# 语言. In the first tutorial we wrote programs to ...
- 《RabbitMQ Tutorial》译文 第 3 章 发布和订阅
原文来自 RabbitMQ 英文官网的教程(3.Publish and Subscribe),其示例代码采用了 .NET C# 语言. In the previous tutorial we crea ...
- 《RabbitMQ Tutorial》译文 第 4 章 路由
原文来自 RabbitMQ 英文官网的教程(4.Routing),其示例代码采用了 .NET C# 语言. In the previous tutorial we built a simple log ...
- 《RabbitMQ Tutorial》译文 第 5 章 主题
原文来自 RabbitMQ 英文官网的教程(5.Topics),其示例代码采用了 .NET C# 语言. In the previous tutorial we improved our loggin ...
- 《RabbitMQ Tutorial》译文 第 6 章 远程过程调用(RPC)
原文来自 RabbitMQ 英文官网的教程(6.Remote procedure call - RPC),其示例代码采用了 .NET C# 语言. In the second tutorial we ...
- 《RabbitMQ Tutorial》译文 第 1 章 简介
原文来自 RabbitMQ 英文官网的教程(1.Introduction),其示例代码采用了 .NET C# 语言. RabbitMQ is a message broker: it accepts ...
- .NET中RabbitMQ的使用
概述 MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public ...
- RabbitMQ教程C#版 - Hello World
先决条件 本教程假定RabbitMQ已经安装,并运行在localhost标准端口(5672).如果你使用不同的主机.端口或证书,则需要调整连接设置. 从哪里获得帮助 如果您在阅读本教程时遇到困难,可以 ...
随机推荐
- Python中常见的序列及其函数
分片:分片操作的实现需要提供两个索引作为边界,第一个包含在分片内,第二个不包含 number =[1,2,3,4,5,6,7,8,9,10] number [3:6] -->[4,5,6] n ...
- 用python写一个名片管理系统
info = [] #先定义一个空字典while True: #利用while循环 print(' 1.查看名片') #第一个选项 print(' 2.添加名片') #第二个选项 print(' 3. ...
- 纯粹的python绑定
目前很多学习资料这样解释赋值与绑定,当是一个简单变量时,是赋值,当是复合变量时,是绑定. 注:赋值是重新复制变量到新变量中,赋值前后两个变量之间无联系.例C语言中: int a=6: int b: b ...
- 清除cookie
function clearCookie(){ if(document.cookie.length < 2048){ return; } //cookie大于2kb,清除cookie var c ...
- postman设置环境变量
postman属于一键式安装,不多赘述 1.设置环境变量 点击设置进入 添加环境变量 添加成功可选择 应用{{}}包住变量名即可 地址变化更换即可
- Vue基础之计算属性
适用场景 设想一个场景,你需要得到一个复杂运算/逻辑的返回值,利用模板内的表达又过长且难以阅读和维护,这时计算属性就可以很好的解决你的问题.看下面的例子: <!DOCTYPE html> ...
- Matlab 提取R,G,B颜色分量
>> im = imread('ny.png'); >> r = im(:,:,1); >> g = im(:,:,2); >> b = im(:,:, ...
- C#取出重复的方式以及用字典存储以键存储集合的方法
最近在做项目的时候,发现有些需求需要特别的方式来实现.下面看代码 private List<string> firstType = new List<string>(); pr ...
- windows下配置下burpsuite的小方法。
1.下载破解版burpsuite和正版burpsuite. 2.安装正版burpsuite(免费版) 3.打开安装路径 4.把破解版的burp拷贝到安装路径下 5.该路径下应该有个burpsuite_ ...
- C51单片机_day_01(定时器和中断系统)
c51单片机 51单片机是控制电路系统的开关,当然芯片就是51芯片,现在随着科技的发展,也是出了很多,功能更多,更全的芯片. 51是用c语言做为程序编程的语言 ——我对基本基础 ...