基于用户协同过滤--UserCF
UserCF
本系列文章主要介绍推荐系统领域相关算法原理及其实现。本文以项亮大神的《推荐系统实践》作为切入点,介绍推荐系统最基础的算法(可能也是最好用的)--基于用户的协同过滤算法(UserCF)。参考书中P44-50。
1.简述
假设在一个个性化的推荐系统中,用户A需要推荐,那么可以先找到与A有相似兴趣的用户,例如B、C、D把他们喜欢的,用户A没有听说过的物品推荐给A。这种方法被称为基于用户的协同过滤。
2.计算用户相似度
从算法原理中我们可以得到UserCF主要包括两个步骤:
1.找到和A用户兴趣相似的用户集合(B、C、D)。
2.找到这个集合中的用户喜欢,且目标用户A还未听说或购买过的物品推荐给目标用户。
步骤1.的关键其实就是计算用户兴趣的相似度。这里主要是利用用户行为来计算用户相似度。给定用户U和用户V,令N(u),N(v)分别表示用户u,v曾经有正反馈的用户集合。用Jaccard公式计算:
\]
或者通过余弦相似度计算:
\]
以书中数据为例:
train = {'A':('a','b','d'),'B':('a','c'),'C':('b','e'),'D':('c','d','e')}
\]
同理可计算Wac和Wad。
按书中对所有用户两两计算余弦相似度,时间复杂度是O(U*U),在用户量很大时非常耗时,事实上,很多用户之间并没有对同样的物品产生过行为,因此可以先过滤出N(u)交N(v)不等于0的用户对(u,v),然后再对其除以分母。
这里用item-user倒排表的方式,建立一个4*4的用户相似度矩阵C,最终得到的W[u][v]就是(u,v)对相似度的分子部分,再除以分母即可得到最终的用户相似度。如书中图2-7:

def UserSimilarity(train , IIF = False):
# IIF 是否对 过于热门即 购买人数过于多的物品 在计算用户相似度的时候进行惩罚
# 因为很多用户对之间并没有对相同的物品产生过行为,只计算对相同物品产生过行为的用户之间的相似度。
# 采用余弦相似度
# 建立倒排表,对每个物品保存只对其产生过行为的用户列表。
item_users = dict() # 物品-用户 倒排表
for u, items in train.items():
for i in items:
# 这里将 item_users.keys() 改为 item_users , 文中例子 应该用set 或 list存,而不是dict:
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
# 建立如图2-7所示的倒排矩阵
C = dict() # key 用户对 value 购买同一物品的次数
N = dict() # N(u) 表示用户购买的 商品数 {'A': 3, 'B': 2, 'C': 2, 'D': 3}
for i,users in item_users.items():
for u in users:
if u not in N.keys():
N[u] = 0
N[u] += 1
for v in users:
if u == v:
continue
if (u,v) not in C.keys():
C[u,v] = 0
if IIF:
# len(users) 表示购买此物品的用户数,越热门,购买用户越多,C[u,v] 就越小
# 相当于之前的分子是相交个数,现在是
C[u,v] += 1 / math.log(1 + len(users))
else:
C[u,v] += 1
W = dict()
for co_user, cuv in C.items():
W[co_user] = cuv / math.sqrt(N[co_user[0]]*N[co_user[1]])
return W
这里可以看下return的 W:
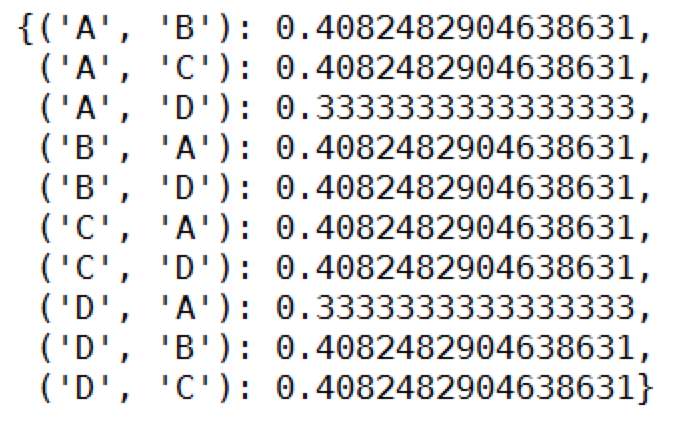
3.计算推荐结果
这里直接用书中P47的解释了,Wuv已经有了,其实就是根据W再乘一个权重r就可以了,r可以根据比如那些用户的行为更重要来改变,这里书中默认r都是1。

下述是推荐部分的代码:
def UserCFRecommend(user,train,W,k):
# rvi 代表用户v对物品i的权重
rvi = 1
rank = dict()
interacted_items = train[user]
related_user=[]
# 和 A 有相似度的用户 ,B,C,D
for co_user,sim in W.items():
if co_user[0] == user:S
related_user.append((co_user[1],sim))
# v : 有相似度的用户 , wuv : 用户间相似度
for v , wuv in sorted(related_user , key = lambda a:a[1], reverse = True)[0:k]:
for item in train[v]:
if item in interacted_items:
continue
else:
# 还是得初始化,才可以赋值
if item not in rank.keys():
rank[item] = 0
rank[item] += wuv*rvi
return rank
最后选择对A进行推荐,K取3,由于A对a,b,d有过行为,K=3又代表相似用户为B,C,D,所以会将c、e推荐给A。这里得到:

和书中结果一致。在书中对用户相似度的改进也在上述UserSimilarity部分的代码中体现了,只需在计算W的时候将参数 IIF=True 即可。该改进其实就是在计算u,v相似度时,对其进行惩罚,惩罚是基于在倒排表中所有购买此物品的用户长度,即此物品购买人数越多,提供的相似度越小,具体理解请参考代码。
代码详见:https://github.com/Alarical/Recommend/tree/master/UserCF
对于书中,表2-4 UserCF在movielens数据集中的运用,主要参考https://blog.csdn.net/u012050154/article/details/52268057大神的博客和代码,对与其代码增加了部分注释,详见我的github。
参考资料:
https://blog.csdn.net/guanbai4146/article/details/78016778
https://blog.csdn.net/u012050154/article/details/52268057
项亮 --《推荐系统实践》
基于用户协同过滤--UserCF的更多相关文章
- 推荐召回--基于用户的协同过滤UserCF
目录 1. 前言 2. 原理 3. 数据及相似度计算 4. 根据相似度计算结果 5. 相关问题 5.1 如何提炼用户日志数据? 5.2 用户相似度计算很耗时,有什么好的方法? 5.3 有哪些改进措施? ...
- 基于Python协同过滤算法的认识
Contents 1. 协同过滤的简介 2. 协同过滤的核心 3. 协同过滤的实现 4. 协同过滤的应用 1. 协同过滤的简介 关于协同过滤的一个最经典的例子就是看电影,有时候 ...
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
主要内容: 1.k近邻 2.python实现 1.什么是k近邻(KNN) 在入门-1中,简单地实现了基于用户协同过滤的最近邻算法,所谓最近邻,就是找到距离最近或最相似的用户,将他的物品推荐出来. 而这 ...
- Collaborative Filtering(协同过滤)算法详解
基本思想 基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分.根据不同用户对相同商品或内容的态度和偏好程度计算用户 ...
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了.硬生生是拖到了十一假期.自己也是醉了... 找工作不是非常顺利,希望写点东西回想一下知识.然后再攒点人品吧,仅仅 ...
- 基于协同过滤的个性化Web推荐
下面这是论文笔记,其实主要是摘抄,这片博士论文很有逻辑性,层层深入,所以笔者保留的比较多. 看到第二章,我发现其实这片文章对我来说更多是科普,科普吧…… 一.论文来源 Personalized Web ...
- 用Maven构建Mahout项目实现协同过滤userCF--单机版
本文来自:http://blog.fens.me/hadoop-mahout-maven-eclipse/ 前言 基于Hadoop的项目,不管是MapReduce开发,还是Mahout的开发都是在一个 ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- 电影推荐系统---协同过滤算法(SVD,NMF)
SVD 参考 https://www.zybuluo.com/rianusr/note/1195225 1 推荐系统概述 1.1 项目安排 1.2 三大协同过滤 1.3 项目开发工具 ...
随机推荐
- python&JSONP(Jquery篇)
采用Jquery发送跨域请求: <!DOCTYPE html> <html lang="en"> <head> <meta charset ...
- LeetCode第二十四题-交换链表中节点值
Swap Nodes in Pairs 问题简介:给定链表,交换每两个相邻节点并返回链表. 举例: 输入:1->2->3->4 输出:2->1->4->3 链表结构 ...
- CNN的反向传播
在一般的全联接神经网络中,我们通过反向传播算法计算参数的导数.BP 算法本质上可以认为是链式法则在矩阵求导上的运用.但 CNN 中的卷积操作则不再是全联接的形式,因此 CNN 的 BP 算法需要在原始 ...
- 前端笔记知识点整合之JavaScript(一)初识JavaScript
一.JavaScript简介 1.1网页分层 web前端一共分三层: 结构层 HTML : 负责搭建页面结构 样式层 CSS : 负责页面的美观 行为层 JavaSc ...
- Go语言--数组、切片、
3.1 数组--固定大小的连续空间 3.1.1 声明数组 写法 var 数组变量名 [元素数量]T 说明: 变量名就是使用时的变量 元素的数量可以是表达式,最后必须为整型数值 T 可是是任意基本类型, ...
- PHP常用函数大全500+
php usleep() //函数延迟代码执行若干微秒. unpack() //函数从二进制字符串对数据进行解包. uniqid() //函数基于以微秒计的当前时间,生成一个唯一的 ID. time_ ...
- django会话
django会话 可以把会话理解为客户端与服务器之间的一次会晤,在一次会话过程中有多次请求和响应,但是由于HTTP协议的特性-->无状态,每次浏览器的请求都是无状态的,无法保存状态信息,也就是说 ...
- P4098 [HEOI2013]ALO
最近这个家伙去哪了,为啥一直不更博客了呢?原来他被老师逼迫去补了一周的文化课,以至于不会把班里的平均分拉掉太多.好了,我们来看下面这道题目: P4098 [HEOI2013]ALO 题目描述 Welc ...
- C++智能指针剖析(下)boost::shared_ptr&其他
1. boost::shared_ptr 前面我已经讲解了两个比较简单的智能指针,它们都有各自的优缺点.由于 boost::scoped_ptr 独享所有权,当我们真真需要复制智能指针时,需求便满足不 ...
- C#学习-查询表达式
查询表达式必须以from子句开头,并且必须以select或group子句结尾 在第一个from子句和最后一个select或group子句之间,可以包含一个或多个where子句.orderby.join ...