IDEA15 下运行Scala遇到问题以及解决办法
为了让Scala运行起来还是很麻烦,为了大家方便,还是记录下来:
1、首先我下载的是IDEA的社区版本,版本号为15.
2、下载安装scala插件:
2.1 进入设置菜单。

2.2 点击安装JetBrains plugin
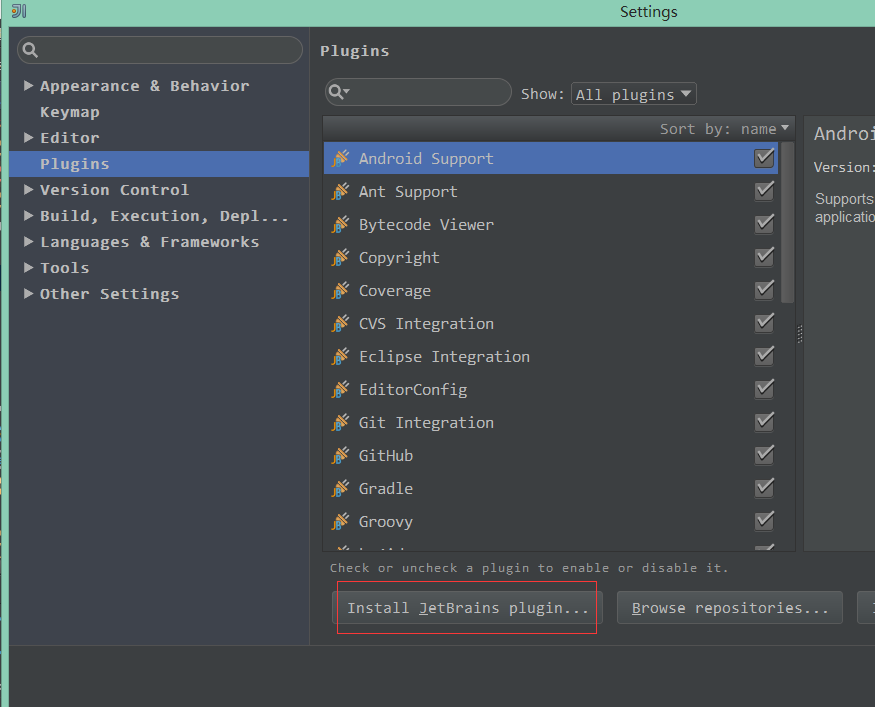
2.3 输入scala查询插件,点击安装
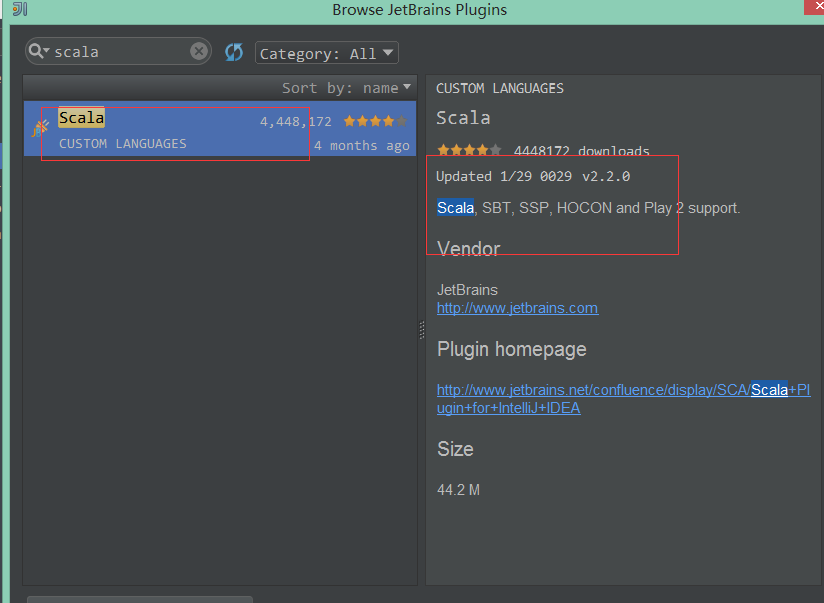
说明:我的IDEA已经安装,所以这里面没有显示出来安装按钮,否则右边有显示绿色按钮。
3、新建Scala工程
3.1 新建工程
通过菜单:File----》New Project 选择Scala工程。
并且设置项目基本信息,如下图:

3.2 设置Modules
1)点击右上角的方块:
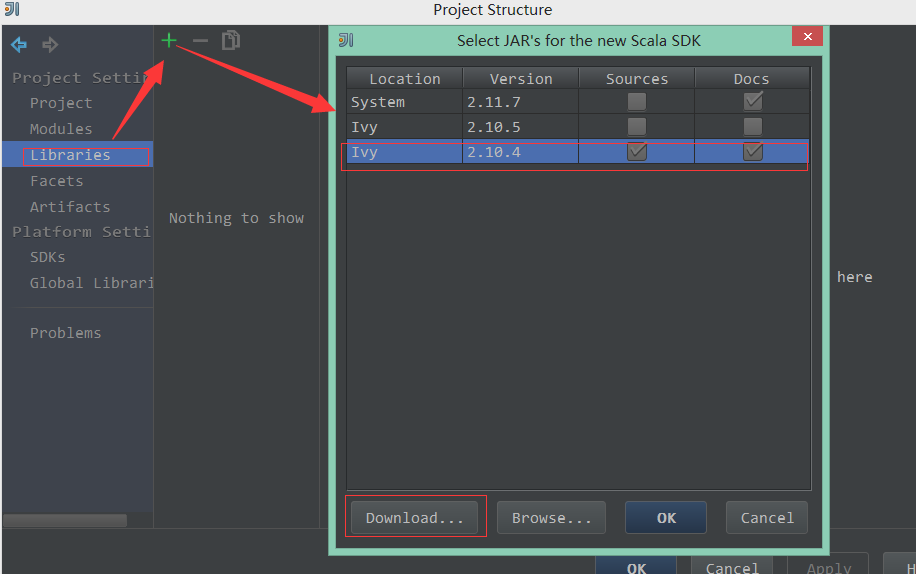
2)在左边选择Libraries---》+---》Scala SDK--》选择版本为2.10.4
说明:如果不存在这个版本可以通过左下角的download去下载。
3)选择添加Java的Jar文件,选择Spark和Hadoop关联的Jar
我这里添加的是:spark-assembly-1.6.1-hadoop2.6.0.jar 这个是spark安装时候自带的lib里面有,很大。
定位到jar所在的目录后,刷新,选择这个文件,点击OK,会花费比较长时间建索引。
4)在Src源码目录新建文件:WordCount.scala
且输入如下代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage:<File>")
System.exit(1)
}
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
val words = line.flatMap(_.split("")).map((_, 1))
val reducewords = words.reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}
5)编译运行:
需要输入参数,所以要设置下相关参数信息:
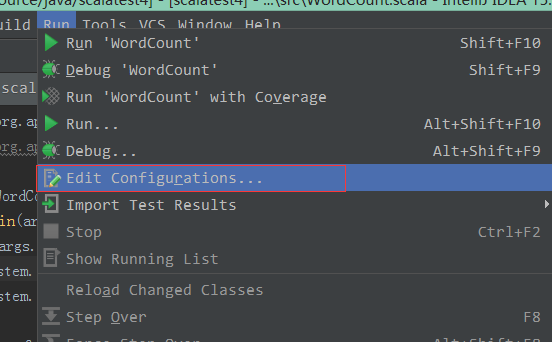
随便复制个文件过去,然后设置下:

- 抛出异常:
Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:401)
解决办法:需要设置下SparkContext的地址:
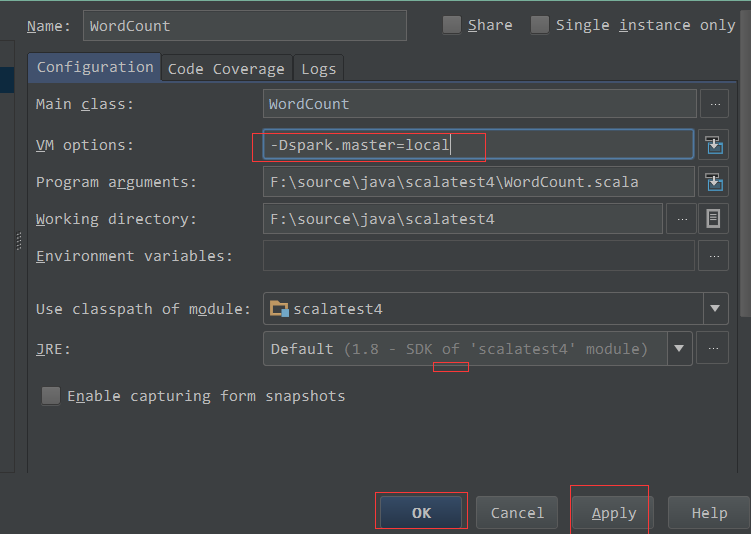
- 抛出异常:
16/06/25 12:14:18 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
解决办法:
http://stackoverflow.com/questions/19620642/failed-to-locate-the-winutils-binary-in-the-hadoop-binary-path
可能是因为我没有安装hadoop的原因,设置下相关信息就可以:
下载:
<a href="http://www.srccodes.com/p/article/39/error-util-shell-failed-locate-winutils-binary-hadoop-binary-path">Click here</a>
设置:HADOOP_HOME为下载后解压内容的上级目录,然后在PATH里面添加%HADOOP_HOME%/bin;
4、其他异常
1)异常内容:类或Object XXX已经被定义
解决办法: 这个可能是工程里面设置了两个source目录,需要删除一个。
2)异常内容:sparkContext.class 依赖不存在
解决办法:需要引入hadoop的jar包,我这里是:spark-assembly-1.6.1-hadoop2.6.0.jar
3)异常内容:Error:(17, 29) value reduceByKey is not a member of org.apache.spark.rdd.RDD[(String, Int)]
解决办法: 导入这个: import org.apache.spark.SparkContext._
4)异常内容:Exception in thread "main" java.lang.NoClassDefFoundError: com/google/common/util/concurrent/ThreadFactoryBuilder
解决办法:添加依赖Jar :guava-11.0.2.jar
5)异常内容:Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
解决办法:更改scala-sdk版本为2.10,如果没有通过如下方式下载:(速度奇慢)
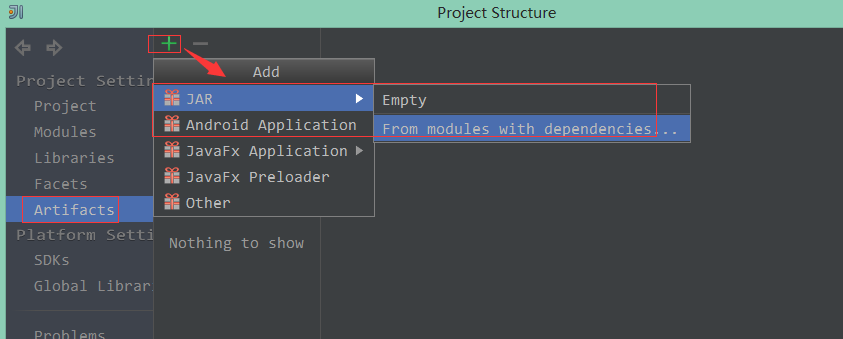
5、打包成Jar
1、设置下导出Jar信息:
2、设置导出的工程还导出的Main类:
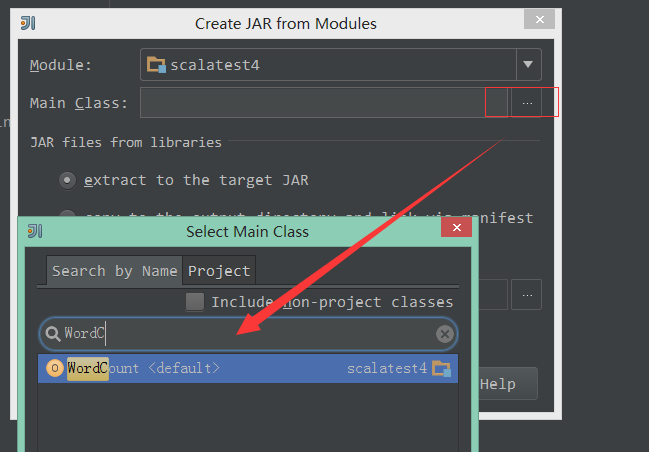
3、通过选择点击-号删除其他依赖的class

4、导出Jar包:
5、上传后执行Jar包
./spark-submit --master spark://inas:7077 --class WordCount --executor-memory 512m /home/hadoop/sparkapp/scalatest4.jar hdfs://inas:9000/user/hadoop/input/core-site.xml
说明: hadoop文件为以前新建的,在提交之前需要先启动hadoop再自动spark,然后再用以上办法提交。
启动Hdfs: ./start-dfs.sh
启动spark:./sbin/start-all.sh(没试过)
可以通过如下方法启动:
~/project/spark-1.3.0-bin-hadoop2.4 $./sbin/start-master.sh
~/project/spark-1.3.0-bin-hadoop2.4 $./bin/spark-class org.apache.spark.deploy.worker.Worker spark://inas:7077
注意:必须使用主机名
启动模式为standaline模式。
Spark Standalone Mode 多机启动,则其他主机作为worker启动,设置master主题。
IDEA15 下运行Scala遇到问题以及解决办法的更多相关文章
- kali linux下运行.sh文件权限不够解决办法
我要装一个生成免杀的神奇,系统提示权限不够 2 于是我想到了sudo,可还是不行 3 于是找到了方法 chmod a+x 文件名 4 再运行一下,成功 5 有时有的方法很简答,只要你愿意找.
- Eclipse在Tomcat环境下运行项目出现NoClassDefFoundError/ClassNotFoundException解决办法
For this error, there can be different solutions. I have noted down the ones that had worked for me. ...
- MySQL 5.7 Command Line Client输入密码后闪退和windows下mysql忘记root密码的解决办法
MySQL 5.7 Command Line Client输入密码后闪退的问题: 问题分析: 1.查看mysql command line client默认执行的一些参数.方法:开始->所有程序 ...
- 用C#绘图实现动画出现卡屏(运行慢)问题的解决办法
原文:用C#绘图实现动画出现卡屏(运行慢)问题的解决办法 正在用C#做一个小游戏,需要用到动画,上次解决的问题是闪烁问题,用双缓冲技术.以为不会有什么问题了.后来当把图片全部绘制上去的时候依然出现了卡 ...
- html页面顶部出现一段空白,检查控制台发现body 下出现字符,原因及解决办法
html页面顶部出现一段空白,检查控制台发现body 下出现字符,原因及解决办法 分析: 原来是页面编码时增加了BOM,此页面后端数据主要是PHP语言,对PHP来讲PHP在设计时 ...
- 微信h5页面下拉露出网页来源的解决办法
微信h5页面下拉露出网页来源的解决办法:将document的touchmove事件禁止掉 //禁止页面拖动 document.addEventListener('touchmove', functio ...
- Linux下运行scala语言的jar包
1.新建project 2.打包 3.linux下运行jar包 #First.jar为jar包名,Test为主类名 [root@FI-2 Desktop]# spark-submit First.ja ...
- ubuntu12.04下root启动wireshark报错解决办法
在ubuntu11.10以后版本中发现,安装wireshark后用root权限启动,弹出如下错误: Running as user “root” and group “root”. This coul ...
- linux下QT Creator常见错误及解决办法
最近因为在做一个关于linux下计算机取证的小项目,需要写一个图形界面,所以想到了用QT来写,选用了linux下的集成开发环境QT Creator5.5.1,但刚刚安装好,竟然连一个"hel ...
随机推荐
- Linux内核入门到放弃-时间管理-《深入Linux内核架构》笔记
低分辨率定时器的实现 定时器激活与进程统计 IA-32将timer_interrupt注册为中断处理程序,而AMD64使用的是timer_event_interrupt.这两个函数都通过调用所谓的全局 ...
- 实现一个book类
设计实现一个book类 具体要求 定义义成Book.java,Book 包含书名,作者,出版社和出版日期,这些数据都要定义getter和setter. 定义至少三个构造方法,接收并初始化这些数据. 覆 ...
- 【Topcoder 1879】Scheduling
题意:给一个\(dag\),每一个点有一个访问时间. 现在可以同时访问两个点,但当连向这个点的所有点都被访问完成后才可以访问这个点. 问最短访问时间. 思路:一眼贪心.可惜是错的. 第二眼暴搜.就这么 ...
- Spring Cloud:Security OAuth2 自定义异常响应
对于客户端开发或者网站开发而言,调用接口返回有统一的响应体,可以针对性的设计界面,代码结构更加清晰,层次也更加分明. 默认异常响应 在使用 Spring Security Oauth2 登录和鉴权失败 ...
- Mysql数据的增删改查
一 介绍 MySQL数据操作: DML 在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括 使用INSERT实现数据的插入 UPDATE实现数据的更新 使用DELETE实现 ...
- Django2.0 models中的on_delete参数
一.外键.OneToOne字段等on_delete为必须参数 如下ForeignKey字段源码,to.on_delete为必须参数 to:关联的表 on_delete:当该表中的某条数据删除后,关 ...
- 阿里云对象存储OSS与文件存储NAS的区别
一.简介 应用场景:选择一款存储产品,面向文档数据的存取,不会涉及到数据处理. 产品选型主要从OSS和NAS中选择一款,满足文档存储的需求. 二.NAS优缺点 NAS 是一种采用直接与网络介质相连的特 ...
- js02-常用流程控制语句
1.if语句 语法:if(条件){ 条件成立时执行 }else{ 条件不成立执行 } 例 var ji = 20; if(ji>=20){ console.log('恭喜你,吃鸡成功,大吉大利' ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):1. 自定义窗口部件 (widget)
1. 框架代码 用 PyCharm 新建一个名为 SimplePaintApp 的项目,然后新建一个名为 simple_paint_app.py 的 Python 源文件, 在代码编辑器中,输入以下框 ...
- 如何在网中使用百度地图API自定义个性化地图
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...