quartz基本介绍和使用
一、什么是quartz,有什么用。
Quartz是一个完全由java编写的开源作业调度框架,由OpenSymphony组织开源出来。所谓作业调度其实就是按照程序的设定,某一时刻或者时间间隔去执行某个代码。最常用的就是报表的制作了。
二、quartz的简单事例
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
Object tv1 = context.getTrigger().getJobDataMap().get("t1");
Object tv2 = context.getTrigger().getJobDataMap().get("t2");
Object jv1 = context.getJobDetail().getJobDataMap().get("j1");
Object jv2 = context.getJobDetail().getJobDataMap().get("j2");
Object sv = null;
try {
sv = context.getScheduler().getContext().get("skey");
} catch (SchedulerException e) {
e.printStackTrace();
}
System.out.println(tv1+":"+tv2);
System.out.println(jv1+":"+jv2);
System.out.println(sv);
System.out.println("hello:"+LocalDateTime.now());
}
}
public class Test {
public static void main(String[] args) throws SchedulerException {
//创建一个scheduler
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.getContext().put("skey", "svalue");
//创建一个Trigger
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group1")
.usingJobData("t1", "tv1")
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3)
.repeatForever()).build();
trigger.getJobDataMap().put("t2", "tv2");
//创建一个job
JobDetail job = JobBuilder.newJob(HelloJob.class)
.usingJobData("j1", "jv1")
.withIdentity("myjob", "mygroup").build();
job.getJobDataMap().put("j2", "jv2");
//注册trigger并启动scheduler
scheduler.scheduleJob(job,trigger);
scheduler.start();
}
}
二、quartz的基本组成
1、调度器--------------Scheduler
Scheduler被用来对Trigger和Job进行管理。Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中都拥有自己的唯一的组和名称用来进行彼此的区分,Scheduler可以通过组名或者名称来对Trigger和JobDetail来进行管理。一个Trigger只能对应一个Job,但是一个Job可以对应多个Trigger。每个Scheduler都包含一个SchedulerContext,用来保存Scheduler的上下文。Job和Trigger都可以获取SchedulerContext中的信息。
Scheduler包含两个重要的组件,JobStore和ThreadPool。JobStore用来存储运行时信息,包括Trigger,Schduler,JobDetail,业务锁等。它有多种实现RAMJob(内存实现),JobStoreTX(JDBC,事务由Quartz管理)等。ThreadPool就是线程池,Quartz有自己的线程池实现。所有任务的都会由线程池执行。
Scheduler是由SchdulerFactory创建,它有两个实现:DirectSchedulerFactory和 StdSchdulerFactory。前者可以用来在代码里定制你自己的Schduler参数。后者是直接读取classpath下的quartz.properties(不存在就都使用默认值)配置来实例化Schduler。通常来讲,我们使用StdSchdulerFactory也就足够了
2、触发器--------------Trigger
Trigger是用来定义Job的执行规则,主要有四种触发器,其中SimpleTrigger和CronTrigger触发器用的最多。
SimpleTrigger:从某一个时间开始,以一定的时间间隔来执行任务。它主要有两个属性,repeatInterval 重复的时间间隔;repeatCount 重复的次数,实际上执行的次数是n+1,因为在startTime的时候会执行一次。
CronTrigger:适合于复杂的任务,使用cron表达式来定义执行规则。
CalendarIntervalTrigger:类似于SimpleTrigger,指定从某一个时间开始,以一定的时间间隔执行的任务。 但是CalendarIntervalTrigger执行任务的时间间隔比SimpleTrigger要丰富,它支持的间隔单位有秒,分钟,小时,天,月,年,星期。相较于SimpleTrigger有两个优势:1、更方便,比如每隔1小时执行,你不用自己去计算1小时等于多少毫秒。 2、支持不是固定长度的间隔,比如间隔为月和年。但劣势是精度只能到秒。它的主要两个属性,interval 执行间隔;intervalUnit 执行间隔的单位(秒,分钟,小时,天,月,年,星期)
DailyTimeIntervalTrigger:指定每天的某个时间段内,以一定的时间间隔执行任务。并且它可以支持指定星期。它适合的任务类似于:指定每天9:00 至 18:00 ,每隔70秒执行一次,并且只要周一至周五执行。它的属性有startTimeOfDay 每天开始时间;endTimeOfDay 每天结束时间;daysOfWeek 需要执行的星期;interval 执行间隔;intervalUnit 执行间隔的单位(秒,分钟,小时,天,月,年,星期);repeatCount 重复次数
所有的trigger都包含了StartTime和endTIme这两个属性,用来指定Trigger被触发的时间区间。
所有的trigger都可以设置MisFire策略,该策略是对于由于系统奔溃或者任务时间过长等原因导致trigger在应该触发的时间点没有触发,并且超过了misfireThreshold设置的时间(默认是一分钟,没有超过就立即执行)就算misfire了,这个时候就该设置如何应对这种变化了。激活失败指令(Misfire Instructions)是触发器的一个重要属性,它指定了misfire发生时调度器应当如何处理。所有类型的触发器都有一个默认的指令,叫做Trigger.MISFIRE_INSTRUCTION_SMART_POLICY,但是这个这个“聪明策略”对于不同类型的触发器其具体行为是不同的。对于SimpleTrigger,这个“聪明策略”将根据触发器实例的状态和配置来决定其行 为。具体如下[]:
如果Repeat Count=0:只执行一次
instruction selected = MISFIRE_INSTRUCTION_FIRE_NOW;
如果Repeat Count=REPEAT_INDEFINITELY:无限次执行
instruction selected = MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT;
如果Repeat Count>0: 执行多次(有限)
instruction selected = MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT;
下面解释SimpleTrigger常见策略:
MISFIRE_INSTRUCTION_FIRE_NOW 立刻执行。对于不会重复执行的任务,这是默认的处理策略。
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT 在下一个激活点执行,且超时期内错过的执行机会作废。
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_COUNT 立即执行,且超时期内错过的执行机会作废。
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT 在下一个激活点执行,并重复到指定的次数。
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_COUNT 立即执行,并重复到指定的次数。
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY 忽略所有的超时状态,按照触发器的策略执行。
对于CronTrigger,该“聪明策略”默认选择MISFIRE_INSTRUCTION_FIRE_ONCE_NOW以指导其行为。
下面解释CronTrigger常见策略:
MISFIRE_INSTRUCTION_FIRE_ONCE_NOW 立刻执行一次,然后就按照正常的计划执行。
MISFIRE_INSTRUCTION_DO_NOTHING 目前不执行,然后就按照正常的计划执行。这意味着如果下次执行时间超过了end time,实际上就没有执行机会了。
3、任务-----------------Job
Job是一个任务接口,开发者定义自己的任务须实现该接口实现void execute(JobExecutionContext context)方法,JobExecutionContext中提供了调度上下文的各种信息。Job中的任务有可能并发执行,例如任务的执行时间过长,而每次触发的时间间隔太短,则会导致任务会被并发执行。如果是并发执行,就需要一个数据库锁去避免一个数据被多次处理。可以在execute()方法上添加注解@DisallowConcurrentExecution解决这个问题。
4、任务详情-----------JobDetail
Quartz在每次执行Job时,都重新创建一个Job实例,所以它不直接接受一个Job的实例,相反它接收一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。因此需要通过一个类来描述Job的实现类及其它相关的静态信息,如Job名字、描述、关联监听器等信息,JobDetail承担了这一角色。所以说JobDetail是任务的定义,而Job是任务的执行逻辑。
5、日历------------------Calendar
Calendar:org.quartz.Calendar和java.util.Calendar不同,它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。一个Trigger可以和多个Calendar关联,以便排除或包含某些时间点。
主要有以下Calendar
HolidayCalendar。指定特定的日期,比如20140613。精度到天。
DailyCalendar。指定每天的时间段(rangeStartingTime, rangeEndingTime),格式是HH:MM[:SS[:mmm]]。也就是最大精度可以到毫秒。
WeeklyCalendar。指定每星期的星期几,可选值比如为java.util.Calendar.SUNDAY。精度是天。
MonthlyCalendar。指定每月的几号。可选值为1-31。精度是天
AnnualCalendar。 指定每年的哪一天。使用方式如上例。精度是天。
CronCalendar。指定Cron表达式。精度取决于Cron表达式,也就是最大精度可以到秒。
6、JobDataMap
用来保存JobDetail运行时的信息,JobDataMap的使用:.usingJobData("name","kyle")或者.getJobDataMap("name","kyle")
7、cron表达式
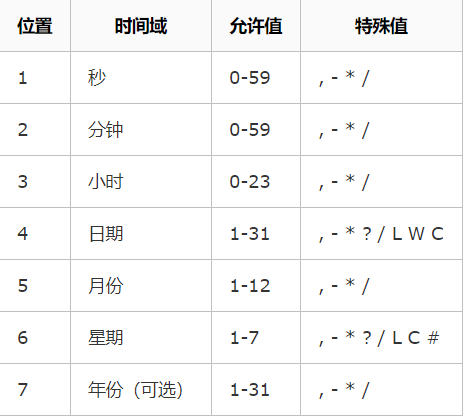
Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感
星号():可用在所有字段中,表示对应时间域的每一个时刻,例如, 在分钟字段时,表示“每分钟”;
问号(?):该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于点位符;
减号(-):表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12;
逗号(,):表达一个列表值,如在星期字段中使用“MON,WED,FRI”,则表示星期一,星期三和星期五;
斜杠(/):x/y表达一个等步长序列,x为起始值,y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒,而5/15在分钟字段中表示5,20,35,50,你也可以使用*/y,它等同于0/y;
L:该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中意思不同。L在日期字段中,表示这个月份的最后一天,如一月的31号,非闰年二月的28号;如果L用在星期中,则表示星期六,等同于7。但是,如果L出现在星期字段里,而且在前面有一个数值X,则表示“这个月的最后X天”,例如,6L表示该月的最后星期五;
W:该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如15W表示离该月15号最近的工作日,如果该月15号是星期六,则匹配14号星期五;如果15日是星期日,则匹配16号星期一;如果15号是星期二,那结果就是15号星期二。但必须注意关联的匹配日期不能够跨月,如你指定1W,如果1号是星期六,结果匹配的是3号星期一,而非上个月最后的那天。W字符串只能指定单一日期,而不能指定日期范围;
LW组合:在日期字段可以组合使用LW,它的意思是当月的最后一个工作日;
井号(#):该字符只能在星期字段中使用,表示当月某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三,假设当月没有第五个星期三,忽略不触发;
C:该字符只在日期和星期字段中使用,代表“Calendar”的意思。它的意思是计划所关联的日期,如果日期没有被关联,则相当于日历中所有日期。例如5C在日期字段中就相当于日历5日以后的第一天。1C在星期字段中相当于星期日后的第一天。
8、quartz.properties文件编写
####################RAMJob的配置##################
#在集群中每个实例都必须有一个唯一的instanceId,但是应该有一个相同的instanceName【默认“QuartzScheduler”】【非必须】
org.quartz.scheduler.instanceName = MyScheduler
#Scheduler实例ID,全局唯一,【默认值NON_CLUSTERED】,或者可以使用“SYS_PROP”通过系统属性设置id。【非必须】
org.quartz.scheduler.instanceId=AUTO
# 线程池的实现类(定长线程池,几乎可满足所有用户的需求)【默认null】【必须】
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
# 指定线程数,至少为1(无默认值)(一般设置为1-100直接的整数合适)【默认-1】【必须】
org.quartz.threadPool.threadCount = 25
# 设置线程的优先级(最大为java.lang.Thread.MAX_PRIORITY 10,最小为Thread.MIN_PRIORITY 1)【默认Thread.NORM_PRIORITY (5)】【非必须】
org.quartz.threadPool.threadPriority = 5
#misfire设置的时间默认为一分钟
org.quartz.jobStore.misfireThreshold=60000
# 将schedule相关信息保存在RAM中,轻量级,速度快,遗憾的是应用重启时相关信息都将丢失。
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
# 建议设置为“org.terracotta.quartz.skipUpdateCheck=true”不会在程序运行中还去检查quartz是否有版本更新。【默认false】【非必须】
org.quartz.scheduler.skipUpdateCheck = true
###################jdbcJobStore############################
org.quartz.scheduler.instanceName=MyScheduler
org.quartz.scheduler.instanceId=AUTO
org.quartz.threadPool.threadCount=3
# 所有的quartz数据例如job和Trigger的细节信息被保存在内存或数据库中,有两种实现:JobStoreTX(自己管理事务)
#和JobStoreCMT(application server管理事务,即全局事务JTA)
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
# 类似于Hibernate的dialect,用于处理DB之间的差异,StdJDBCDelegate能满足大部分的DB
org.quartz.jobStore.driverDelegateClass =org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#数据库表的前缀
org.quartz.jobStore.tablePrefix=QRTZ_
#配置数据源的名称
org.quartz.jobStore.dataSource=myDS
#为了指示JDBCJobStore所有的JobDataMaps中的值都是字符串,并且能以“名字-值”对的方式存储而不是以复杂对象的序列化形式存储在BLOB字段中,应该设置为true(缺省方式)
org.quartz.jobStore.useProperties = true
# 检入到数据库中的频率(毫秒)。检查是否其他的实例到了应当检入的时候未检入这能指出一个失败的实例,
#且当前Scheduler会以此来接管执行失败并可恢复的Job通过检入操作,Scheduler也会更新自身的状态记录
org.quartz.jobStore.clusterCheckinInterval=20000
# 是否集群、负载均衡、容错,如果应用在集群中设置为false会出错
org.quartz.jobStore.isClustered=false
#misfire时间设置
org.quartz.jobStore.misfireThreshold=60000
# 连接超时重试连接的间隔。使用 RamJobStore时,该参数并没什么用【默认15000】【非必须】
#org.quartz.scheduler.dbFailureRetryInterval = 15000
#下面是数据库链接相关的配置
org.quartz.dataSource.myDS.driver=com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL=jdbc:mysql://localhost:3306/zproject?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=UTC
org.quartz.dataSource.myDS.user=root
org.quartz.dataSource.myDS.password=root
org.quartz.dataSource.myDS.maxConnections=5
三、quartz的简单使用
1、首先就是引入相关的jar包

2、编写quartz.properies文件:参考上面的properties文件的编写。
3、编写代码
@DisallowConcurrentExecution
public class MyJob implements Job { @Override
public void execute(JobExecutionContext arg0) throws JobExecutionException {
String name = arg0.getJobDetail().getKey().getName();
System.out.println(name+"这是第一个定时任务"+LocalDateTime.now());
} }
public class Test {
public static void main(String[] args) throws SchedulerException, InterruptedException {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
JobDetail jobDetail = JobBuilder.newJob(MyJob.class).withIdentity("MyJob","Group1").build();
JobDetail jobDetail2 = JobBuilder.newJob(MyJob.class).withIdentity("MyJob2","Group2").build();
JobDetail jobDetail3 = JobBuilder.newJob(MyJob.class).withIdentity("MyJob3","Group3").build();
JobDetail jobDetail4 = JobBuilder.newJob(MyJob.class).withIdentity("MyJob4","Group4").build();
Calendar cal1 = Calendar.getInstance();
cal1.set(Calendar.MINUTE, 28);
cal1.set(Calendar.SECOND, 0);
Calendar cal2 = Calendar.getInstance();
cal2.set(Calendar.MINUTE, 29);
cal2.set(Calendar.SECOND, 0);
DailyCalendar dailyCalendar = new DailyCalendar(cal1, cal2);
scheduler.addCalendar("dailyCalendar", dailyCalendar, false, false);
CronTrigger cronTrigger = TriggerBuilder.newTrigger().withIdentity("tigger1","TGroup1")
.withSchedule(CronScheduleBuilder.cronSchedule("/2 * * * * ?")).build();
SimpleTrigger simpleTrigger = TriggerBuilder.newTrigger().withIdentity("trigger2","TGroup2")
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(5, 10)).build();
CalendarIntervalTrigger citrigger = TriggerBuilder.newTrigger().withIdentity("trigger3","TGroup3")
.withSchedule(CalendarIntervalScheduleBuilder.calendarIntervalSchedule()
.withIntervalInSeconds(10)).modifiedByCalendar("dailyCalendar").build();
DailyTimeIntervalTrigger dtiTrigger = TriggerBuilder.newTrigger().withIdentity("trigger4","TGroup4")
.withSchedule(DailyTimeIntervalScheduleBuilder.dailyTimeIntervalSchedule()
.startingDailyAt(TimeOfDay.hourAndMinuteOfDay(16, 43))
.endingDailyAt(TimeOfDay.hourAndMinuteOfDay(16, 44))
.withIntervalInSeconds(5)
.withRepeatCount(20))
.build();
scheduler.scheduleJob(jobDetail, cronTrigger);
scheduler.scheduleJob(jobDetail2, simpleTrigger);
scheduler.scheduleJob(jobDetail3, citrigger);
scheduler.scheduleJob(jobDetail4, dtiTrigger);
scheduler.start();
}
}
四、quartz的持久化中的表信息
quartz有两种存储方式,1.存储到内存中,2.存储到 数据库中;下面是数据库中各表的含义
qrtz_blob_triggers :这张表示存储自己定义的trigger,不是quartz自己提供的trigger
qrtz_calendars :存储Calendar
qrtz_cron_triggers :存储cronTrigger
qrtz_fired_triggers :存储触发的Tirgger
qrtz_job_details :存储JobDetail
qrtz_locks :存储程序中非悲观锁的信息
qrtz_paused_trigger_grps :存储已暂停的Trigger组信息
qrtz_scheduler_state :存储集群中note实例信息,quartz会定时读取该表的信息判断集群中每个实例的当前状态
qrtz_simple_triggers :存储simpleTrigger的信息
qrtz_simprop_triggers :储存CalendarIntervalTrigger和DailyTimeIntervalTrigger的信息
qrtz_triggers :存储已配置的trigger信息
quartz基本介绍和使用的更多相关文章
- Quartz学习——Quartz大致介绍(一)
1. 介绍 Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,是完全由java开发的一个开源的任务日程管理系统,"任务进度管理器"就是 ...
- Quartz大致介绍(一)
1. 介绍 Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,是完全由java开发的一个开源的任务日程管理系统,“任务进度管理器”就是一个在预先确定(被纳 ...
- Quartz学习——Quartz大致介绍 转
转自阿飞先生 http://blog.csdn.net/u010648555/article/details/54863144 1. 介绍 Quartz是OpenSymphony开源组织在Job sc ...
- Quartz学习-- quartz基本介绍和 Cron表达式
Quartz学习 一. Quartz 大致简介 Quartz 是完全由 java 开发的一个开源的任务日程管理系统 任务日程管理系统 换句话说就是: 一个预先确定的日程时间到达时,负责执行任务的 ...
- Quartz框架介绍
一.Quartz概述: Quartz是一个完全由Java编写的开源任务调度的框架,通过触发器设置作业定时运行规则,控制作业的运行时间.其中quartz集群通过故障切换和负载平衡的功能,能给调度器带来高 ...
- 开源任务管理平台TaskManager介绍
很早之前准备写Quartz系列文章,现在终于能够实现了.从本篇开始将带你实现一款自己的任务管理平台.在工作中你曾经需要应用执行一个任务吗?这个任务每天或每周星期二晚上11:30,或许仅仅每个月的最后一 ...
- 使用Quartz.NET进行任务调度管理
1.Quartz.NET 介绍 Quartz.NET是一个开源的作业调度框架,是OpenSymphony 的 Quartz API的.NET移植,它用C#写成,可用于winform和asp.net应用 ...
- Quartz.Net实现定时任务调度
Quartz.Net介绍: Quartz一个开源的作业调度框架,OpenSymphony的开源项目.Quartz.Net 是Quartz的C#移植版本. 它一些很好的特性: 1:支持集群,作业分组,作 ...
- .Net平台开源作业调度框架Quartz.Net
Quartz.NET介绍: Quartz.NET是一个开源的作业调度框架,是OpenSymphony 的 Quartz API的.NET移植,它用C#写成,可用于winform和asp.net应用中. ...
随机推荐
- java的设计模式 - 外观模式(Facade)
目的 看脸模式目的很简单,就是给用户留个好印象,不想让用户关注系统中的具体细节,关注系统的外表(暴露出来的接口)就好了.一些 GUI 的菜单也好,SDK 也好或多或少也会用到这种思想.这更多的是一种思 ...
- SQL SERVER 临时数据库 tempdb 迁移或增加文件
临时数据库TempDB 虽然是临时库,但对整个数据库系统性能却起到很关键的作用:平时用到的中间数据集会暂时保存到TempDB 中,比如:临时表,排序,临时统计信息,一些中间结果数据,索引重建 等.我们 ...
- Eclipse 模板
Eclipse 的模板:推荐一个好的内容 设置注释模板的入口:Window->Preference->Java->Code Style->Code Template 然后展开C ...
- 阿狸V任务页面爬取数据解析
需求: 爬取:https://v.taobao.com/v/content/video 所有主播详情页信息 首页分析 分析可以得知数据是通过ajax请求获取的. 分析请求头 详情页分析 详情页和详情页 ...
- vue 前端将时间戳格式化
转自西风XF : https://blog.csdn.net/qq_36242361/article/details/79143050 后端传过来的时间数据是时间戳的形式,前端需要进行格式化 1. 新 ...
- CentOS7.x安装MySQL5.7.25
mysql 5.7下载地址 社区版下载地址:https://dev.mysql.com/downloads/mysql/ 可能会有变动 找到5.7版本, 注:源码安装需要用到下面的包,可以先忽略,我安 ...
- BZOJ 1171: 大sz的游戏
ZJOI讲课的题目,数据结构什么的还是很友好的说 首先我们发现题目中提到的距离\(\le L\)的东西显然可以用单调队列维护 但是暴力搞去不掉区间并的限制,那么我们考虑从区间并入手 对于这种问题的套路 ...
- .NET 增加扩展方法
声明:通过一个js的实例来告诉你C#也可以实现这样的效果. 在JS中是这样实现的: 你是否见过JS中给系统默认Array对象增加一个自定义查重方法contains 在没有给Array原型上增加cont ...
- phpcms不能批量更新栏目页和内容页
需要给网站根目录更加users用户的写入权限.
- Python百题计划
一.基础篇 想要像类似执行shell脚本一样执行Python脚本,需要在py文件开头加上什么?KEY:#!/usr/bin/env python Python解释器在加载 .py 文件中的代码时,会对 ...