【Python】Scrapy基础
一、Scrapy 架构
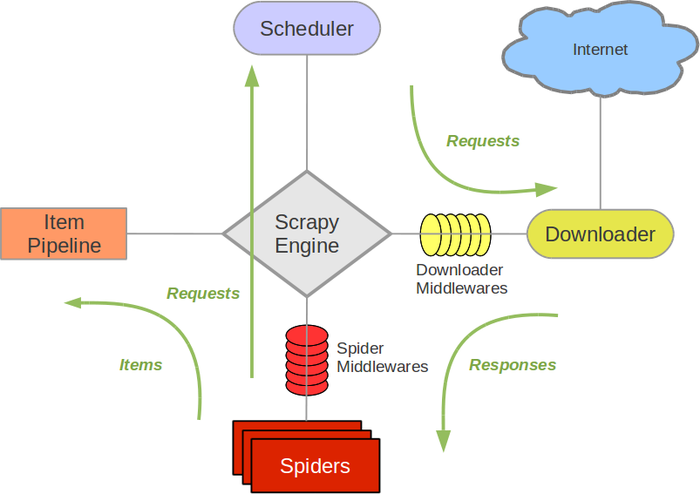
- Engine(引擎):负责 Spider(爬虫)、Item Pipeline(管道)、Downloader(下载器)、Scheduler(调度器)中的通讯和数据传递。
- Scheduler:接受 Engine 发送过来的 Request 请求,按照一定方式入队,再交给 Downloader 下载。可实现去重。Scheduler 的请求队列为空时,程序才会终止。
- Downloader:下载 Engine 发送(中间通过Scheduler)的所有 Requests 请求,并将其获取到的 Responses 交还给 Engine,由 Engine 交给 Spider 处理。
- Spider:处理所有 Responses ①提取 Item 字段需要的数据,交给 Pipeline 存储 ②将需要跟进的 URL 提交给 Engine,再进入 Scheduler。
- Item Pipeline:负责处理 Spider 提取到的 Item,并进行后期处理,例如分析过滤数据,按自己定制的格式保存到 json、数据库等。
- Downloader Middlewares:自定义扩展下载功能,例如给每个 Request 加代理、User-Agent 等。
- Spider Middlewares:自定义扩展 Engine 和 Spider 中间的通信,例如进入 Spider 的 Responses、从 Spider 出去的Requests。用处不大,大部分爬虫功能在 Spider 里实现。
二、Scrapy 安装
1、Windows
- pip install scrapy
2、Linux
- 安装非 python 依赖:sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
- sudo pip install scrapy
三、官方文档
四、
【Python】Scrapy基础的更多相关文章
- python scrapy 基础
scrapy是用python写的一个库,使用它可以方便的抓取网页. 主页地址http://scrapy.org/ 文档 http://doc.scrapy.org/en/latest/index.ht ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- Python——Scrapy初学
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中.Scrapy最初是为了页面抓取(更确切来说, 网络抓取)所设计的,也 ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- Python.Scrapy.14-scrapy-source-code-analysis-part-4
Scrapy 源代码分析系列-4 scrapy.commands 子包 子包scrapy.commands定义了在命令scrapy中使用的子命令(subcommand): bench, check, ...
- Python.Scrapy.11-scrapy-source-code-analysis-part-1
Scrapy 源代码分析系列-1 spider, spidermanager, crawler, cmdline, command 分析的源代码版本是0.24.6, url: https://gith ...
- Python文件基础
===========Python文件基础========= 写,先写在了IO buffer了,所以要及时保存 关闭.关闭会自动保存. file.close() 读取全部文件内容用read,读取一行用 ...
- python scrapy cannot import name xmlrpc_client的解决方案,解决办法
安装scrapy的时候遇到如下错误的解决办法: "python scrapy cannot import name xmlrpc_client" 先执行 sudo pip unin ...
随机推荐
- JavaScript字符串字节长度
var txt2="He中!!";var t = txt2.replace(/[^\u0000-\u00ff]/g,"aa").length;//值是7
- 使用gulp构建一个项目
gulp是前端开发过程中自动构建项目的工具,相同作用的还有grunt.构建工具依靠插件能够自动监测文件变化以及完成js/sass/less/html/image/css/coffee等文件的语法检查. ...
- js数组创建两种方法
一.数组直接量形式创建数组 var arr=[];//空数组 ,,,,,]; ,,,],{x:,y:}]; ; ,x+,x+]; console.log(arr3); //[1,3,3,4] ,,]; ...
- idea的mybatis的mysql语句的小数转换百分号
其实mysql的小数转换百分数有两种函数ROUND和TRUNCATE 例子: 1.round(x,d) :用于数据的四舍五入,round(x) ,其实就是round(x,0),也就是默认d为0: 这 ...
- rabbitMQ Management http://localhost:15672/ 打不开
C:\RabbitMQ Server\rabbitmq_server-3.7.7\sbin>rabbitmq-plugins enable rabbitmq_management 安装rabbi ...
- vue项目创建过程
在使用vue-cli之前,请确认你的电脑已经安装了 node,建议版本在 8.0.0 以上 可以通过node -v 检查版本 1.安装 vue-cli (这里我们确认已安装过node) 1.使用 np ...
- js 获取屏幕或元素宽高...
窗口相对于屏幕顶部距离 window.screenTop 窗口相对于屏幕左边距离 window.screenLeft, 屏幕分辨率的高 window.screen.height, 屏幕分辨率的宽 wi ...
- MyElasticsearch
目录 那些必须要知道的事儿 搭建elasticsearch环境 快速上手 elasticsearch分析数据的过程漫谈 建议器:Suggester IK中文分词器 elasticsearch for ...
- sql*loader以及oracle外部表加载Date类型列
Oracle sqlldr LOAD DATAINFILE *INTO TABLE testFIELDS TERMINATED BY X'9'TRAILING NULLCOLS( c2 &quo ...
- XUnit测试框架-Python unittest
选择 语言选择 本次个人作业我选择的语言是Python,了解学习Python有一段时间了但是一直没有练习,所以这次玩蛇,使用的版本是Python3.6. 开发工具选择 我选择的IDE是Pycharm, ...