storm集群架构
Storm 是Twitter的一个开源框架。Storm一个分布式的、容错的实时计算系统,它被托管在GitHub上,遵循 Eclipse Public License 1.0。Storm是由BackType开发的实时处理系统,BackType现在已在Twitter麾下。GitHub上的最新版本是Storm 0.9.0.1,基本是用Clojure写的。
Twitter Storm集群表面上类似于Hadoop集群,Hadoop上运行的是MapReduce Jobs,而Storm运行topologies;但是其本身有很大的区别,最主要的区别在于,Hadoop MapReduce Job运行最终会完结,而Storm topologies处理数据进程理论上是永久存活的,除非你将其Kill掉。
Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node)。
二、其分别对应的角色如下:
1. 主控节点(Master Node)上运行一个被称为Nimbus的后台程序,它负责在Storm集群内分发代码,分配任务给工作机器,并且负责监控集群运行状态。Nimbus的作用类似于Hadoop中JobTracker的角色。
2. 每个工作节点(Work Node)上运行一个被称为Supervisor的后台程序。Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程。每一个工作进程执行一个Topology的子集;一个运行中的Topology由分布在不同工作节点上的多个工作进程组成。
Nimbus和Supervisor节点之间所有的协调工作是通过Zookeeper集群来实现的。此外,Nimbus和Supervisor进程都是快速失败(fail-fast)和无状态(stateless)的;Storm集群所有的状态要么在Zookeeper集群中,要么存储在本地磁盘上。这意味着你可以用kill -9来杀死Nimbus和Supervisor进程,它们在重启后可以继续工作。这个设计使得Storm集群拥有不可思议的稳定性。
在Storm集群上要实现实时计算,需要创建Topologies。一个Topology是一个计算的曲线图。Topology中的每个节点包含处理逻辑,并且节点之间的链路表示数据如何应围绕节点之间传递。
运行一个Topology比较简单,首先,你打包所有的代码和依赖关系的包打成一个jar包。然后,您运行如下命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
这里运行一个包含arg1和arg2两个参数的backtype.storm.MyTopology类。main方法定义Topology以及提交到Nimbus,storm jar部分连接Nimbus以及上传jar包到集群。
由于Topology的定义是Thirf结构,并且Nimbus是一个Thirf 服务,所以你可以使用任何语言创建以及提交Topology。
Storm是一个实时流处理框架,那么它的抽象核心当然就是流。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。 Storm的主工程师Nathan Marz表示:
Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm之于实时处理,就好比 Hadoop之于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
三、Storm的主要特点如下:
2)可以使用各种编程语言:你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
3)容错性:Storm会管理工作进程和节点的故障。
4)水平扩展:计算是在多个线程、进程和服务器之间并行进行的。
5)可靠的消息处理:Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
7)本地模式:Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
四、Storm集群架构
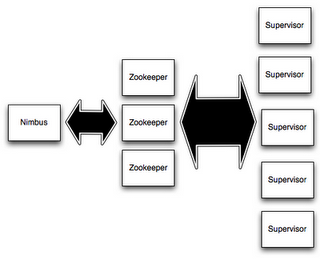
Storm集群采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储到ZooKeeper集群中,架构如下图所示:
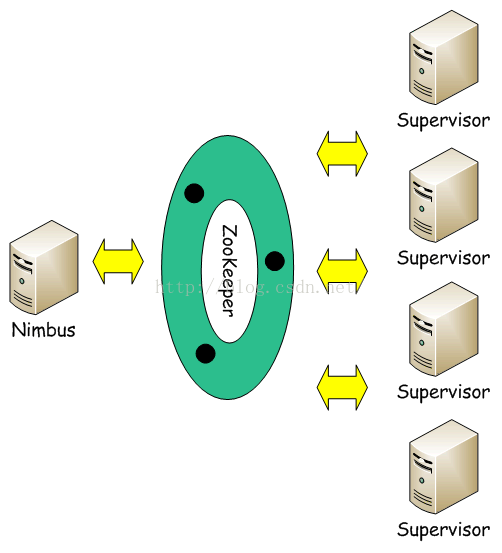
具体描述,如下所示:
Nimbus
Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor
Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。通过Storm的配置文件中的supervisor.slots.ports配置项,可以指定在一个Supervisor上最大允许多少个Slot,每个Slot通过端口号来唯一标识,一个端口号对应一个Worker进程(如果该Worker进程被启动)。
ZooKeeper
用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其它可用的Supervisor上运行。
Stream Groupings
Storm中最重要的抽象,应该就是Stream grouping了,它能够控制Spot/Bolt对应的Task以什么样的方式来分发Tuple,将Tuple发射到目的Spot/Bolt对应的Task,如下图所示:
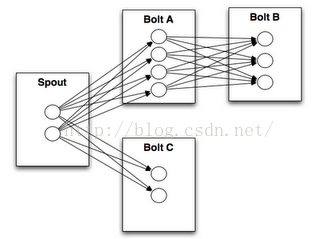
目前,Storm Streaming Grouping支持如下几种类型:
Shuffle Grouping:随机分组,跨多个Bolt的Task,能够随机使得每个Bolt的Task接收到大致相同数目的Tuple,但是Tuple不重复
Fields Grouping:根据指定的Field进行分组 ,同一个Field的值一定会被发射到同一个Task上
Partial Key Grouping:与Fields grouping 类似,根据指定的Field的一部分进行分组分发,能够很好地实现Load balance,将Tuple发送给下游的Bolt对应的Task,特别是在存在数据倾斜的场景,使用 Partial Key grouping能够更好地提高资源利用率
All Grouping:所有Bolt的Task都接收同一个Tuple(这里有复制的含义)
Global Grouping:所有的流都指向一个Bolt的同一个Task(也就是Task ID最小的)
None Grouping:不需要关心Stream如何分组,等价于Shuffle grouping
Direct Grouping:由Tupe的生产者来决定发送给下游的哪一个Bolt的Task ,这个要在实际开发编写Bolt代码的逻辑中进行精确控制
Local or Shuffle Grouping:如果目标Bolt有1个或多个Task都在同一个Worker进程对应的JVM实例中,则Tuple只发送给这些Task
另外,Storm还提供了用户自定义Streaming Grouping接口,如果上述Streaming Grouping都无法满足实际业务需求,也可以自己实现,只需要实现backtype.storm.grouping.CustomStreamGrouping接口,该接口定义了如下方法:
List<Integer> chooseTasks(int taskId, List<Object> values)
上面几种Streaming Group的内置实现中,最常用的应该是Shuffle Grouping、Fields Grouping、Direct Grouping这三种,使用其它的也能满足特定的应用需求。
感谢您阅读本文章,更多内容或支持推荐您点击 上海大数据培训
storm集群架构的更多相关文章
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- storm 集群配置
配置storm集群的过程中出现写问题,记录下来 1.storm是通过zookeeper管理的,先要安装zookeeper,从zk官网上下来,我这里下下来的的3.4.9,下载后移动到/usr/local ...
- storm集群部署和配置过程详解
先整体介绍一下搭建storm集群的步骤: 设置zookeeper集群 安装依赖到所有nimbus和worker节点 下载并解压storm发布版本到所有nimbus和worker节点 配置storm ...
- 在CentOS上搭建Storm集群
Here's a summary of the steps for setting up a Storm cluster: Set up a Zookeeper clusterInstall depe ...
- Storm系列(三):创建Maven项目打包提交wordcount到Storm集群
在上一篇博客中,我们通过Storm.Net.Adapter创建了一个使用Csharp编写的Storm Topology - wordcount.本文将介绍如何编写Java端的程序以及如何发布到测试的S ...
- MongoDB集群架构及搭建
MongoDB分布式集群 MongDB分布式集群能够对数据进行备份,提高数据安全性,以及提高集群提高读写服务的能力和数据存储能力.主要通过副本集(replica)对数据进行备份,通过分片(shardi ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm集群的安装配置
Storm集群的安装分为以下几步: 1.首先保证Zookeeper集群服务的正常运行以及必要组件的正确安装 2.释放压缩包 3.修改storm.yaml添加集群配置信息 4.使用storm脚本启动相应 ...
- Storm集群部署
一. 说明 Storm是一个分布式实时计算系统,Storm对于实时计算的意义就相当于Hadoop对于批量计算的意义.对于实时性较高的系统Storm是不错的选择.Hadoop提供了map, reduce ...
随机推荐
- lr 中cookie的解释与用法
Loadrunner 中 cookie 解释与用法loadrunner 中与 cookie 处理相关的常用函数如下: web_add_cookie(): 添加新的 cookie 或者修改已经存在的 c ...
- OpenStack—nova组件计算服务
nova介绍: Nova 是 OpenStack 最核心的服务,负责维护和管理云环境的计算资源.OpenStack 作为 IaaS 的云操作系统,虚拟机生命周期管理也就是通过 Nova 来实现的. 用 ...
- 2018-2019-2 《网络对抗技术》Exp0 Kali安装 Week1
- 2018-2019-2 <网络对抗技术>Exp0 Kali安装 Week1 - 安装过程 - 安装Kali VMware上学期已经装好了,Kali的镜像文件是从同学那拷过来的,所以这两 ...
- oracle 启动三步骤
oracle 启动三步骤 oracle启动会经过三个过程,分别是nomount.mount.open 一.nomount 阶段 nomount 阶段,可以看到实例已经启动.oracle进程会根据参数文 ...
- buaaoo_first_assignment
四周之前,我不懂面向对象是什么:四周之后,我依然不懂面向对象是什么. 一.第一次作业 (1)实现 说起来,本次作业是最惨烈的一次. 虽然它很简单,但由于未熟悉正则表达式的应用,导致判断wrong fo ...
- Gradle 下载的依赖包在什么位置?
Mac系统默认下载到:/Users/(用户名)/.gradle/caches/modules-2/files-2.1Windows系统默认下载到:C:\Users\(用户名)\.gradle\cach ...
- Linux中设置服务自启动的三种方式,ln -s 建立启动软连接
有时候我们需要Linux系统在开机的时候自动加载某些脚本或系统服务(http://www.0830120.com) 主要用三种方式进行这一操作: ln -s 在/etc/rc.d/rc*.d目录中建立 ...
- Linux系统下一个冷门的RAID卡ioc0及其监控mpt-status
新接手了一台Linux服务器,准备检查是否有配置RAID.参考(http://mip.0834jl.com) 先查看是否有RAID卡: 复制代码 代码如下: # dmesg|grep -i raid ...
- 小程序API
基础: wx.canIUse(string) boolean wx.canIUse(string schema) 判断小程序的API,回调,参数,组件等是否在当前版本可用. 参数说明 ${A ...
- vue-cli3.0安装element-ui组件及按需引入element-ui组件
在VUE-CLI 3下的第一个Element-ui项目(菜鸟专用) (https://www.cnblogs.com/xzqyun/p/10780659.html) 上面这个链接是vue-cli3.0 ...