python爬虫简单的添加代理进行访问
在使用python对网页进行多次快速爬取的时候,访问次数过于频繁,服务器不会考虑User-Agent的信息,会直接把你视为爬虫,从而过滤掉,拒绝你的访问,在这种时候就需要设置代理,我们可以给proxies属性设置一个代理的IP地址,代码如下:
import requests
from lxml import etree
url = "https://www.ip.cn"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 OPR/57.0.3098.116", }
pro = {
# 'https': 'https://118.122.92.252:37901', #四川省成都市 电信
'https': 'https://27.17.45.90:43411', #湖北省武汉市 电信
}
try:
response = requests.get(url, headers=headers, proxies=pro)
html_str = response.content.decode()
# print(html_str)
html = etree.HTML(html_str)
message = html.xpath("//div[@class='well']//p/text()")
ip = html.xpath("//div[@class='well']//p/code/text()")
eng = html.xpath("//div[@class='well']/p/text()")
print(message[0]+ip[0])
print(message[1]+ip[1])
print(eng[2])
except requests.exceptions.ProxyError as e:
print("当前代理异常")
except:
print("当前请求异常")
在上面的代码中,调用requests库,对一个IP地址查询网页进行访问,随后使用lxml库的xpath对网页进行分析提取,返回用户访问此网页时自己的IP地址,如果代理设置成功,则会返回你的信息和IP地址,如下:
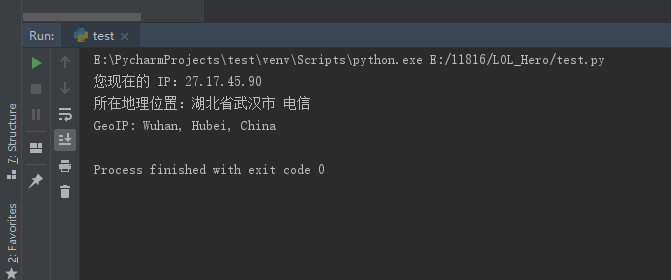
如果代理失败则会返回异常,在代码中使用了捕获异常,则会返回设置的提示信息,"当前代理异常",如果不是代理的错误则是"当前请求异常"
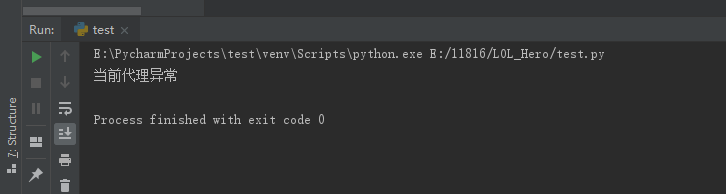
PS:免费的代理不是很稳定,在确认代码无误后,如果仍然返回异常,可尝试更换代理IP...
python爬虫简单的添加代理进行访问的更多相关文章
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Python爬虫简单入门及小技巧
刚刚申请博客,内心激动万分.于是为了扩充一下分类,随便一个随笔,也为了怕忘记新学的东西由于博主十分怠惰,所以本文并不包含安装python(以及各种模块)和python语法. 目标 前几天上B站时看到一 ...
- python爬虫——selenium+chrome使用代理
先看下本文中的知识点: python selenium库安装 chrome webdirver的下载安装 selenium+chrome使用代理 进阶学习 搭建开发环境: selenium库 chro ...
- python爬虫——requests库使用代理
在看这篇文章之前,需要大家掌握的知识技能: python基础 html基础 http状态码 让我们看看这篇文章中有哪些知识点: get方法 post方法 header参数,模拟用户 data参数,提交 ...
- [python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标 ...
- Python爬虫--简单爬取图片
今天晚上弄了一个简单的爬虫,可以爬取网页的图片,现在现在做一下准备工作. 需要的库:urllib 和 re urllib库可以理解为是一个url下载器,其中有三个重要的方法 urllib.urlope ...
- python爬虫之Scrapy 使用代理配置
转载自:http://www.python_tab.com/html/2014/pythonweb_0326/724.html 在爬取网站内容的时候,最常遇到的问题是:网站对IP有限制,会有防抓取功能 ...
- Python爬虫简单介绍
相关环境: Python3 requests库 BeautifulSoup库 一.requests库简单使用 简单获取一个网页的源代码: import requests sessions = requ ...
- python爬虫之Scrapy 使用代理配置——乾颐堂
在爬取网站内容的时候,最常遇到的问题是:网站对IP有限制,会有防抓取功能,最好的办法就是IP轮换抓取(加代理) 下面来说一下Scrapy如何配置代理,进行抓取 1.在Scrapy工程下新建“middl ...
随机推荐
- UOJ#42. 【清华集训2014】Sum 类欧几里德算法
原文链接https://www.cnblogs.com/zhouzhendong/p/UOJ42.html 题解 首先我们把式子改写一下: $$(-1)^{\lfloor a\rfloor} \\=1 ...
- symfony-表单学习
---恢复内容开始--- 构成表单的几个元素 1.数据模型 M 一种比较抽象的概念,按我的理解来说,本质上就是数据的一种存在形式,可以看做一个类,一般对这些模型进行crud操作.一种是真实存在的数据模 ...
- WRITE T AFTER ADVANCING 2 LINES
WRITE T AFTER ADVANCING 2 LINES 意思是“在前进两行之后打印T记录内容” (ADVANCING 和 LINE 字可省略) WRITE T BEFORE ADVANCIN ...
- yum和rpm
rpm简介 这是一个数据库管理工具,可以通过读取数据库,判断软件是否已经安装,如果已经安装可以读取出来所有文件的所在位置等,并可以实现删除这些文件. rpm:RPM is Redhat Package ...
- 安装tensorflowGPU版本
ubuntu 16.0# 安装cuda ## 安装sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb.debsudo apt ...
- react_app 项目开发_遇到的坑
1. favicon.ico <link rel="shortcut icon" type="image/x-icon" href="./fav ...
- jsp 自定义标签解决jsp页面中int时间戳的时间格式化问题
jsp 自定义标签解决jsp页面中int时间戳的时间格式化问题 之前在项目中根据需求,需要自定义标签,经过查询w3c文档,自己也踩了一些坑,特此记录自定义标签的步骤,下面就以我之前的一个例子中的定义一 ...
- <c:forEach var="role" items="[entity.Role@d54d4d, entity.Role@1c61868, entity.Role@6c58db, entity.Role@13da8a5]"> list 集合数据转换异常
<c:forEach var="role" items="[entity.Role@d54d4d, entity.Role@1c61868, entity.Role ...
- 嵌入式linux内存越界定位和解决 (转)
https://blog.csdn.net/meejoy/article/details/41729585 https://blog.csdn.net/killmice/article/details ...
- robot 中文 乱码 问题 的处理
第一种方式: def unic(item): if isinstance(item, unicode): return item if isinstance(item, (bytes, ...