python爬取安居客二手房网站数据(转)
之前没课的时候写过安居客的爬虫,但那也是小打小闹,那这次呢,
还是小打小闹
哈哈,现在开始正式进行爬虫书写
首先,需要分析一下要爬取的网站的结构:
作为一名河南的学生,那就看看郑州的二手房信息吧!
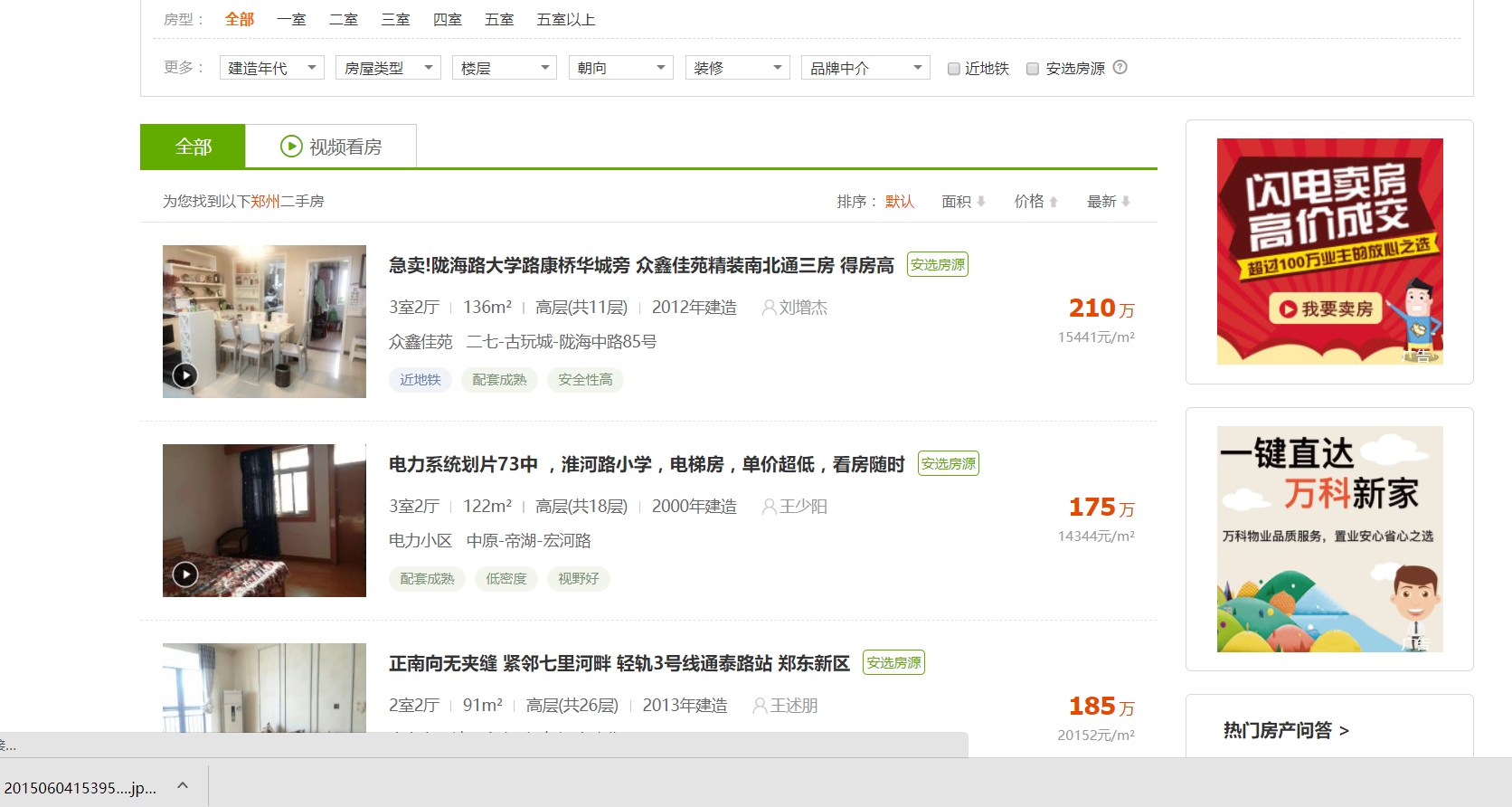
在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起
还是正文吧!!!
由上可以看到网页一条条的房源信息,点击进去后就会发现:

房源的详细信息。
OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说了
好,正式开始,首先我采用python3.6 中的requests,BeautifulSoup模块来进行爬取页面,
首先由requests模块进行请求:

# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)
执行后就会得到这个网站的html代码了


通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)
通过打印就能进一步减少了code量,好,继续提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])
这样,我们就能看到一个个的url了,是不是很喜欢
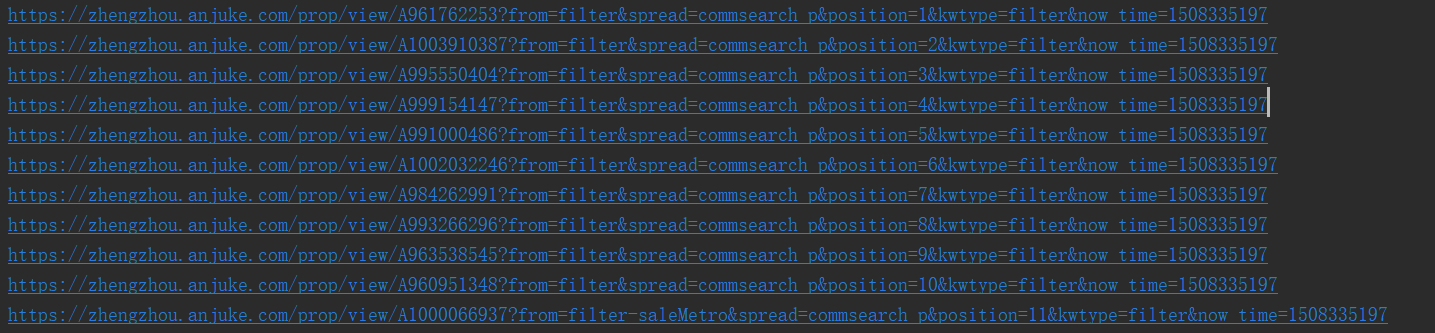
好了,按正常的逻辑就要进入页面开始分析详细页面了,但是爬取完后如何进行下一页的爬取呢
所以,我们就需要先分析该页面是否有下一页
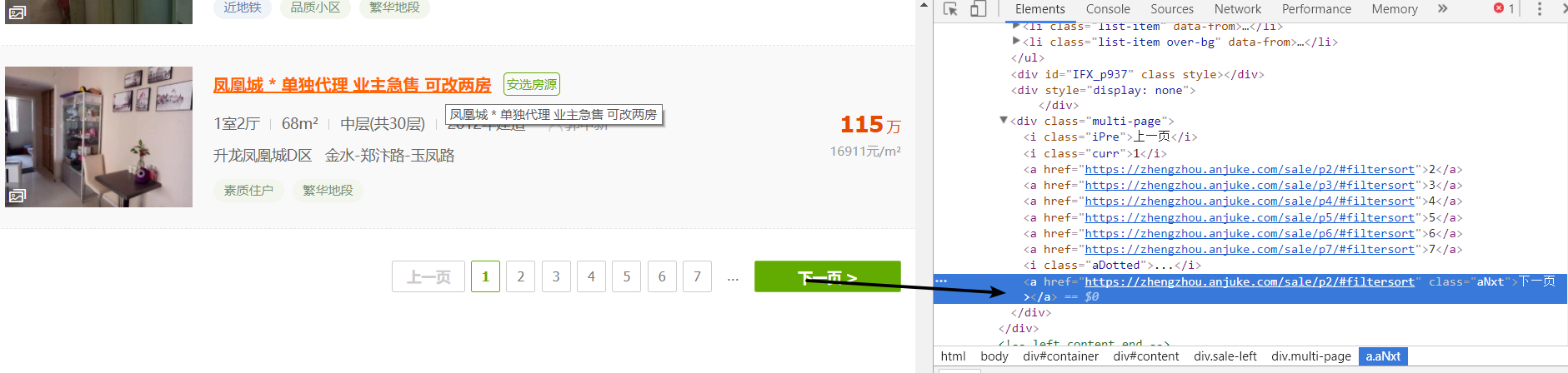
同样的方法就可以发现下一页同样是如此的简单,那么咱们就可以还是按原来的配方原来的味道继续
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
因为当存在下一页的时候,网页中就是一个a标签,如果没有的话,就会成为i标签了,所以这样的就行,因此,我们就能完善一下,将以上这些封装为一个函数
import requests
from bs4 import BeautifulSoup # 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
} def get_page(url):
response = requests.get(url, headers=header) # 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'}) # 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了') # 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href']) if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)
好了,那么咱们就开始详细页面的爬取了
哎,怎么动不动就要断电了,大学的坑啊,先把结果附上,闲了在补充,
import requests
from bs4 import BeautifulSoup # 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
} def get_page(url):
response = requests.get(url, headers=header) # 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'}) # 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href']) # 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了') # 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser') # 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('div', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('div', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('div', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text)) if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)
由于自己边写博客,边写的代码,所以get_page函数中进行了一些改变,就是下一页的递归调用需要放在函数后面,以及进行封装了两个函数没有介绍,
而且数据存储到mysql也没有写,所以后期会继续跟进的,thank you!!!
https://www.cnblogs.com/gkf0103/p/7689600.html
python爬取安居客二手房网站数据(转)的更多相关文章
- python3 爬虫之爬取安居客二手房资讯(第一版)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author;Tsukasa import requests from bs4 import Beau ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- Python爬取房天下二手房信息
一.相关知识 BeautifulSoup4使用 python将信息写入csv import csv with open("11.csv","w") as csv ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- 【scrapy实践】_爬取安居客_广州_新楼盘数据
需求:爬取[安居客—广州—新楼盘]的数据,具体到每个楼盘的详情页的若干字段. 难点:楼盘类型各式各样:住宅 别墅 商住 商铺 写字楼,不同楼盘字段的名称不一样.然后同一种类型,比如住宅,又分为不同的情 ...
- python爬虫爬取安居客并进行简单数据分析
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 爬取过程一.指定爬取数据二.设置请求头防止反爬三.分析页面并且与网页源码进行比对四.分析页面整理数据 ...
- PyCharm+Scrapy爬取安居客楼盘信息
一.说明 1.1 开发环境说明 开发环境--PyCharm 爬虫框架--Scrapy 开发语言--Python 3.6 安装第三方库--Scrapy.pymysql.matplotlib 数据库--M ...
随机推荐
- Codeforces 1108E2 Array and Segments (Hard version)(差分+思维)
题目链接:Array and Segments (Hard version) 题意:给定一个长度为n的序列,m个区间,从m个区间内选择一些区间内的数都减一,使得整个序列的最大值减最小值最大. 题解:利 ...
- POJ2975 Nim 【博弈论】
DescriptionNim is a 2-player game featuring several piles of stones. Players alternate turns, and on ...
- Multi-View 3D Reconstruction with Geometry and Shading——Part-2
From PhDTheses Multi-View 3D Reconstruction with Geometry and Shading 我们的主要目标是只利用图像中的信息而没有额外的限制或假设来得 ...
- SQL学习指南第四篇
SQL必知必会(第4版)学习笔记 插入数据 插入有几种方式: 插入完整的行 插入行的一部分 插入某些查询的结果(INSERT SELECT) 注意:省略列 如果表的定义允许,则可以在 INSERT 操 ...
- python+appium模拟手机物理按键操作
一句代码:driver.keyevent() 括号里填入的是手机物理按键的数字代号 driver.press_keycode() 括号里填入的是键盘按键的数字代号 手机物理 ...
- 3754. 【NOI2014】魔法森林(LCT)
Problem 给定一个\(n\)个结点,\(m\)条边的的无向图,每条边有两个权值\(ai,bi\). 现在从\(1\)出发,要到达\(n\),每次只能沿着\(ai\le A\)且\(bi\le B ...
- NFV-Based Scalable Guaranteed-Bandwidth Multicast Service for Software Defined ISP Networks
文章名称:NFV-Based Scalable Guaranteed-Bandwidth Multicast Service for Software Defined ISP Networks 发表时 ...
- Docker 基本核心原理
Docker内核知识 namespace资源隔离 namespace的6项隔离 NameSpace 系统调用参数 隔离内容 UTS CLONE_NEWUTS 主机名与域名 IPC CLONE_NEWI ...
- C语言 变量的作用域和生命周期(转)
转自 https://blog.csdn.net/u011616739/article/details/62052179 a.普通局部变量 属于某个{},在{}外部不能使用此变量,在{}内部是可以使用 ...
- Mac 上 Apache Apollo 的安装与运行,和官方下载文件中 Python 实例的演示
前不久我在 Mac 上成功安装了 mosquitto,这次我又试了试安装另一个热门的 broker —— Apache Apollo.对在 Mac 上安装 mosquitto 感兴趣的可以点击查看我的 ...