大数据学习之路------借助HDP SANDBOX开始学习
一开始...
一开始知道大数据这个概念的时候,只是感觉很高大上,引起了我的兴趣。当时也不知道,这个东西是做什么的,有什么用,当然现在看来也是很模糊的样子,但是的确比一开始强了不少。
所以学习的过程可能会很艰辛甚至有时候会很缓慢,但是感觉这东西未来会很有用途,最初了解大数据是从《大数据时代》这本书开始的,里面的很多概念和预测让我觉得很神奇。
但是渐渐生活中的一些事物被印证,我渐渐接受了这本书的内容,我觉得这本书还是值得一看的。
在国内这个技术似乎是比较新颖的,做的人似乎不是很多,正因为如此,资料也会匮乏,学习难度也上升了,但是这不是我们放弃的理由不是么?
借助平台管理工具
废话少说,多学些东西才是正经事,在公司实习过一段时间了,感觉初学的困难之一就是,搭建平台。
所以我们可以了解一下一些比较流行的平台管理工具:
HDP、CDH
而我在公司使用的便是HDP,所以我就大概的说一下HDP好了
HDP
HDP是什么?
HDP全称叫做Hortonworks Data Platform。
Hortonworks数据平台是一款基于Apache Hadoop的是开源数据平台,提供大数据云存储,大数据处理和分析等服务。该平台是专门用来应对多来源和多格式的数据,并使其处理起来能变成简单、更有成本效益。HDP还提供了一个开放,稳定和高度可扩展的平台,使得更容易地集成Apache Hadoop的数据流业务与现有的数据架构。该平台包括各种的Apache Hadoop项目以及Hadoop分布式文件系统(HDFS)、MapReduce、Pig、Hive、HBase、Zookeeper和其他各种组件,使Hadoop的平台更易于管理,更加具有开放性以及可扩展性。
官网地址为:http://zh.hortonworks.com/
HDP的架构
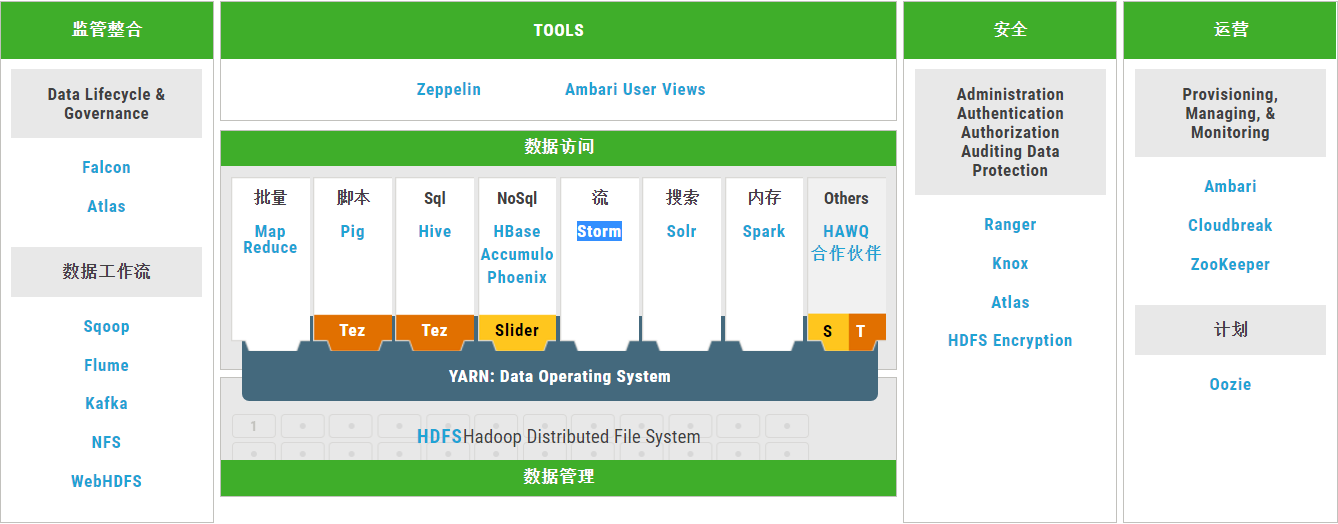
学习路线:
由上图看出
大概分为这么几类工具:
数据管理:
HDFS、YARN
数据访问:
Hive、Tez、Pig、Storm、Spark、HBase、Accumulo、Solr
数据管制和集成:
Atlas、Falcon、Oozie、Sqoop、Flume、Kafka
安全性:
Knox、Ranger
运营:
Ambari Zookeeper
Cloud:
Cloudbreak
既然没有什么具体的路线那么就是一个类一个类的来学习好了。
Hortonworks Sandbox的安装与使用:
官网上解释:Hortonworks Sandbox,可以使用它尝试一下最新的hdp特性和功能。
它可以装在一个VM上,如此来说,给我们学习大数据相关内容提供了极大的便利
下载地址:http://zh.hortonworks.com/downloads/#sandbox
安装的方法很简单,使用相应的虚拟机软件,直接导入就OK了。
注意:我的笔记本电脑是12g内存的,而HDP2.5所需要的最小内存是8G,而如果你的内存不够,可以选择低版本的SANDBOX。
安装后,开启虚拟机就可以了
启动的过程可能会很久要耐心等待。
启动如下图所示:
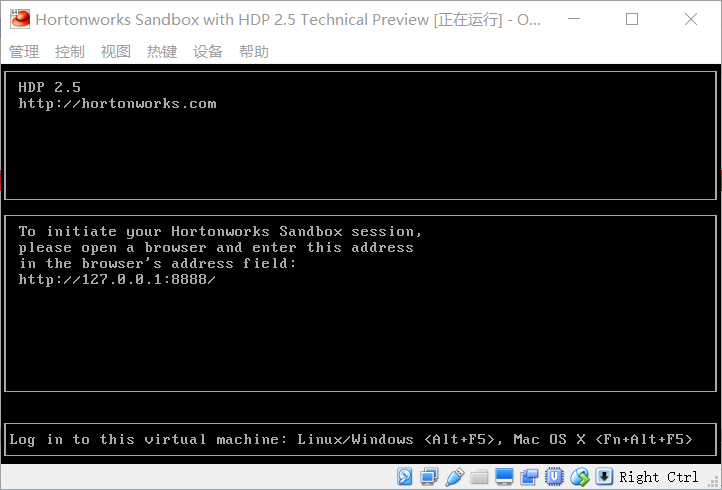
打开浏览器,输入http://127.0.0.1:8888/即可。
进入后可以点开 view advanced options来查看更多的信息。
右下角有如下内容:
* Service disabled by default. To enable the service you need to log in as an ambari admin.
The ambari admin password can be set by following this tutorial
这里需要我们进行ssh登录后,添加admin账户的密码,并使用这个admin账户来登录虚拟机。
ssh工具登录使用地址127.0.0.1 端口为 2222
这里也可以使用浏览器进行登录:
在浏览器里输入127.0.0.1:4200,访问即可
用户名:root
密码: hadoop
登录后需要修改密码,这里的密码设置复杂一些,简单密码有可能通不过(不过经过本人测试,当你以后再次登录后,可以运行passwd root,修改成任意你想要的密码)
然后运行ambari-admin-password-reset命令,修改ambari的admin账户密码。
修改后,我们在浏览器里输入172.0.0.1:8080,并用admin账户登录。
截张图,


关于ambari的介绍如下:
以后我们就用它来学习了!
大数据学习之路------借助HDP SANDBOX开始学习的更多相关文章
- Data - 大数据分析学习之路
一.大数据分析的五个基本方面 可视化分析 大数据分析的使用者有大数据分析专家,同时还有普通用户,但是他们二者对于大数据分析最基本的要求就是可视化分析,因为可视化分析能够直观的呈现大数据特点,同时能够非 ...
- 月薪30-50K的大数据工程师们,他们背后是如何学习的
这两天小编去了解了下大数据开发相关职位的薪资,主要有hadoop工程师,数据挖掘工程师.大数据算法工程师等,从平均薪资来看,目前大数据相关岗位的月薪均在2万以上,随着项目经验的增长工资会越来越高. ...
- 搜狗大数据总监、Polarr 联合创始人关于深度学习的分享交流 | 架构师小组交流会
架构师小组交流会是由国内知名公司技术专家参与的技术交流会,每期选择一个时下最热门的技术话题进行实践经验分享.第一期:来自沪江.滴滴.蘑菇街.扇贝架构师的 Docker 实践分享 第二期:来自滴滴.微博 ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- Python大神成长之路: 第三次学习记录 集合 函数 装饰 re
学习记录day03 字符串可以直接切片,But字符串不可修改 字符串修改:生成了一个新的字符串 LIst修改,在原基础上修改(原内存上) 集合是一个无序的,不重复的数据组合,它的主要作用如 ...
- 大数据平台比较-CDH,HDP
主要的不同点 apache Ambari ClouderaManager Express(免费版) 配置版本控制和历史记录 支持 不支持 二次开发 支持 不支持 集成 支持 no (不支持redis. ...
- 大数据新手之路四:联合使用Flume和Kafka
Ubuntu16.04+Kafka1.0.0+Flume1.8.0 1.目标 ①使用Flume作为Kafka的Producer: ②使用Kafka作为Flume的Sink: 其实以上两点是同一个事情在 ...
- 大数据新手之路二:安装Flume
Ubuntu16.04+Flume1.8.0 1.下载apache-flume-1.8.0-bin.tar.gz http://flume.apache.org/download.html 2.解压到 ...
- 大数据新手之路一:安装JDK
Ubuntu16.04 1.下载jdk-8u192-linux-x64.tar.gz https://www.oracle.com/technetwork/java/javase/downloads/ ...
随机推荐
- Interrupt中断线程
package com.wistron.swpc.ecs.util; public class WrongWayStopThread extends Thread{ public static voi ...
- 【Hexo】本地local4000打不开解决方法
错误:Cannot GET /spadesq.github.io/ (注:spadesq.github.io是原来放hexo文件夹的名字) 由于我后来把hexo文件夹搬迁到别处,但我发现打开本地,地址 ...
- react基础篇三
事件处理 React事件绑定属性的命名采用驼峰式写法,而不是小写. 如果采用 JSX 的语法你需要传入一个函数作为事件处理函数,而不是一个字符串(DOM元素的写法) 例如,传统的 HTML: < ...
- vue-router同路由地址切换无效解决
本来还想写的,一搜就有现成的,算了: http://blog.csdn.net/peng_guan/article/details/59702699
- webstorm for mac
mac上使用webstrom,破解的方法 参见博客:Webstorm 破解2016.1 for mac 上面的说明有点问题,博主的写的有点问题.应该是1.先打开到注册页面:2.再关闭webstrom; ...
- Android 性能测试初探(一)
Android 性能测试,跟 pc 性能测试一样分为客户端及服务器,但在客户端上的性能测试分为 2 类: 一类为 rom 版本的性能测试 一类为应用的性能测试 对于应用性能测试,包括很多测试项,如启动 ...
- js声明变量作用域会提前
var s = 1; function test() { console.info(s); var s = 2; console.info(s); } test(); >>>unde ...
- DOM学习之图片库切换效果
addloadevent(prepareplaceholder()) addloadevent(prepareGallery()) //页面加载完时执行函数 function addloadevent ...
- 字符串函数(day11)
使用存储区的地址作为返回值可以让调用 函数使用被调用函数的存储区 这种时候被调用函数需要提供一个指针类型 的存储区记录作为返回值的地址数据 不可以把非静态局部变量的地址作为返回值 使用 C语言里的文字 ...
- case...when...then if 用法
select case when if 的一些用法 概述:sql语句中的case语句与高级语言中的switch语句,是标准sql的语法,适用于一个条件判断有多种值的情况下分别执行不同的操作. 首先,让 ...