java+spark-sql查询excel
Spark官网下载Spark
Spark下载,版本随意,下载后解压放入bigdata下(目录可以更改)
下载Windows下Hadoop所需文件winutils.exe
同学们自己网上找找吧,这里就不上传了,其实该文件可有可无,报错也不影响Spark运行,强迫症可以下载,本人就有强迫症~~,文件下载后放入bigdata\hadoop\bin目录下。
不用创建环境变量,再Java最开始处定义系统变量即可,如下:
System.setProperty("hadoop.home.dir", HADOOP_HOME);
创建Java Maven项目java-spark-sql-excel
建立相关目录层次如下:
父级目录(项目所在目录)
- java-spark-sql-excel
- bigdata
- spark
- hadoop
- bin
- winutils.exe
编码
初始化SparkSession
static{
System.setProperty("hadoop.home.dir", HADOOP_HOME);
spark = SparkSession.builder()
.appName("test")
.master("local[*]")
.config("spark.sql.warehouse.dir",SPARK_HOME)
.config("spark.sql.parquet.binaryAsString", "true")
.getOrCreate();
}
读取excel
public static void readExcel(String filePath,String tableName) throws IOException{
DecimalFormat format = new DecimalFormat();
format.applyPattern("#");
//创建文件(可以接收上传的文件,springmvc使用CommonsMultipartFile,jersey可以使用org.glassfish.jersey.media.multipart.FormDataParam(参照本人文件上传博客))
File file = new File(filePath);
//创建文件流
InputStream inputStream = new FileInputStream(file);
//创建流的缓冲区
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
//定义Excel workbook引用
Workbook workbook =null;
//.xlsx格式的文件使用XSSFWorkbook子类,xls格式的文件使用HSSFWorkbook
if(file.getName().contains("xlsx")) workbook = new XSSFWorkbook(bufferedInputStream);
if(file.getName().contains("xls")&&!file.getName().contains("xlsx")) workbook = new HSSFWorkbook(bufferedInputStream);
System.out.println(file.getName());
//获取Sheets迭代器
Iterator<Sheet> dataTypeSheets= workbook.sheetIterator();
while(dataTypeSheets.hasNext()){
//每一个sheet都是一个表,为每个sheet
ArrayList<String> schemaList = new ArrayList<String>();
// dataList数据集
ArrayList<org.apache.spark.sql.Row> dataList = new ArrayList<org.apache.spark.sql.Row>();
//字段
List<StructField> fields = new ArrayList<>();
//获取当前sheet
Sheet dataTypeSheet = dataTypeSheets.next();
//获取第一行作为字段
Iterator<Row> iterator = dataTypeSheet.iterator();
//没有下一个sheet跳过
if(!iterator.hasNext()) continue;
//获取第一行用于建立表结构
Iterator<Cell> firstRowCellIterator = iterator.next().iterator();
while(firstRowCellIterator.hasNext()){
//获取第一行每一列作为字段
Cell currentCell = firstRowCellIterator.next();
//字符串
if(currentCell.getCellTypeEnum() == CellType.STRING) schemaList.add(currentCell.getStringCellValue().trim());
//数值
if(currentCell.getCellTypeEnum() == CellType.NUMERIC) schemaList.add((currentCell.getNumericCellValue()+"").trim());
}
//创建StructField(spark中的字段对象,需要提供字段名,字段类型,第三个参数true表示列可以为空)并填充List<StructField>
for (String fieldName : schemaList) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
//根据List<StructField>创建spark表结构org.apache.spark.sql.types.StructType
StructType schema = DataTypes.createStructType(fields);
//字段数len
int len = schemaList.size();
//获取当前sheet数据行数
int rowEnd = dataTypeSheet.getLastRowNum();
//遍历当前sheet所有行
for (int rowNum = 1; rowNum <= rowEnd; rowNum++) {
//一行数据做成一个List
ArrayList<String> rowDataList = new ArrayList<String>();
//获取一行数据
Row r = dataTypeSheet.getRow(rowNum);
if(r!=null){
//根据字段数遍历当前行的单元格
for (int cn = 0; cn < len; cn++) {
Cell c = r.getCell(cn, Row.MissingCellPolicy.RETURN_BLANK_AS_NULL);
if (c == null) rowDataList.add("0");//空值简单补零
if (c != null&&c.getCellTypeEnum() == CellType.STRING) rowDataList.add(c.getStringCellValue().trim());//字符串
if (c != null&&c.getCellTypeEnum() == CellType.NUMERIC){
double value = c.getNumericCellValue();
if (p.matcher(value+"").matches()) rowDataList.add(format.format(value));//不保留小数点
if (!p.matcher(value+"").matches()) rowDataList.add(value+"");//保留小数点
}
}
}
//dataList数据集添加一行
dataList.add(RowFactory.create(rowDataList.toArray()));
}
//根据数据和表结构创建临时表
spark.createDataFrame(dataList, schema).createOrReplaceTempView(tableName+dataTypeSheet.getSheetName());
}
}
在项目目录下创建测试文件

第一个Sheet:
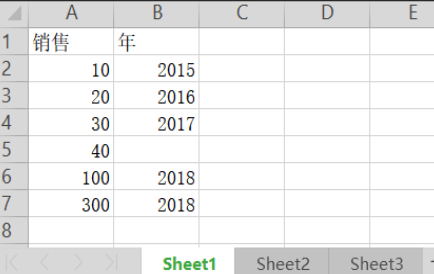
第二个Sheet:

第三个Sheet:
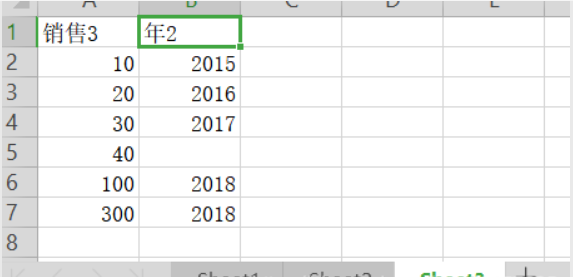
测试
public static void main(String[] args) throws Exception {
//需要查询的excel路径
String xlsxPath = "test2.xlsx";
String xlsPath = "test.xls";
//定义表名
String tableName1="test_table1";
String tableName2="test_table2";
//读取excel表名为tableNameN+Sheet的名称
readExcel(xlsxPath,tableName2);
spark.sql("select * from "+tableName2+"Sheet1").show();
readExcel(xlsPath,tableName1);
spark.sql("select * from "+tableName1+"Sheet1").show();
spark.sql("select * from "+tableName1+"Sheet2").show();
spark.sql("select * from "+tableName1+"Sheet3").show();
}
运行结果
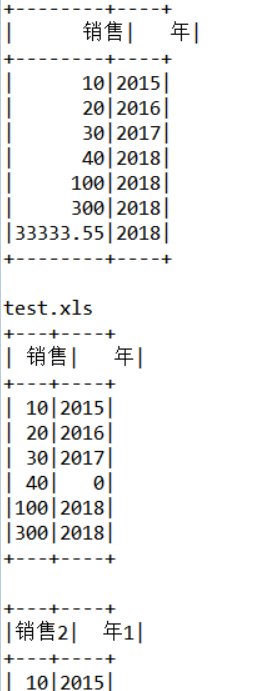
相关依赖
<dependencies>
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
</dependencies>
java+spark-sql查询excel的更多相关文章
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 64位环境中使用SQL查询excel的方式解决
--64位环境中使用SQL查询excel的方式 环境: OS:Windows Server 2008 R2 Enterprise MSSQL:Microsoft SQL Server 2008 R2 ...
- Java 获取SQL查询语句结果
step1:构造连接Class.forName("com.mysql.jdbc.Driver"); Connection con = DriverManager.getConnec ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- 2. 执行Spark SQL查询
2.1 命令行查询流程 打开Spark shell 例子:查询大于21岁的用户 创建如下JSON文件,注意JSON的格式: {"name":"Michael"} ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- 从SQL查询分析器中读取EXCEL中的内容
很早以前就用sql查询分析器来操作过EXCEL文件了. 由于对于excel公式并不是很了解,所以很多时候处理excel中的内容,常常是用sql语句来处理的.[什么样的人有什么样的办法吧 :)] 今又要 ...
- Spark SQL基本概念与基本用法
1. Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为 ...
- spark第七篇:Spark SQL, DataFrame and Dataset Guide
预览 Spark SQL是用来处理结构化数据的Spark模块.有几种与Spark SQL进行交互的方式,包括SQL和Dataset API. 本指南中的所有例子都可以在spark-shell,pysp ...
- 理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的.使用这个函数执行SQL语句前需要 ...
随机推荐
- GoldenGate 日常监控
正确启动数据库 源端启动数据库 SQL> startup 源端启动goldengate GGSCI > start mgr GGSCI > start * 目标端启动数据库 S ...
- objc_clear_deallocating 与弱引用
void *objc_destructInstance(id obj){ if (obj) { Class isa_gen = _object_getClass(obj); class_t *isa ...
- POJ2976 Dropping tests(01分数规划)
题意 给你n次测试的得分情况b[i]代表第i次测试的总分,a[i]代表实际得分. 你可以取消k次测试,得剩下的测试中的分数为 问分数的最大值为多少. 题解 裸的01规划. 然后ans没有清0坑我半天. ...
- 洛谷P1108 低价购买 (最长下降子序列方案数)(int,long long等 范围)
这道题用n方的算法会很好做 我一开始想的是nlogn的算法求方案数, 然后没有什么想法(实际上也可以做,但是我太弱了)我们就可以根据转移方程来推方案数,只是把max改成加,很多动规题 都是这样,比如背 ...
- hihoCoder #1127 : 二分图二·二分图最小点覆盖和最大独立集
#1127 : 二分图二·二分图最小点覆盖和最大独立集 Time Limit:10000ms Case Time Limit:1000ms Memory Limit:256MB 描述 在上次安排完相亲 ...
- LocalDateTime与mysql日期类型的交互(基于mybatis)
众所周知,在实体Entity里面,可以使用Java.sql.Date.java.sql.Timestamp.java.util.Date来映射到数据库的date.timestamp.datetime等 ...
- zend framework获取数据库中枚举类enum的数据并将其转换成数组
在model中建立这种模型,在当中写入获取枚举类的方法 请勿盗版,转载请加上出处http://blog.csdn.net/yanlintao1 class Student extends Zend_D ...
- modSecurity规则学习(七)——防止SQL注入
1.数字型SQL注入 /opt/waf/owasp-modsecurity-crs/rules/REQUEST-942-APPLICATION-ATTACK-SQLI.conf"] [lin ...
- spring 中国下载点
http://repo.spring.io/libs-release-local/org/springframework/spring/ spring 中国下载点
- 微信公众号开发(二)获取AccessToken、jsapi_ticket
Access Token 在微信公众平台接口开发中,Access Token占据了一个很重要的地位,相当于进入各种接口的钥匙,拿到这个钥匙才有调用其他各种特殊接口的权限. access_token是公 ...