selenium常用操作,查找元素,操作Cookie,获取截图,获取窗口信息,切换,执行js代码
目录:
简介
selenium.webdriver.remote.webdriver.WebDriver 这个类其实是所有其他Webdriver的父类,
例如Chrome Webdriver,Firefox Webdriver都是继承自这个类。这个类中实现了每个Webdriver间相通的方法。
常用操作
- get(url)
在当前浏览器会话中访问传入的url地址
driver.get("https://www.baidu.com")
- close()
关闭浏览器当前页面(只有当前的一个页面会被关闭)
driver.close()
- quit()
退出webdriver并关闭所有窗口(推荐,这样退出不会浪费内存)
- refresh()
刷新当前页面
- title【注意没有括号】
获取当前页面的标题(就是浏览器页面上方的窗口标题)
- page_source
获取当前页面渲染之后的源代码
- current_url
获取当前页面的url
- window_handles
获取当前会话中所有窗口的句柄(句柄就是一个页面的标志,页面切换的参数)
查找元素
Webdriver对象中内置了查找节点元素的方法,使用非常方便。
单个查找
以下是查找单个元素的方法:
| 方法 | 作用 |
|---|---|
find_element_by_xpath() |
通过Xpath查找 |
find_element_by_class_name() |
通过class属性查找 |
find_element_by_css_selector() |
通过css选择器查找 |
find_element_by_id() |
通过id查找 |
find_element_by_link_text() |
通过链接文本查找 |
find_element_by_name() |
通过name属性进行查找 |
find_element_by_partial_link_text() |
通过链接文本的部分匹配查找 |
find_element_by_tag_name() |
通过标签名查找 |
查找后返回的是一个Webelement对象。
查找到了对象,就相当于浏览器的鼠标已经放在了对象上面,想要对其操作,
就需要用一个变量存放该对象,再进行需要的操作
多个查找
上面的方法都是将第一个找到的元素返回,而将所有匹配的元素进行返回使用的是
find_elements_by_* 方法。
注意:将其中的elelment加上一个s,就是对应的多个查找的方法。
此方法返回的是一个Webelement对象组成的列表。

通过私有方法进行查找
除了以上的多种查找方式,还有两种私有方法find_element()和find_elements()可以使用:
例子:
需要导入新的方法:from selenium.webdriver.common.by import By
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
By这个类是专门用来查找元素时传入的参数,这个类中有以下属性:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
使用了WebDriverWait以后仍然无法找到元素
有很多时候,一个简单的元素,明明也加了显式等待,但就是找不到,代码在仔细查看过后也没有问题后,多半是以下这几种情况:
由于分辨率设置的原因,查找的元素当前是不可见的。
某些页面的元素是需要向下滚动页面才会加载的。
由于某些其他元素的短暂遮挡,所以无法定位到。
1.分辨率原因
这时候应该设置好分辨率,使当前元素能够显示到页面中。
2.需要滚动页面
有些页面为了性能的考虑,页面下方不在当前屏幕中的元素是不会加载的,只有当页面向下滚动时才会继续加载。
而selenium本身不提供向下滚动的方法,所以我们需要去用JS去滚动页面:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
网上查到的一些滚动方式在Chrome上无效。但这一句是有效的。
滚动的位置:
网页可见区域宽: document.body.clientWidth;
网页可见区域高: document.body.clientHeight;
网页可见区域宽: document.body.offsetWidth (包括边线的宽);
网页可见区域高: document.body.offsetHeight (包括边线的宽);
网页正文全文宽: document.body.scrollWidth;
网页正文全文高: document.body.scrollHeight;
网页被卷去的高: document.body.scrollTop;
网页被卷去的左: document.body.scrollLeft;
网页正文部分上: window.screenTop;
网页正文部分左: window.screenLeft;
屏幕分辨率的高: window.screen.height;
屏幕分辨率的宽: window.screen.width;
屏幕可用工作区高度: window.screen.availHeight;
屏幕可用工作区宽度:window.screen.availWidth;
3.由于其他元素的遮挡
有时候因为一些弹出元素的原因,如果还使用EC.presence_of_element_located()的话,
我们需要定位的元素就无法被找到,这个时候我们就应该改变我们判断元素的方法:
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, ''))
)
使用EC.visibility_of_element_located()方法可以在等待到当前元素可见后,才获取元素。
在我们找不到元素,或者跟元
素无法交互时,应该多去根据当前的情况,灵活选择显式等待的判断方式。
操作Cookie
add_cookie(cookie_dict)给当前会话添加一个cookie。
cookie_dict: 一个字典对象,必须要有"name"和"value"两个键,
可选的键有:“path”, “domain”, “secure”, “expiry” 。
用法:
driver.add_cookie({‘name’ : ‘foo’, ‘value’ : ‘bar’})
driver.add_cookie({‘name’ : ‘foo’, ‘value’ : ‘bar’, ‘path’ : ‘/’})
driver.add_cookie({‘name’ : ‘foo’, ‘value’ : ‘bar’, ‘path’ : ‘/’, ‘secure’:True})
get_cookie(name)按name获取单个Cookie,没有则返回None。
get_cookies()获取所有Cookie,返回的是一组字典。
delete_all_cookies()删除所有Cookies。
delete_cookie(name)按name删除指定cookie。
获取截屏
get_screenshot_as_base64()获取当前窗口的截图保存为一个base64编码的字符串。
get_screenshot_as_file(filename)获取当前窗口的截图保存为一个png格式的图片,filename参数为图片的保存地址,最后应该以.png结尾。如果出现IO错误,则返回False。
用法:
driver.get_screenshot_as_file(‘/Screenshots/foo.png’)
get_screenshot_as_png()获取当前窗口的截图保存为一个png格式的二进制字符串。
获取窗口信息
get_window_position(windowHandle='current')获取当前窗口的x,y坐标。(字典格式)
get_window_size(windowHandle='current')
获取当前窗口的高度和宽度。(字典格式)
get_window_rect()获取当前窗口的高度和宽度和当前窗口的x,y坐标。(字典格式)
切换
在实际的爬虫中,有时候我们会遇到找不到元素的问题,明明定位的路径没问题,
这个时候我们可以考虑一下是否是该页面存在frame的问题导致的定位不到元素。
switch_to_frame(frame_reference)将焦点切换到指定的子框架中
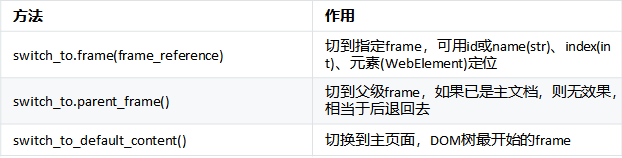
用selenium操作浏览器如果需要在打开新的页面,这个时候会有问题,
因为我们用selenium操作的是第一个打开的窗口,所以新打开的页面我们是无法去操作的,
所以我们要用到切换窗口:既handle切换的方法
switch_to.window(window_name)切换窗口(参数就是句柄)
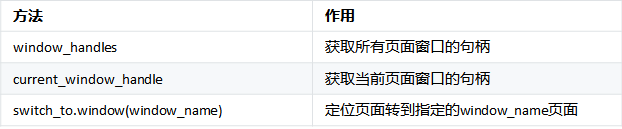
有的时候还会遇到弹窗的问题, 主要有两种一种是浏览器弹窗(alert/prompt),
一种是自定义弹窗
自定义弹窗,就是一个自定义的div层,是隐藏页面中的,当触发了这个弹窗后,他就显示出来,
这种方式我们通过正常的定位方式是可以定位到的。
alert弹窗,就要用下面的方法处理:
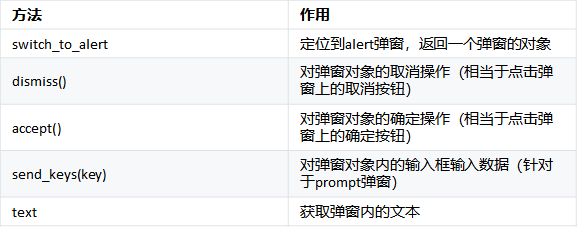
执行JS代码
execute_async_script(script, *args)
在当前的window/frame中异步执行JS代码。
script:是你要执行的JS代码。
*args:是你的JS代码执行要传入的参数。
selenium常用操作,查找元素,操作Cookie,获取截图,获取窗口信息,切换,执行js代码的更多相关文章
- selenium 执行js代码
获取一个input输入框的值: JavascriptExecutor js =(JavascriptExecutor) driver; merchatName=js.executeScript(&qu ...
- Android获取cpu和内存信息、网址的代码
android获取手机cpu并判断是单核还是多核 /** * Gets the number of cores available in this device, across all proce ...
- <自动化测试>之<selenium API 查找元素操作底层方法>
搜罗了一些查找元素的除标准语句外,另外的语句使用方法,摘自 开源中国 郝云鹏driver = webdriver.Chrome(); 打开测试页面 driver.get( "http://b ...
- C++ 关联容器之map插入相同键元素与查找元素操作
一.插入相同键元素操作 (1)insert方法 在map中的键必须是唯一的,当想map中连续插入键相同但值不同的元素时,编译和运行时都不会发生任何错误,系统会忽略后面的对已存在的键的插入操作,如 ma ...
- Selenium 常用定位对象元素的方法
常见定位对象元素的方法 在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方 ...
- python实例编写(1)--浏览器操作,元素操作
一.浏览器操作 1. back()与 forward() #coding=gbk //编码不一定是utf-8 from selenium import webdriver //导入包,也叫”模组“ ...
- 利用ajax获取到的网页源码不能执行js代码
今天觉得我的博客中加载腾讯微博的速度很慢,所以就想改写为js,本来以为直接新建一个页面,把获取函数移到新的页面中,原来的页面只要使用xmlhttp去GET一下,然后把div的innerhtml属性等于 ...
- Selenium webdriver Java 查找元素
1.简单查找 By ID: WebElement element=driver.findElement(By.id("userId")); By Name:WebElement e ...
- Selenium常用API的使用java语言之10-获取断言信息
不管是在做功能测试还是自动化测试,最后一步需要拿实际结果与预期进行比较.这个比较的称之为断言. 我们通常可以通过获取title .URL和text等信息进行断言.text方法在前面已经讲过,它用于获取 ...
随机推荐
- Linux ALSA声卡驱动之四:Control设备的创建
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢! Control接口 Control接口主要让用户空间的应用程序(alsa-lib)可以访问 ...
- Android TP(三)【转】
本文转载自:http://blog.csdn.net/bi511304183/article/details/9303259 平台信息:内核:linux2.6/linux3.0系统:android/a ...
- Ubuntu环境下安装nodejs和npm
1.安装python-software-properties sudo apt-get install python-software-properties 2.添加ppa curl -sL http ...
- TeeChart绘图控件 - 之三 - 提高绘图的效率 .
TeeChart是个很强大的控件,其绘图能力之强,其他控件难以比拟,但是有个问题就是他的绘图速度,其实TeeChart绘图速度还是很快的,只是大家一直都没正确运用其功能所以导致绘图速度慢的假象. 下面 ...
- java 提取主域名
import com.google.common.net.InternetDomainName; public static void main(String[] args) { InternetDo ...
- Java - HashTable、HashMap和LinkedHashMap的区别
一般情况下,我们用的最多的是HashMap,在Map 中插入.删除和定位元素,HashMap 是最好的选择.但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好.如果需要输出的顺序和输入的 ...
- poj1200Crazy Search(hash)
题目大意 将一个字符串分成长度为N的字串.且不同的字符不会超过NC个.问总共有多少个不同的子串. /* 字符串hash O(n)枚举起点 然后O(1)查询子串hash值 然后O(n)找不一样的个数 ...
- Android源码下载方法
1. 下载 repo 工具 mkdir ~/bin PATH=~/bin:$PATH curl https://storage.googleapis.com/git-repo-downloads/re ...
- synchronized关键字详解(一)
synchronized官方定义: 同步方法支持一种简单的策略防止线程干扰和内存一致性错误,如果一个对象对多个线程可见,则对该对象变量的所有读取或写入都是通过同步方法完成的(这一个synchroniz ...
- D3.js 力导向图(气泡+线条+箭头+文字)
<!DOCTYPE html> <meta charset="utf-8"> <style> .link { fill: none; strok ...