强化学习(3)-----DQN
看这篇https://blog.csdn.net/qq_16234613/article/details/80268564
1、DQN
原因:在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实。
通常做法是把Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作。如下式,通过更新参数 θ 使Q函数逼近最优Q值 。
Q(s,a;θ)≈Q′(s,a)
而深度神经网络可以自动提取复杂特征,因此,面对高维且连续的状态使用深度神经网络最合适不过了。
DRL是将深度学习(DL)与强化学习(RL)结合,直接从高维原始数据学习控制策略。而DQN是DRL的其中一种算法,它要做的就是将卷积神经网络(CNN)和Q-Learning结合起来,CNN的输入是原始图像数据(作为状态State),输出则是每个动作Action对应的价值评估Value Function(Q值)。
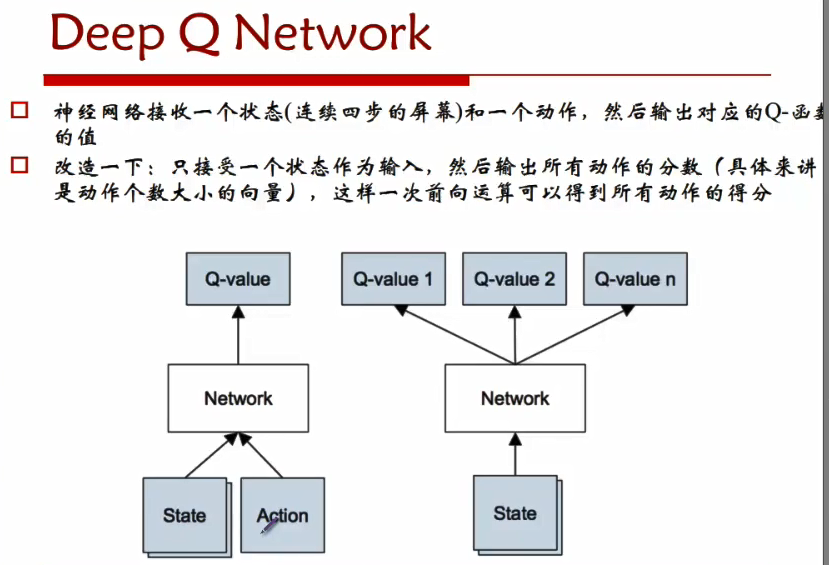
2、模型:

3、算法
2013版

2015版


其实就是反复试验,然后存储数据。接下来数据存到一定程度,就每次随机采用数据,进行梯度下降。 他根据每次更新所参与样本量的不同把更新方法分为增量法(Incremental Methods)和批处理法(Batch Methods)。前者是来一个数据就更新一次,后者是先攒一堆样本,再从中采样一部分拿来更新Q网络,称之为“经验回放”,实际上DeepMind提出的DQN就是采用了经验回放的方法。为什么要采用经验回放的方法?因为对神经网络进行训练时,假设样本是独立同分布的。而通过强化学习采集到的数据之间存在着关联性,利用这些数据进行顺序训练,神经网络当然不稳定。经验回放可以打破数据间的关联。
另外,为了保证算法稳定收敛,还使用了经验回放(experience replay)技术。所谓 t 时刻的经验 e_t ,就是 t 时刻的观测、行为、奖励和 t+1 时刻的观测集合。
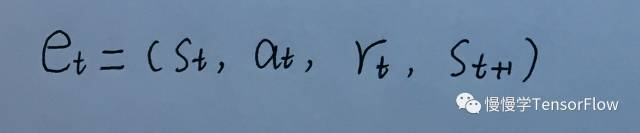
将时刻 1 到 t 所有经验都存储到 Dt 中,称为回放记忆(replay memory)。
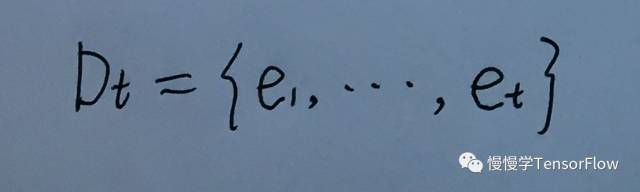
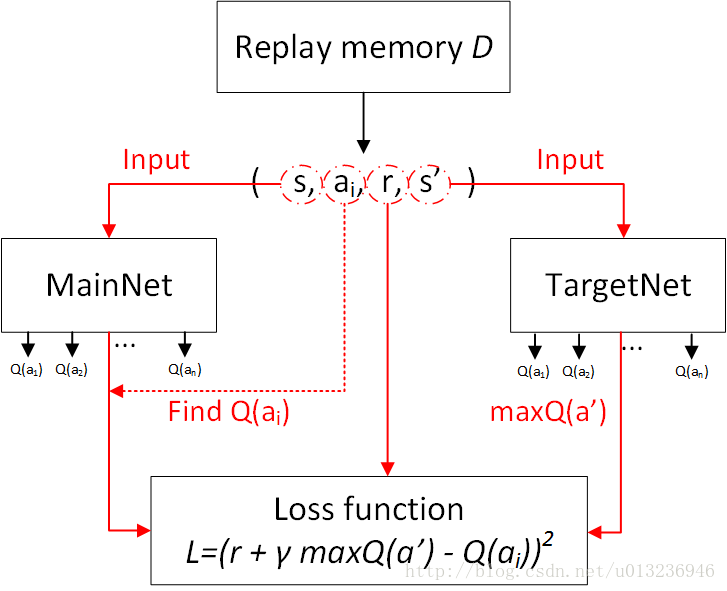
每次迭代,会从 D 中均匀采样得到一组经验,对当前权值使用 SGD 算法进行更新。这样避免了使用相邻经验的过度耦合(游戏中相邻几帧的观测都是非常近似的,容易造成训练发散)。训练 Q 网络时,输入(s, a) 变为序列输入
(s1, a1), (s2, a2), ..., (sn, an)。
主要流程图:

损失函数的构造:
强化学习(3)-----DQN的更多相关文章
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 【强化学习】DQN 算法改进
DQN 算法改进 (一)Dueling DQN Dueling DQN 是一种基于 DQN 的改进算法.主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现.下面给出公式 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 强化学习(十)Double DQN (DDQN)
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性.但是还是有其他 ...
- 强化学习(十一) Prioritized Replay DQN
在强化学习(十)Double DQN (DDQN)中,我们讲到了DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差.今天我 ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
- 强化学习(四)—— DQN系列(DQN, Nature DQN, DDQN, Dueling DQN等)
1 概述 在之前介绍的几种方法,我们对值函数一直有一个很大的限制,那就是它们需要用表格的形式表示.虽说表格形式对于求解有很大的帮助,但它也有自己的缺点.如果问题的状态和行动的空间非常大,使用表格表示难 ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
随机推荐
- 路飞学城Python-Day20(元类的练习题)
练习一:在元类中控制把自定义类的数据属性都变成大写 class MyDef(type): def __new__(cls, class_name, class_attr, class_dic): up ...
- sklearn学习6----交叉验证
1.kfold:自己分样本来交叉验证迭代 导入模块:from sklearn.model_selection import KFold 参数: KFold(n_splits=3, shuffle=Fa ...
- [NOIP补坑计划]NOIP2015 题解&做题心得
感觉从15年开始noip就变难了?(虽然自己都做出来了……) 场上预计得分:100+100+60~100+100+100+100=560~600(省一分数线365) 题解: D1T1 神奇的幻方 题面 ...
- ArchLinux出现ACPI ERROR的解决方法
ArchLinux关机.重启时出现ACPI错误: ACPI Error:Method parse/execution failed \_SB.PCI0.PGON,AE_AML_LOOP_TIMEOUT ...
- ansible 定义主机用户和密码
定义主机组用户和密码 [webservers] ansible[01:04] ansible_ssh_user='root' ansible_ssh_pass='AAbb0101' [root@ftp ...
- 洛谷P5239 回忆京都
和 NOIP2016TG 组合数问题 差不多是一样的-- 首先要知道杨辉三角和组合数之间的关系 看一下数据范围,很明显要避免重复计算,而且查询的复杂度要非常小 一看n, m <= 1000 这明 ...
- C语言使用memcpy函数实现两个数间任意位置的复制操作
c和c++使用的内存拷贝函数,memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中. 用法:void *memcpy(void *dest ...
- tp框架表单提交注意!不要提交到当前方法
tp框架 表单提交到当前方法,会重复执行显示部分和保存部分的代码.导致不知名的错误.
- LeetCode104_MaximumDepthofBinaryTree Java题解
题目: Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the ...
- hdoj-1312-Red and Black
Red and Black Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...