MapReduce的输出格式
1. OutputFormat接口
OutputFormat为输出格式接口,主要用于描述输出数据的格式,它能将输出的键值对写入特定格式的文件中。输出格式的层次结构如下
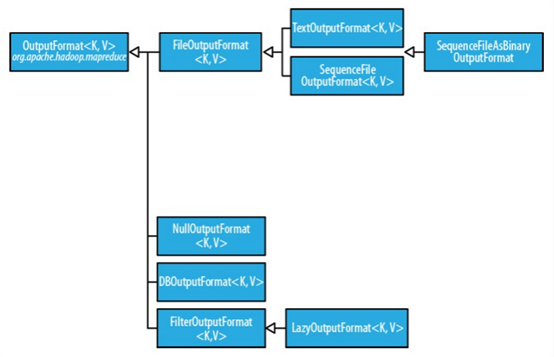
2. 文本输出
Hadoop默认的输出格式为文本输出格式TextOutputFormat,其键和值可以使任意类型的,因为该输出方式会调用toString()方法将它们转化为字符串。每个键/值对由制表符进行分割,当然也可以设定 mapreduce.output.textoutputformat.separator 属性(旧版本 API 中为 mapred.textoutputformat.separator)改变默认的分隔符。
3. 二进制输出
二进制输出有三种方式:SequenceFileOutputFormat,SequenceFileAsBinaryOutputFormat和MapFileOutputFormat。重点掌握第一种。
对于SequenceFileOutputFormat,顾名思义,SequenceFileOutputFormat 将它的输出写为一个顺序文件。如果输出需要作为后续 MapReduce 任务的输入,这便是一种好的输出格式, 因为它的格式紧凑,并且很容易被压缩。而对于SequenceFileAsBinaryOutputFormat,它将键/值对作为二进制格式写到一个 SequenceFile 容器中。不同的是,MapFileOutputFormat 把 MapFile 作为输出。MapFile 中的键必须顺序添加,所以必须确保 reducer 输出的键已经排好序。
4. 多个输出
由于默认情况下只有一个 Reducer,输出只有一个文件。有时可能需要对输出的文件名进行控制或让每个 reducer 输出多个文件。
当只有一个reduce时,输出文件命名格式为:part-r-00000。当有两个reduce时,输出文件命名格式为:part-r-00000,part-r-00001。当有多个时以此类推。实现Reducer输出多个文件主要有以下两种方式:Partitioner和MultipleOutputs。
4.1 Partitioner
我们考虑这样一个需求:按学生的年龄段,将数据输出到不同的文件路径下。这里我们分为三个年龄段:小于等于20岁、大于20岁小于等于50岁和大于50岁。
我们采用的方法是每个年龄段对应一个 reducer。为此,我们需要通过以下两步实现。
第一步:把作业的 reducer 数设为年龄段数即为3。
job.setPartitionerClass(PCPartitioner.class);//设置Partitioner类 job.setNumReduceTasks();// reduce个数设置为3
第二步:写一个 Partitioner,把同一个年龄段的数据放到同一个分区。
public static class PCPartitioner extends Partitioner< Text, Text>
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks) { // TODO Auto-generated method stub
String[] nameAgeScore = value.toString().split("\t");
String age = nameAgeScore[];//学生年龄
int ageInt = Integer.parseInt(age);//按年龄段分区 // 默认指定分区 0 if (numReduceTasks == ) return ;
//年龄小于等于20,指定分区0 if (ageInt <= ) { return ;
}
// 年龄大于20,小于等于50,指定分区1 if (ageInt > && ageInt <= ) { return % numReduceTasks;
}
// 剩余年龄,指定分区2
else return % numReduceTasks;
}
}
这种方法即实现了多文件输出,但也只能满足此种需求。很多情况下是无法实现的,因为这样做存在两个缺点:
1)需要在作业运行之前需要知道分区数和年龄段的个数,如果分区数很大或者未知,就无法操作。
2)一般来说,让应用程序来严格限定分区数并不好,因为这样可能导致分区数少或分区不均。
4.2 MultipleOutputs
MultipleOutputs 类可以将数据写到多个文件,这些文件的名称源于输出的键和值或者任意字符串。这允许每个 reducer(或者只有 map 作业的 mapper)创建多个文件。 采用name-m-nnnnn 形式的文件名用于 map 输出,name-r-nnnnn 形式的文件名用于 reduce 输出,其中 name 是由程序设定的任意名字, nnnnn 是一个指明块号的整数(从 00000 开始)。块号保证从不同块(mapper 或 reducer)写的输出在相同名字情况下不会冲突。
实例将在下一篇博文(MapReduce实战:邮箱统计及多输出格式实现)给出!
5. 数据库输出
DBOutputFormat 适用于将作业输出数据(中等规模的数据)转存到Mysql、Oracle等数据库。如果数据量较大请考虑其他方法将输出数据导入或转存到数据库中。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
MapReduce的输出格式的更多相关文章
- Hadoop MapReduce编程 API入门系列之MapReduce多种输出格式分析(十九)
不多说,直接上代码. 假如这里有一份邮箱数据文件,我们期望统计邮箱出现次数并按照邮箱的类别,将这些邮箱分别输出到不同文件路径下. 代码版本1 package zhouls.bigdata.myMapR ...
- MapReduce实战:邮箱统计及多输出格式实现
紧接着上一篇博文我们学习了MapReduce得到输出格式之后,在这篇博文里,我们将通过一个实战小项目来熟悉一下MultipleOutputs(多输出)格式的用法. 项目需求: 假如这里有一份邮箱数据文 ...
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- Hadoop相关日常操作
1.Hive相关 脚本导数据,并设置运行队列 bin/beeline -u 'url' --outputformat=tsv -e "set mapreduce.job.queuename= ...
- Hadoop中OutputFormat解析
一.OutputFormat OutputFormat描述的是MapReduce的输出格式,它主要的任务是: 1.验证job输出格式的有效性,如:检查输出的目录是否存在. 2.通过实现RecordWr ...
- 学生党如何拿到阿里技术offer: 《2016阿里巴巴校招内推offer之Java研发工程师(成功)》
摘要: 这篇文章字字珠玑,这位面试的学长并非计算机相关专业,但是其技术功底足以使很多计算机专业的学生汗颜,这篇文章值得我们仔细品读,其逻辑条理清晰,问题把握透彻,语言表达精炼,为我们提供了宝贵的学习经 ...
- 非计算机专业的伟伯是怎样拿到阿里Offer的。求职励志!!!
写在前面: 2015 年 7 月初.參加阿里巴巴校招内推, 8 月 15 日拿到研发project师 JAVA 的 offer .我的专业并不是计算机,也没有在互联网公司实习过,仅仅有一些学习和面试心 ...
- Hive企业级性能优化
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一. 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hi ...
- Hive参数与性能企业级调优
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一. 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hi ...
随机推荐
- spring初始化顺序
首先,Spring bean的默认加载顺序是怎么控制的 工程中有2个bean,A和B,其中必须先初始化A再初始化B,但是没有depend-on或者Order等方式去保证,只不过恰好刚好这么运行着没出事 ...
- 杂项-权限管理:Spring Secutity
ylbtech-杂项-权限管理:Spring Secutity Spring Security是一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架.它提供了一组可以在S ...
- STL string大小写 转换
std::string data = "This is a sample string."; // convert string to upper case std::for_ea ...
- shell入门-wc
命令:wc 选项:-l 查看行数 -w 以空白字符为分隔符 查看有多少单词 -m 查看字符数,文件大小 说明:统计指定文件中的字节数.字数.行数. -l [root@wangshaojun 11 ...
- USB插拔检测程序
一.手动添加ON_WM_DEVICECHANGE()消息 二.添加头文件#include <Dbt.h> 三.定义设备的GUID static const GUID GUID_DEVINT ...
- HTML5新增的结构元素
HTML5的结构 一:新增的主体结构元素 在HTML5中,为了使文档的结构更加清晰明确,追加了几个与页眉,页脚内容区块等文档结构相关联的结构元素. 1.1article元素 article元素代表文档 ...
- idea中java项目增加module后,增加的目录(src)无法增加包(Package)
在idea项目中,增肌model后,在项目根目录下增加src目录,右键发现无法增加包(Package). 仔细观察发现,新增加的src目录是棕色,而原先的src目录是浅蓝色的,见下图: 在src右键, ...
- vue-cli目录结构及说明
使用vue-cli有时会出现一些莫名的问题,清楚项目的结构文件及其意义方便更好的开发和解决问题,介绍如下: build/ // 项目构建(webpack)相关代码 build.js // 生产环境构建 ...
- django进阶之缓存
Model 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去调用数据访问层执行 ...
- SLF4J、Log4J使用记录
程序中一直在用log4j,之前都没了解过,只知道是打印日志信息的.最近独立新建了几个开发工程,发现slf4j老有冲突,开始关注起来,我用log4j打印日志,与slf4j有毛关系,怎么老冲突呢.网上找了 ...