bison 编译sql的基本知识
一。bison是干什么的?
bison 是一个语法分析器,把用户输入的内容,根绝在.y文件中事先定义好的规则,构建一课语法分析树。(所谓的规则就是,匹配上对应字符之后,执行相应的动作。)
1.一个简单的语法例子和分析:
statement :NAME '=' expression
expression :NUMBER '+' NUMBER
|NUMBER '-' NUMBER
这个语法的意思是:
冒号(:)用来间隔一条规则的左边和右边。
statement 等价于 NAME '=' expression 。
由于在语法中规定大写字母 和引号的内容为终结符,所以NAME '=' 两个字符不再有含义,已经终结。
但是expression 是非终结符,根据第二行的规定,expression 又等价为 两个数的加法或者两个数的减法。其中竖线(|)表示一个语法符号有两种等价方式。 NUMBER '+' NUMBER NUMBER '-' NUMBER均是终结符,所以语法解析结束。
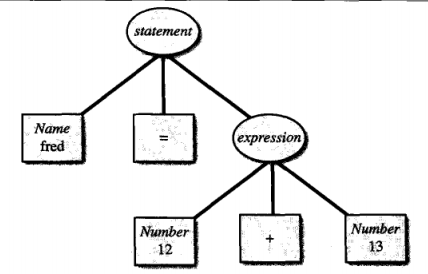
假如现在的输入是fred=12+13. 则语法解析树如下:(圆形都是非终结符,矩形都是终结符)
2.移进 规约分析
当bison处理一个语法分析树时,会创建一组状态,每个状态对应一个或者多个分析过的规则中的可能的位置。当读到的记号不足以结束一条规则的时候,就会把这个记号压入一个内部堆栈,然后切换到新状态,这个过程叫做移进。当压入栈内的所有的语法符号已经等价于一个规则的右部时,就把这些符号全部弹出,把规则的左部压入栈。这个过程叫做规约。
下面是一个例子:
fred=12+13
语法分析器一次移进一个记号。
堆栈:
fred
fred =
fred =12
fred=12 +
fred =12+13 把12+13 规约成expression,12+13弹出,expression压入
fred = expression 把fred = expression规约成statement fred = expression弹出,statement压入
statement
3.sql语言中的语法解析过程。(以select为例)
首先,需要一个词法分析器来识别SQL中的所有关键字。
程序的运行流程:(以select为例)
1.用户输入sql语句,调用sql.tab.c中的解析函数,得到select_statement的状态。(。y文件中为sql语句定义了好多个状态。)
2.select_statement作为参数,去匹配规则,并执行相应的动作,即构建一课语法树。这个匹配的过程由yyparse()库函数来完成!
下面这段代码是.y文件中,定义的关于select_statement部分的代码:
select_statement:
SELECT selection table_exp
{
struct stnode * p = create_non_terminal_node("select_section"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
selection:
scalar_exp_list
{
struct stnode * p = create_non_terminal_node("selection"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
| '*'
{
struct stnode * p = create_non_terminal_node("selection"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
;
scalar_exp_list:
scalar_exp
{
struct stnode * p = create_non_terminal_node("scalar_exp_list"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
| scalar_exp_list','scalar_exp
{
struct stnode * p = create_non_terminal_node("scalar_exp_list"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
;
table_exp:
from_clause
opt_order_by_clause
{
struct stnode * p = create_non_terminal_node("table_exp"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
;
from_clause:
FROM table_ref_list opt_where_clause
{
struct stnode * p = create_non_terminal_node("from_clause"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
; table_ref_list:
table_ref
{
struct stnode * p = create_non_terminal_node("table_ref_list"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
| table_ref_list','table_ref
{
struct stnode * p = create_non_terminal_node("table_ref_list"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
;
table_ref:
table
{
struct stnode * p = create_non_terminal_node("table_ref"); if(!p)
{
printf("error:create_non_terminal_node\n"); return ;
} if(!append_child(p, $))
{
printf("error:append_child\n"); return ;
} $$ = p;
}
;
3.根据上面代码中的定义的规则,,,,展示下面的语法树的构建过程:
规则 动作: 语法树
select_statement : SELECT selection table_exp node("select_section") select_statement
SELECT selection table_exp
selection : scalar_exp_list node("selection") *
|*
table_exp : from_clause opt_order_by_clause node("table_exp") from_clause opt_order_by_clause
from_clause: FROM table_ref_list opt_where_clause node("from_clause") FROM table_ref_list opt_where_clause
table_ref_list :table_ref
| table_ref_list','table_ref node("table_ref_list ") table_ref
table_ref: table node("table ") table

bison 编译sql的基本知识的更多相关文章
- SQL server基础知识(表操作、数据约束、多表链接查询)
SQL server基础知识 一.基础知识 (1).存储结构:数据库->表->数据 (2).管理数据库 增加:create database 数据库名称 删除:drop database ...
- Sql Server 基础知识
Sql Server 基础知识: http://blog.csdn.net/t6786780/article/details/4525652 Sql Server 语句大全: http://www.c ...
- atitit.查看预编译sql问号 本质and原理and查看原生sql语句
atitit.查看预编译sql问号 本质and原理and查看原生sql语句 1. 预编译原理. 1 2. preparedStatement 有三大优点: 1 3. How to look gene ...
- SQL数据库基础知识-巩固篇<一>
SQL数据库基础知识-巩固篇<一>... =============== 首先展示两款我个人很喜欢的数据库-专用于平时个人SQL技术的练习<特点:体积小,好安装和好卸载,功能完全够用 ...
- mybatis中预编译sql与非预编译sql
预编译sql有缓存作用,非预编译没得 mybaits中带有#传参的有预编译左右,$没得 多用#传参 预编译语句的优势在于归纳为:一次编译.多次运行,省去了解析优化等过程:此外预编译语句能防止sql注入 ...
- APK反编译之一:基础知识—APK、Dalvik字节码和smali文件
refs: APK反编译之一:基础知识http://blog.csdn.net/lpohvbe/article/details/7981386 APK反编译之二:工具介绍http://blog.csd ...
- SQL语句之 知识补充
SQL语句之 知识补充 一.存储过程 运用SQL语句,写出一个像函数的模块,这就是存储过程. 需求: 编写存储过程,查询所有员工 -- 创建存储过程(必须要指定结束符号) -- 定义结束符号 DELI ...
- hibernate预编译SQL语句中的setParameter和setParameterList
使用预编译SQL语句和占位符參数(在jdbc中是?),可以避免由于使用字符串拼接sql语句带来的复杂性.我们先来简单的看下.使用预编译SQL语句的优点. 使用String sql = "se ...
- 转:sql server锁知识及锁应用
sql server锁(lock)知识及锁应用 提示:这里所摘抄的关于锁的知识有的是不同sql server版本的,对应于特定版本时会有问题. 一 关于锁的基础知识 (一). 为什么要引入锁 当多个用 ...
随机推荐
- shell脚本注释方法
[1]单行注释 利用“#”对单行进行注释. 示例应用,新建文本,命名为test_single.sh 输入内容: # 单行注释 echo '单行注释' echo '123' # echo '456' e ...
- 一站式WPF--依赖属性(DependencyProperty)
2009-10-20 11:32 by 周永恒, 22441 阅读, 24 评论, 收藏, 编辑 书接上文,前篇文章介绍了依赖属性的原理和实现了一个简单的DependencyProperty(DP), ...
- 如何通过Google访问外网
修改host: https://laod.cn/hosts/2017-google-hosts.html google中文: https://www.google.com.hk/ 弄好前两项后,可以再 ...
- solr6.5的分词
1.配置solr6.5自带中文分词.复制/usr/local/solr/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5 ...
- 【iOS开发-80】Quartz2D绘图简介:直线/圆形/椭圆/方形以及上下文栈管理CGContextSaveGState/CGContextRestoreGState
本文转载至 http://blog.csdn.net/weisubao/article/details/41282457 - (void)drawRect:(CGRect)rect { //获得当前上 ...
- 字符串HASH模板
//注意MAXN是最大不同的HASH个数,一般HASHN是MAXN的两倍左右,MAXLEN表示字符串的最大长度 //K表示正确率,越大正确率越高,当时也越费空间,费时间. //使用前注意初始化hash ...
- 【BZOJ1226】[SDOI2009]学校食堂Dining 状压DP
[BZOJ1226][SDOI2009]学校食堂Dining Description 小F 的学校在城市的一个偏僻角落,所有学生都只好在学校吃饭.学校有一个食堂,虽然简陋,但食堂大厨总能做出让同学们满 ...
- MySql存储过程及MySql常用流程控制语法
/* 该代码是创建了一个名叫"p4"的存储过程并设置了s1,s2,s3两个int型一个varchar型参数,还可以是其他数据类型,内部创建了x1,x2两个变量 DELIMITER是 ...
- Java中线程和线程池
Java中开启多线程的三种方式 1.通过继承Thread实现 public class ThreadDemo extends Thread{ public void run(){ System.out ...
- maven assembly 配置详解
Maven Assembly插件介绍 博客分类: 项目构建 你是否想要创建一个包含脚本.配置文件以及所有运行时所依赖的元素(jar)Assembly插件能帮你构建一个完整的发布包. Assembl ...