Spark性能优化——和shuffle搏斗
Spark的性能分析和调优很有意思,今天再写一篇。主要话题是shuffle,当然也牵涉一些其他代码上的小把戏。
以前写过一篇文章,比较了几种不同场景的性能优化,包括portal的性能优化,web service的性能优化,还有Spark job的性能优化。Spark的性能优化有一些特殊的地方,比如实时性一般不在考虑范围之内,通常我们用Spark来处理的数据,都是要求异步得到结果的数据;再比如数据量一般都很大,要不然也没有必要在集群上操纵这么一个大家伙,等等。事实上,我们都知道没有银弹,但是每一种性能优化场景都有一些特定的“大boss”,通常抓住和解决大boss以后,能解决其中一大部分问题。比如对于portal来说,是页面静态化,对于web service来说,是高并发(当然,这两种可以说并不确切,这只是针对我参与的项目总结的经验而已),而对于Spark来说,这个大boss就是shuffle。
首先要明确什么是shuffle。Shuffle指的是从map阶段到reduce阶段转换的时候,即map的output向着reduce的input映射的时候,并非节点一一对应的,即干map工作的slave A,它的输出可能要分散跑到reduce节点A、B、C、D …… X、Y、Z去,就好像shuffle的字面意思“洗牌”一样,这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。(下面这幅图来自《Spark Architecture: Shuffle》)
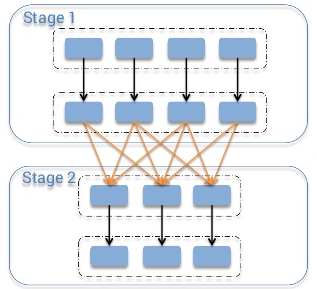
为什么说shuffle是Spark job的大boss,就是因为Spark本身的计算通常都是在内存中完成的,比如这样一个map结构的RDD:(String, Seq),key是字符串,value是一个Seq,如果只是对value进行一一映射的map操作,比如(1)先计算Seq的长度,(2)再把这个长度作为元素添加到Seq里面去。这两步计算,都可以在local完成,而事实上也是在内存中操作完成的,换言之,不需要跑到别的node上去拿数据,因此执行的速度是非常快的。但是,如果对于一个大的rdd,shuffle发生的时候,就会因为网络传输、数据序列化/反序列化产生大量的磁盘IO和CPU开销。这个性能上的损失是非常巨大的。
要减少shuffle的开销,主要有两个思路:
- 减少shuffle次数,尽量不改变key,把数据处理在local完成;
- 减少shuffle的数据规模。
先去重,再合并
比如有A、B这样两个规模比较大的RDD,如果各自内部有大量重复,那么二者一合并,再去重:
|
1
|
A.union(B).distinct() |
这样的操作固然正确,但是如果可以先各自去重,再合并,再去重,可以大幅度减小shuffle的开销(注意Spark的默认union和Oracle里面的“union all”很像——不去重):
|
1
|
A.distinct().union(B.distinct()).distinct() |
看起来变复杂了对不对,但是当时我解决这个问题的时候,用第二种方法时间开销从3个小时减到20分钟。
如果中间结果rdd如果被调用多次,可以显式调用cache()和persist(),以告知Spark,保留当前rdd。当然,即便不这么做,Spark依然存放不久前计算过的结果(以下来自官方指南):
Spark also automatically persists some intermediate data in shuffle operations (e.g. reduceByKey), even without users calling persist. This is done to avoid recomputing the entire input if a node fails during the shuffle. We still recommend users call persist on the resulting RDD if they plan to reuse it.
数据量大,并不一定慢。通常情况下,由于Spark的job是放到内存里面进行运算的,因此一个复杂的map操作不一定执行起来很慢。但是如果牵涉到shuffle,这里面有网络传输和序列化的问题,就有可能非常慢。
类似地,还有filter等等操作,目的也是要先对大的RDD进行“瘦身”操作,然后在做其他操作。
mapValues比map好
明确key不会变的map,就用mapValues来替代,因为这样可以保证Spark不会shuffle你的数据:
|
1
|
A.map{case (A, ((B, C), (D, E))) => (A, (B, C, E))} |
改成:
|
1
|
A.mapValues{case ((B, C), (D, E)) => (B, C, E)} |
用broadcast + filter来代替join
这种优化是一种特定场景的神器,就是拿大的RDD A去join一个小的RDD B,比如有这样两个RDD:
- A的结构为(name, age, sex),表示全国人民的RDD,超大
- B的结果为(age, title),表示“年龄 -> 称号”的映射,比如60岁有称号“花甲之年”,70岁则是“古稀之年”,这个RDD显然很小,因为人的年龄范围在0~200岁之间,而且有的“年龄”还没有“称号”
现在我要从全国人民中找出这些有称号的人来。如果直接写成:
|
1
2
3
|
A.map{case (name, age, sex) => (age, (name, sex))} .join(B) .map{case (age, ((name, sex), title)) => (name, age, sex)} |
你就可以想象,执行的时候超大的A被打散和分发到各个节点去。而且更要命的是,为了恢复一开始的(name, age, sex)的结构,又做了一次map,而这次map一样导致shuffle。两次shuffle,太疯狂了。但是如果这样写:
|
1
2
|
val b = sc.broadcast(B.collectAsMap)A.filter{case (name, age, sex) => b.values.contains(age)} |
一次shuffle都没有,A老老实实待着不动,等着全量的B被分发过来。
另外,在Spark SQL里面直接有BroadcastHashJoin,也是把小的rdd广播出去。
不均匀的shuffle
在工作中遇到这样一个问题,需要转换成这样一个非常巨大的RDD A,结构是(countryId, product),key是国家id,value是商品的具体信息。当时在shuffle的时候,这个hash算法是根据key来选择节点的,但是事实上这个countryId的分布是极其不均匀的,大部分商品都在美国(countryId=1),于是我们通过Ganglia看到,其中一台slave的CPU特别高,计算全部聚集到那一台去了。
找到原因以后,问题解决就容易了,要么避免这个shuffle,要么改进一下key,让它的shuffle能够均匀分布(比如可以拿countryId+商品名称的tuple作key,甚至生成一个随机串)。
明确哪些操作必须在master完成
如果想打印一些东西到stdout里去:
|
1
|
A.foreach(println) |
想把RDD的内容逐条打印出来,但是结果却没有出现在stdout里面,因为这一步操作被放到slave上面去执行了。其实只需要collect一下,这些内容就被加载到master的内存中打印了:
|
1
|
A.collect.foreach(println) |
再比如,如果遇到RDD操作嵌套的情况,通常考虑优化掉,因为只有master才能去理解和执行RDD的操作,slave只能处理被分配的task而已。比如:
|
1
|
A.map{case (keyA, valueA) => doSomething(B.lookup(keyA).head, valueA)} |
就可以用join来代替:
|
1
|
A.join(B).map{case (key, (valueA, valueB)) => doSomething(valueB, valueA)} |
用reduceByKey代替groupByKey
这一条应该是比较经典的了。reduceByKey会在当前节点(local)中做reduce操作,也就是说,会在shuffle前,尽可能地减小数据量。而groupByKey则不是,它会不做任何处理而直接去shuffle。当然,有一些场景下,功能上二者并不能互相替换。因为reduceByKey要求参与运算的value,并且和输出的value类型要一样,但是groupByKey则没有这个要求。
有一些类似的xxxByKey操作,都比groupByKey好,比如foldByKey和aggregateByKey。
另外,还有一条类似的是用treeReduce来代替reduce,主要是用于单个reduce操作开销比较大,可以条件treeReduce的深度来控制每次reduce的规模。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接《四火的唠叨》
Spark性能优化——和shuffle搏斗的更多相关文章
- Spark性能优化:shuffle调优
调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行 ...
- Spark性能优化(1)——序列化、内存、并行度、数据存储格式、Shuffle
序列化 背景: 在以下过程中,需要对数据进行序列化: shuffling data时需要通过网络传输数据 RDD序列化到磁盘时 性能优化点: Spark默认的序列化类型是Java序列化.Java序列化 ...
- Spark性能优化指南-高级篇(spark shuffle)
Spark性能优化指南-高级篇(spark shuffle) 非常好的讲解
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
- 【转载】 Spark性能优化指南——基础篇
转自:http://tech.meituan.com/spark-tuning-basic.html?from=timeline 前言 开发调优 调优概述 原则一:避免创建重复的RDD 原则二:尽可能 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- 【转】Spark性能优化指南——基础篇
http://mp.weixin.qq.com/s?__biz=MjM5NDMwNjMzNA==&mid=2651805828&idx=1&sn=2f413828d1fdc6a ...
- Spark性能优化指南——高级篇(转载)
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能优化指南——基础篇(转载)
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- mysql中数据库与数据表编码格式的查看、创建及修改
一.查看数据库编码格式 ? 1 mysql> show variables like 'character_set_database'; 二.查看数据表的编码格式 ? 1 mysql> s ...
- Codeforces Round #518 (Div. 2) D(计数DP)
#include<bits/stdc++.h>using namespace std;const long long mod=998244353;int n;int a[100007];l ...
- [Xcode 实际操作]五、使用表格-(4)设置UITableView单元格数据库源
目录:[Swift]Xcode实际操作 本文将演示如何自定义表格的数据来源. 在项目导航区,打开视图控制器的代码文件[ViewController.swift] import UIKit //首先添加 ...
- MySQL服务器与MySQL57服务器区别与不同处在哪里,他们各自的领域范围,能不能同时启动服务?
安装了MySQL-5.7.18.0版本数据库,版本中包含了MySQL Workbench可视化试图工具,在服务列表栏中会有MySQL的两个服务器:如果启动第一项MySQL服务器就只能操作数据库,外界不 ...
- JS键盘事件之键控Div
自上次做的鼠标拖动Div之后,看到fgm.cc的例子,发现用键盘操控Div貌似也是十分有趣,这些DOM操作随着jquery的没落,虽然渐渐少用了,不过有些DOM操作还是必不可少的.现在是虽然数据为王( ...
- Flask&&人工智能AI --4
一.flask请求上下文源码解读 通过上篇源码分析,我们知道了有请求发来的时候就执行了app(Flask的实例化对象)的__call__方法,而__call__方法返回了app的wsgi_app(en ...
- Java面向对象_简单工厂模式
概念:由一个工厂对象决定创建出哪一种产品类的实例. public class Practice14 { public static void main(String[] args) { // TODO ...
- (转)vimdiff 快速比较和合并少量文件
vimdiff 快速比较和合并少量文件 原文:http://www.cnblogs.com/abeen/p/4255754.html 纯文本文件比较和合并工具一直是软件开发过程中比较重要的组成部分,v ...
- Spark编程模型(中)
创建RDD 方式一:从集合创建RDD makeRDD Parallelize 注意:makeRDD可以指定每个分区perferredLocations参数parallelize则没有. 方式二:读取外 ...
- ThreadPoolExecutor线程池的keepAliveTime
keepAliveTime含义 看了很多文章觉得都不能把keepAliveTime的意思说的很明白,希望通过自己的理解把keepAliveTime说的明确一些 先引用一句我觉得相对说的比较明白的含义: ...