Multi-task Pose-Invariant Face Recognition 论文笔记
摘要:
在不受限制的环境中拍摄的人脸图像通常包含显著的姿态变化,这会显著降低设计用于识别正面的算法的性能。本文提出了一种新颖的面部识别框架,能够处理±90°偏航范围内的全方位姿势变化。所提出的框架首先将原始姿态不变人脸识别问题转化为局部正面人脸识别问题。然后开发了一个健壮的基于块的人脸表示方案来表示合成的局部正面。对于每个块,在提出的多任务学习方案下学习转换字典。转换字典将不同姿势的特征转换为判别性子空间。最后,面部匹配是在块级而不是整体级执行的。在FERET,CMU-PIE和Multi-PIE数据库上进行广泛而系统的实验表明,所提出的方法始终优于基于单任务的基线以及针对姿态问题的最先进的方法。我们进一步扩展了无约束面部验证问题的算法,并在具有挑战性的LFW数据集上实现顶级性能。
1 引言
FACE识别已经超过三十年来一直是计算机视觉领域最活跃的研究课题之一。 经过多年的努力,在受控[1]和不受控制的环境[2],[3]中,自动人脸识别都取得了令人鼓舞的成果。 然而,人脸识别仍然受到现实世界图像中经常遇到的姿态,光照和表情的变化的显著影响。 正如最近的工作[4]所指出的那样,姿态问题在很大程度上仍然没有解决。 在本文中,我们主要处理将任意姿势侧面与正面人面匹配的识别问题,这是姿态不变人脸识别(PIFR)研究和应用的最常见设置[4] - [8]。 在文章的最后,我们简单地扩展了所提出的解决无约束面部验证问题的方法[9]。
姿势变化引起脸部图像戏剧性的外观变化。 本质上,这是由人体头部的复杂三维几何结构引起的。 如图1所示,头部的旋转导致自闭塞,这意味着一些面部纹理将随着姿态的变化而不可见。 姿势问题通常还会与其他因素(如光照和表情的变化)结合起来影响人脸图像的外观。 结果,姿态变化引起的外观变化程度通常大于身份差异引起的变化程度,而当要匹配的图像具有不同姿态时,正面人脸识别算法的性能会急剧下降。

直接匹配不同姿势的脸部是困难的。 一个直观的解决方案是进行人脸合成,以便两个人脸图像可以在相同姿势下进行比较。 遵循这一思想的大多数方法都致力于从非正面人脸恢复完整的正面[4],[8],[10] - [12]。 然而,从配置文件面合成整个正面人脸是困难的,因为大多数面部纹理由于遮挡而不可见。 因此,上述方法倾向于将其识别能力限制在偏航变化的±45°内。
通过观察人类可以容易地识别人脸,而不需要细致地恢复整个正面面部的启发,我们提出了一种新的面部表示方法,它充分利用了无遮挡的面部纹理。这种表示方法在本质上是通用的,这意味着它连续地应用于90°和90°偏航之间的姿态变化的全范围。使用简单的姿态归一化和预处理操作,我们的方法将原始PIFR(姿势不变人脸识别)问题转换成部分人脸识别任务[13 ],[14 ],其中面部以基于块的方式由未遮挡的面部部分表示。因此,所提出的人脸表示方案称为基于块的部分表示(PBPR)。
特征变换通过将图像中的特征转换为常见的判别性子空间来增强识别能力。 基于这种直觉,我们提出了一种称为多任务特征变换学习(MtFTL)的学习方法。 通过考虑不同姿势的变换矩阵之间的相关性,MtFTL始终比其基于单任务的人脸识别有更好的性能。 当训练数据的规模有限时,其优势尤为明显。 MtFTL学习的变换矩阵非常紧凑,因为共享大多数姿态的投影向量,从而降低了内存成本。
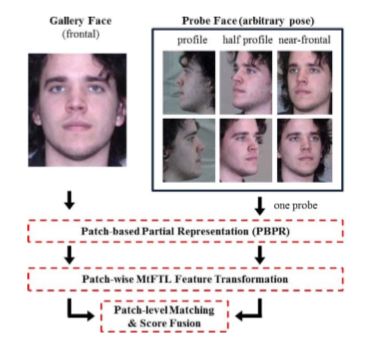
我们将整个提出的框架称为解决姿势问题PBPR-MtFTL。 在这个框架下,匹配一个任意的姿势侧面和正面的人脸,然后使用学习的MtFTL变换字典对提取的PBPR表示进行变换,然后是块级余弦距离计算和分数融合,如图2所示。 FERET,CMU-PIE和Multi-PIE数据集表明PBPR-MtFTL始终如一地实现出众的性能。
本文的其余部分安排如下:第二节简要回顾PIFR和多任务学习的相关工作。 第三部分阐述了拟议的PBPR人脸表征方案。 第四节描述了多任务特征转换学习方法MtFTL。 第五部分介绍了使用PBPR-MtFTL进行人脸匹配。第六部分介绍了实验结果,第七部分得出结论。
1 相关研究
A、 姿势不变人脸识别(PIFR)
已经提出了许多有希望的方法来解决人脸识别中的姿态挑战[15]。 这些方法可以大致分为两类:基于面部图像合成的方法和无合成方法。大多数以前的方法依赖于人脸图像合成,人脸图像合成可以用2D或3D技术完成。具体略。无合成方法旨在提取姿态鲁棒特征或将特征从不同姿态转换为共享子空间。
我们的工作与这两个类别有关,并且具有明显的新颖性:首先,所提出的PBPR方法从部分人脸识别的角度来表示任意姿态的人脸图像。 其次,基于多任务学习的原理,MtFTL方法学习各种姿势的紧凑特征变换,这对于PIFR是新颖的。 第三,PBPR-MtFTL框架不断解决从-90°到+ 90°偏航的全方位姿态变化,并获得强大的性能。
B、 多任务学习
多任务学习(MTL)是一种机器学习技术,通过捕获不同任务之间的内在关联,可以同时学习多个任务以获得更好的性能。 MTL隐含地增加了样本量并提高了每个任务的泛化能力; 因此,当任务的训练数据很小时尤其有利。
虽然MTL已被广泛应用于计算机视觉任务,例如视觉跟踪[33],动作识别[34] - [36]和人脸识别[37],[38],它是PIFR的新功能。 现有的PIFR方法忽略了不同姿势的特征变换之间的相关性[26,28]。 据我们所知,对于PIFR的MTL仅在[39]中简单提及,但没有提供详细信息,并且多视点重建是针对性的而不是特征转换学习。 尽管如此,如果我们将每个姿势的特征变换学习视为一项任务,MTL为我们提供了一个原则性方法来模拟姿势之间的相关性。 MtFTL可以说是第一个MTL方法,它可以共同学习不同姿势的特征变换,并且可以从潜在的姿势间相关性中获益。
2 姿势问题的面部表示
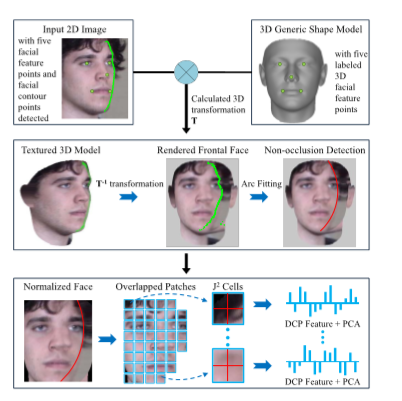
现有的人脸表示方法倾向于从人脸图像中提取固定长度特征,其基本假设是所有人脸部分在图像中都是可见的[13]。 在本节中,我们提出了灵活的(PBPR)人脸表示方案,其中人脸表示的长度与人脸姿态有关; 例如,正面人脸图像将具有比侧面人脸图像有更大的人脸表示。 这是合理的,因为侧面人脸提供的识别信息较少。 如图3所示,PBPR实质上由三个步骤组成:人脸姿态归一化,未遮挡面部纹理检测和面部块特征提取。 在本节中,我们将详细描述三个主要组件。
A、 人脸姿态归一化
标准的3D方法被用于人脸姿态归一化[22]。 五个最稳定的面部特征点,即双眼中心,鼻尖和两个嘴角,首先自动或手动检测。 对于侧面(如图2所示),估计遮挡面部特征点的坐标。 使用正交投影模型[40]和检测到的五个面部特征点,将3D通用形状模型与2D人脸图像对齐。然后,将2D人脸图像反投影到3D模型,并且正面人脸图像是用纹理3D模型渲染。
先前的研究依赖于密集的面部特征点,例如[22]中的68个点和[4]中的79个点,用于准确的姿势归一化。 然而,由于脸部严重的自我遮挡,检测侧面的密集面部特征点很困难,这反过来又限制了这些方法可以处理的姿势范围。 相反,本文中只有五个最稳定的面部特征点被用于姿态归一化。 这极大地促进了全自动人脸识别系统的实现,并扩展了可以处理的姿势范围。 尽管使用稀疏的面部特征点会导致更大的归一化误差,但我们强调了所提出的PBPR-MtFTL框架的功效,因为它的归一化要求很低。
B、 未遮挡面部纹理检测
姿态归一化纠正姿态变化导致的面部纹理变形,但不能恢复被遮挡损失的纹理。为了获得完整的正面人脸[4],我们建议充分利用未被遮挡的纹理。 这是从人们可以轻松识别侧面而不需要恢复整个正面的观察中得到灵感的。 如图3所示,遮挡和未遮挡面部纹理之间的主要边界是面部轮廓。 因此,面部轮廓检测是识别遮挡面部纹理的关键。
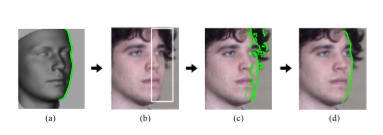
(虽然有用于面部轮廓检测的现成的工具,但它们只返回稀疏的面部轮廓点,并且可能不够可靠以致严重的遮挡,表情和姿势变化。)我们提出了一种使用3D通用形状模型的更简单但有效的方法。在对齐3D模型和2D人脸图像之后,可以将其大致投影到2D图像平面上的2D人脸姿态。如图4(a)所示,3D模型的轮廓可以很容易地检测到。基于3D模型的轮廓,2D面部的面部轮廓搜索可以被约束在特定区域内,如图4(b)所示。然后由Canny算子在这个区域检测边缘点[42]。为了减少冒名顶替者,只有具有水平梯度方向的边缘点被保存,其中面部轮廓在垂直方向上延伸。最后,通过点漂移算法(CPD)获得面部轮廓(边界线) [43]。简单地说,CPD通过仿射变换将图4(a)中突出显示的面部轮廓迭代地对齐到图4(c)所示的边缘点集。图4(c)中的冒充者轮廓点可以逐渐被检测和忽略。得到的面部轮廓如图4(d)所示。
除了在第一步中投影面部纹理外,检测到的面部轮廓点首先投影到3D模型,然后投影到渲染的正面人脸图像。 由于头部近似为椭圆形,因此正面视图中的面部轮廓点将以弧形配置。 如图3所示,弧有效地分离了被渲染的前侧图像中的未被遮挡和被遮挡的纹理。在下面的小节中,仅使用检测到的未被遮挡的面部纹理来构建人脸表示。
A、 面部块特征提取
呈现的正面视图中的未被遮挡的面部纹理的区域随着姿势改变而变化,可用于面部识别的有效信息量的明显波动。 鉴于这种观察,提出了一种可变长度的人脸表示方法。
如图3所示,归一化脸部图像首先被分成M×N个重叠的块。 然后基于在被遮挡和未被遮挡的面部纹理之间检测到的边界来评估每个块的遮挡严重性。 如果一个块中超过80%的像素落入未被遮挡的区域,则将其指定为未被遮挡的块; 否则,由于大面积的遮挡,块被忽略。 接下来,将每个未被遮挡的块分成J×J个单元。 一种名为DualCross Patterns(DCP)[2]的最新局部描述符被用于特征提取。 计算每个小块的DCP特征,得到DCP直方图。DCP直方图中的元素通过平方根归一化。 最后,将主成分分析(PCA)应用于每个块,将其特征投影到维度为D的子空间中,从而抑制噪声。
经过PCA处理后,所有未被遮挡的块的一组块级DCP特征形成了面部图像的表示形式。 请注意,这种表示方法本质上是通用的,这意味着它适用于具有任意姿势的面。 这是一个有价值的属性,因为我们不需要将不同的算法应用于正面和非正面,这与现有的一些方法不同[8]。
1 多任务特征转换学习
前一节已经介绍了PBPR人脸表示方案,其中人脸识别可以通过直接匹配两个人脸图像的相应的人脸特征来实现。 在这一节中,我们进一步提出了用于学习转换字典的MtFTL方法,它使得正面和非正面人脸的块特征能够转化为一个更有识别力的空间。 学习过程是块级的,这意味着MtFTL会为每个块学习单独的转换字典。 因此,我们获得了M×N个变换字典。 下面举例说明了MtFTL方法的细节。
A、 特征转换学习
在特征转换学习的设计中考虑了三个方面。 首先,如图6所示,来自不同姿势的归一化图像具有不同的图像质量,因此对于不同姿势的变换将存在差异。 其次,不同姿势的特征变换之间存在很强的相关性,因为它们本质上处理相同主题的数据。 第三,由于收集多姿态脸部图像往往很困难,因此在实际情况下训练数据量可能会受到限制。 理想情况下,应该利用来自不同姿势的共享知识进行有效的转换学习。

这些考虑要求用于特征转换学习的多任务策略,其中每种姿势类型的学习被视为任务。 因此,我们提出了考虑任务之间的相关性和差异性的MtFTL方法。 而不是为每个任务学习单独的变换矩阵[44],MtFTL为所有任务学习一个共同的变换字典。 通过在转换字典中选择不同投影向量来反映任务之间的差异。 因此,MtFTL学习比以前的方法更紧凑的特征变换[44]。
(基于姿态不变特征的方法,即寻求那些不随姿态的变化而变化的特征。我们的思路是采用基于统计的视觉模型,将输入姿态图像校正为正面图像,从而可以在统一的姿态空间内作特征的提取和匹配。因此,基于单姿态视图的多姿态视图生成算法将是我们要研究的核心算法,我们的基本思路是采用机器学习算法学习姿态的2D变化模式,并将一般人脸的3D模型作为先验知识,补偿2D姿态变换中不可见的部分,并将其应用到新的输入图像上去。)
5 实验评估
在这一部分中,进行了大量的实验来证明PBPR MTFTL的有效性。我们主要针对姿势问题的三个最流行的数据库进行识别实验,即CMU-PIE [48],FERET [49]和Multi-PIE [50]。
CMU-PIE [48]和FERET [49]数据集分别包含68和200个受试者的多姿势图像。 对于这两个数据库,我们采用与以前的工作[7],[18]相同的协议,不包括光照和表情变化[51]。 Multi-PIE [50]数据库包含337个对象的图像, 由于没有统一的姿态问题Multi-PIE协议,我们采用了文献[17],[22],[39]中三种最流行的协议。
进行了八组实验。 首先,PBPR-MtFTL的性能与之前在CMU-PIE和FERET上的PIFR的性能相比略有不同。 接下来,将MtFTL方法与Multi-PIE上的单任务基线进行比较,以证明MTL对姿态问题的重要性。 然后,考虑到姿势问题经常与其他因素结合,我们在三种不同的设置中评估PBPR-MtFTL的性能
本文中的所有图像均标准化如下。采用巴塞尔人脸模型(BFM)[52]的平均形状作为3D一般形状模型。五个面部特征点在前六次实验中手动标记,并在最后两次实验中自动检测到
对于每个识别实验,训练数据中的主体随机分为两个子集,一个用于模型训练,另一个用于验证。 这两个子集的大小相同。 模型参数μ,d和λ的最优值在验证子集上进行估计并应用于测试数据。
A、 在CMU-PIE和FERET上的比较
所有68个CMU-PIE受试者使用11个不同姿势的中性表情和正常照明。 请注意,姿态类型C31和C25具有混合偏航和俯仰变化。 68个正面图像用作图库图像,其余所有图像用作探测。 根据之前的工作[18],[57],我们在Multi-PIE数据库中随机选择50个受试者来训练MtFTL模型,因为CMU-PIE中只有68个受试者。 对于FERET,合并了9个不同姿势的所有200名受试者。 前100名受试者的图像包含训练数据,其余100名受试者用于测试。
如表II和表III所示,所提出的PBPR-MtFTL方法优于其他方法。 但是PBPR-MtFTL的优势并没有得到很好的展现,因为现有方法的性能已经接近两个数据库的饱和点。 因此,我们专注于以下实验中更大和更具挑战性的Multi-PIE数据库
B、 与单任务基线比较
在这个实验中,我们的目标是证明MTL对姿势问题的重要性。 提出的MtFTL算法与三个单任务基线进行比较:(a)线性判别分析(LDA)方法,该方法学习所有姿势的单个LDA模型; (b)单任务特征转换学习(StFTL)方法,该方法学习所有姿势的单个特征变换。 StFTL等同于区分对比(DLA)模型[58]; (c)多独立特征变换学习(MiFTL)方法,其独立地学习每个姿势的DLA模型。 与LDA和StFTL不同,MtFTL和MiFTL学习姿态特定的特征变换。 MtFTL和MiFTLis之间的主要区别是MiFTL独立地学习每个姿态的变换,而MtFTL同时学习紧凑变换并且从不同姿态的相关性中受益。
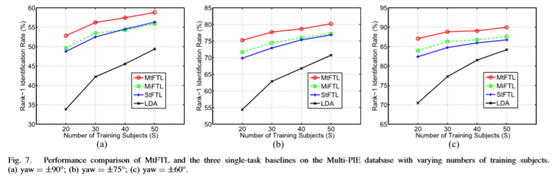
如图7所示,在所有设置下,MtFTL总是优于基线。 具体而言,MtFTL明显优于StFTL和LDA,这意味着学习需要特定的特征转换。 MtFTL在学习更紧凑的转换时优于MiFTL。 这证明MTL有助于增强识别非正面人脸的能力。 当训练数据量有限时,MtFTL的优势更加明显,这表明相关任务之间的知识共享对于更好的泛化能力具有重要意义。
A、 姿态与光照识别
在这一小节中,将PBPR-MtFTL框架的性能与姿态和照度的组合变化设置下的现有算法进行比较。 采用的协议与之前的实验相同[17]。 实验结果如表4和图8所示。一般而言,姿态和照度组合变化的人脸识别是一个困难的问题。 然而,很明显,即使只有一半的训练数据被用来训练MtFTL模型,所提出的方法仍然优于现有方法[12],[17]。
值得注意的是[17]中提出的算法也采用光度归一化,并且所有三种方法都使用手动标记的面部特征点。 值得注意的是,我们使用与[12]中所遵循的方法完全相同的面部特征点坐标。
B、 对整个姿势和记录环节的识别
这个实验是为了在姿势和记录会话的组合变化下测试算法的性能。 遵循[22]中描述的协议。 该协议涵盖四个记录会话中的所有337个主题仅使用具有中性表达和正面照明的图像。 使用前200名受试者(受试者ID 001至200)的图像进行训练,并使用其余137名受试者(受试者ID 201至346)的图像进行测试。 来自测试对象的最早记录会话的正面图像被收集作为图库集(总共137个图像)。 测试对象的非正面图像构建了14个测试集。 我们的方法与最先进的方法之间的比较见表五和图9.我们观察到:
1)一般来说,当探头图像的姿态值很小时,所有算法的性能都很好。 尽管探针组130,140,050和041上的所有方法均可实现高性能,但我们的方法在所有四个探针组上实现了完美的识别率。
2)探头组080和190上现有方法的性能大幅下降,其中偏航角度为±45°。 PBPR-MtFTL在两个探头组上都比其他方法显着更好,这表明它对于较大的姿态变化更加稳健。
3)虽然大多数现有的方法只能处理[-45°,+ 45°]范围内的偏航角度变化,所提出的方法可以解决全方位的偏航角度变化。 图9显示,即使偏航角接近±75°,也可获得高性能。
6、结论
由于姿态变化引起的显着外观变化,跨姿势的人脸识别是一项具有挑战性的任务。我们从两个方面处理这个问题。首先,我们提出PBPR人脸表示方案,它仅利用未被遮挡的人脸纹理。 PBPR可以应用于以任意姿势面对图像,这比现有方法具有很大的优势。其次,我们通过利用姿势之间的相关性来呈现用于学习紧凑特征变换的MtFTL模型。与基于单任务的方法相比,显示出明显的优势。据我们所知,这是MTL首次正式应用于PIFR问题。由于所提出的PBPR-MtFTL框架有效地利用了所有未被遮挡的人脸纹理以及不同姿势之间的相关性,所有三个流行的多姿势数据库中的人脸识别都取得了令人鼓舞的结果。我们还略微修改了处理无约束验证问题的方法,具有挑战性的LFW数据库的性能。
多任务学习:多任务学习是一种归纳迁移方法,充分利用隐含在多个相关任务训练信号中的特定领域信息。在后向传播过程中,多任务学习允许共享隐层中专用于某个任务的特征被其他任务使用;多任务学习将可以学习到可适用于几个不同任务的特征,这样的特征在单任务学习网络中往往不容易学到。 多个任务并行训练并共享不同任务已学到的特征表示,是多任务学习的核心思想。
Multi-task Pose-Invariant Face Recognition 论文笔记的更多相关文章
- Selective Search for Object Recognition 论文笔记【图片目标分割】
这篇笔记,仅仅是对选择性算法介绍一下原理性知识,不对公式进行推倒. 前言: 这篇论文介绍的是,如果快速的找到的可能是物体目标的区域,不像使用传统的滑动窗口来暴力进行区域识别.这里是使用算法从多个维度对 ...
- Improved RGB-D-T based Face Recognition 论文笔记
本文将基于深度学习的卷积神经网络(CNN)应用于基于RGB-D-T的多模态人脸识别问题. 此外,引入了基于CNN的识别模块与各种纹理特征(LBP,HOG,HAAR,HOGOM)的后期融合,在基准RGB ...
- Deep Residual Learning for Image Recognition论文笔记
Abstract We present a residual learning framework to ease the training of networks that are substant ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- 论文笔记之:Natural Language Object Retrieval
论文笔记之:Natural Language Object Retrieval 2017-07-10 16:50:43 本文旨在通过给定的文本描述,在图像中去实现物体的定位和识别.大致流程图如下 ...
随机推荐
- 蓝牙通讯 ble
http://blog.csdn.net/beijingshi1/article/details/36426829
- 【Linux不需要磁盘碎片整理的真正原因是因为Linux只是一个内核,它没有磁盘可以整理】
[Linux不需要磁盘碎片整理的真正原因是因为Linux只是一个内核,它没有磁盘可以整理]
- jquery带下拉菜单和焦点图
jQuery,下拉菜单,二级菜单,索引按钮,焦点图代码,jquery带下拉菜单和焦点图是一款顶部通栏带二级下拉菜单和banner导航菜单代码. JQuery特效代码来源:http://www.huiy ...
- [深入学习C#]C#实现多线程的方式:使用Parallel类
简介 在C#中实现多线程的另一个方式是使用Parallel类. 在.NET4中 ,另一个新增的抽象线程是Parallel类 .这个类定义了并行的for和foreach的 静态方法.在为 for和 f ...
- Execution Context(EC) in ECMAScript
参考资料 执行环境,作用域理解 深入理解JavaScript系列(2):揭秘命名函数表达式 深入理解JavaScript系列(12):变量对象(Variable Object) 深入理解JavaScr ...
- 关于android 图片加载优化
android应用对图片处理算是比较频繁的了,尤其是在程序加载大量图片和高分辨率图片时,最容易产生oom异常,下面是个人平时一些省内存加载方法 方法一: public Bitmap decodeFil ...
- Android之Widget学习总结
1.Widget设计步骤 需要修改三个XML,一个class: 1)第一个xml是布局XML文件(如:main.xml),是这个widget的.一般来说如果用这个部件显示时间,那就只在这个布局XML中 ...
- 判断CPU是大端还是小端
#include "stdafx.h" #include <iostream> using namespace std; /* #大端模式(Big_endian):字数 ...
- 利用stomp.js实现websocket功能,接收ActiveMQ消息队列
一.ActiveMQ消息发送端 package lixj; import java.util.Date; import javax.jms.Connection; import javax.jms.C ...
- C++ STL, set用法。 待更新zzzzz
set集合容器:实现了红黑树的平衡二叉检索树的数据结构,插入元素时,它会自动调整二叉树的排列,把元素放到适当的位置,以保证每个子树根节点键值大于左子树所有节点的键值,小于右子树所有节点的键值:另外,还 ...