爬虫入门【6】Selenium用法简介
Selenium 是什么?
一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器。
如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。
换句话说叫 Selenium 支持这些浏览器驱动。
我们在Python里面安装Selenium的话,就可以调用浏览器来访问web界面了。
下载WebDriver
Selenium调用web需要由对应的浏览器驱动来支持。
首先要确认自己的系统版本,我安装的是win10,在系统设置里面查询一下自己的版本号。
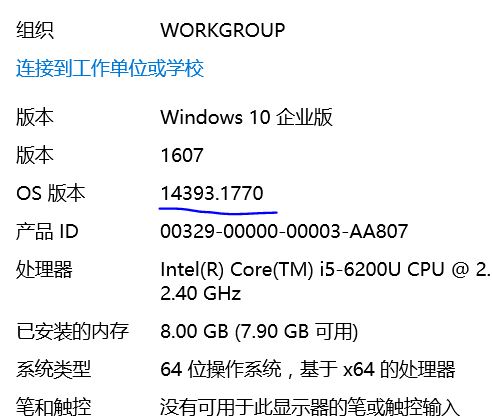
本来想下载Chrome或者FireFox的驱动,但是Selenium的官网点进去想下载都困难。。。。
----------------------------我是华丽的分割线--------------------------------------------------------
突然又下好了,地址为http://www.seleniumhq.org/download/,Chrome和Firefox的。
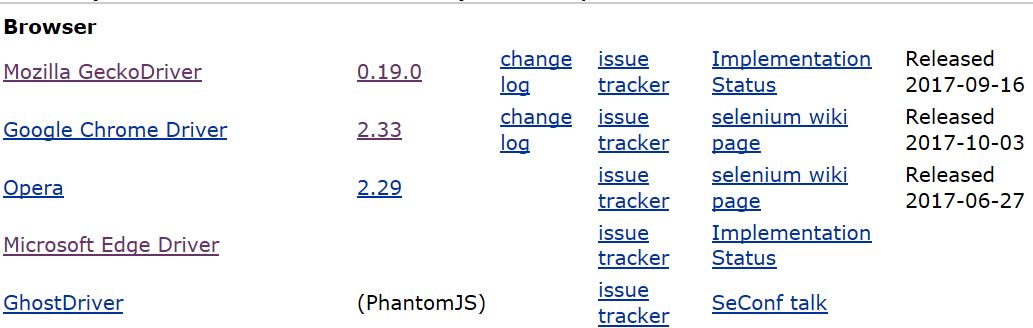
但是由于WebDriver的版本问题,打开还是有些困难,回头再弄把。。先用Edge。
----------------------------我是华丽的分割线--------------------------------------------------------
Firefox的好了,之前因为下载的win32版本的,一定要下载与自己系统匹配的,我的是win64的。
Chrome的没有win64的版本,所以一直没有成功。。。
后悔当时没上Mac。
顺道把PhantomJS的driver下载好,http://phantomjs.org/download.html,也是放到C:\Py35\Scripts,回头用到的时候再讲。
----------------------------我是华丽的分割线--------------------------------------------------------
退而求其次,下载win10自带的Edge的WebDriver。
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
将下载好的webdriver放到python的安装目录下,我的目录是C:\Py35\Scripts,你可以参考一下。
根本原因是我们已经将C:\Py35\Scripts设置到系统的Path中。
安装Selenium
然后在安装Selenium库,这里简单介绍一下,我使用的是PyCharm IDE,所以安装比较简单。请在File-Setting里面搜索。
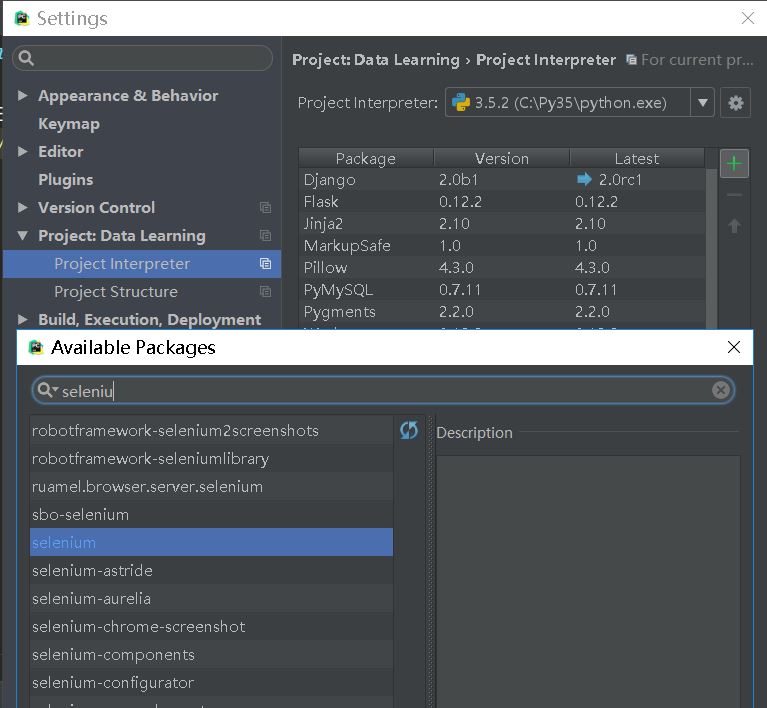
如果没有使用Selenium,可以使用pip命令。这里就不展开说的。
好了,都安装好了,开始学习吧~
快速入门的一个范例
假如你已经按照上面的介绍安装好了,那么按照下面的方法来导入selenium
selenium提供了很多浏览器的支持,今天使用Firefox。
Keys类提供了键盘上的大多数按键功能,用于模拟操作
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#创建FirefoxWebDriver的实例,通过这个实例连接网络资源
brower=webdriver.Firefox()
#要访问的地址
url='http://www.python.org'
#.get方法会访问指定的url地址,并且webdriver会等待page完全加载,然后才将控制权返回到你的测试或者代码上。
#如果使用Ajax加载内容,WebDriver将无法判断是否完全加载
brower.get(url)
#page_source属性就是加载的文档的内容
#print(brower.page_source)
#判断Python是否在title里面,断言assert的使用方法请自行参考百度
assert 'Python' in brower.title
#webdriver提供了很多方法来访问加载的内容,我们后面会详细的讲解。这是通过element的name属性来寻找。
elem=brower.find_element_by_name('q')
#接下来我们要发送一些key了,就跟使用键盘输入一样。
#特殊的KEY我们使用Keys类来输入。
#为了安全保险,我们先将elem的内容清空掉,嘿嘿。
elem.clear()
elem.send_keys('pycon')#然后向这个element发送了pycon内容
elem.send_keys(Keys.RETURN)#回车,查询内容
#提交了页面之哦胡,我们就会得到结果,假如有的话。判断是不是返回了No results found。
assert 'No results found.' not in brower.page_source
#最终,关闭浏览器。
#h还可以使用quit方法,但是quit一般只关闭一个标签,close会关闭整个webdriver。
brower.close()
哈哈,学了这个例子,我打算自己来写一个百度的访问。
实例-Selenium操控百度搜索
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#本来官方文档是与google做的交互,我们根据国情选择百度
url='http://www.baidu.com'
browser=webdriver.Firefox()
browser.get(url)
#假如下面的elem没有找到的话,我们可以设置一下超时等待,
browser.set_page_load_timeout(10)
#browser.set_script_timeout(10)
百度的搜索框,我们可以利用Firefox得到该元素的id,class或者其他定位信息。如图片显示。
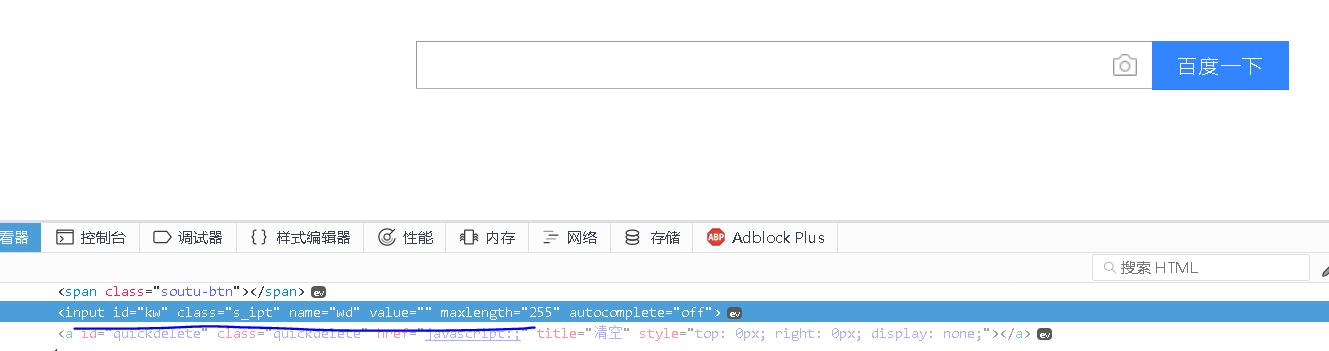
#复制搜索框的xpath表达式://*[@id="kw"]
#elem=browser.find_element_by_xpath('//*[@id="kw"]')
elem=browser.find_element_by_id('kw')
#清空该对话框的内容
elem.clear()
#在对话框内填充Python字符串。
elem.send_keys('Python')
#向该对话框传递回车键
elem.send_keys(Keys.ENTER)
#print(browser.page_source)
#如果我们不关闭browser,将会看到页面的反馈。
#browser.close()
填充表格
从百度那个例子,我们学会了如何向一个文本框填充内容,并且提交。
但这是基于该文本框具有提交的功能。
我们再来讲一下如何填充表格
Filling in forms
下面是示例代码,不一定能够运行
from selenium import webdriver
url='some_url'
browser=webdriver.Firefox()
browser.set_page_load_timeout(10)
browser.get(url)
#我们以SELECT标签为例,找到name=name的select标签,这里我们只能得到第一个。
elem=browser.find_element_by_xpath("//select[@name='name']")
#找到所有的option标签
all_options=elem.find_element_by_tag_name('option')
for option in all_options:
#使用get_attribute方法获取元素的属性
print("Value is: %s" % option.get_attribute("value"))
option.click()#提交
#WebDriver也支持一些类,比如Select,提供了一些有用的方法用于交互:
from selenium.webdriver.support.ui import Select
select=Select(browser.find_element_by_name('name'))
select.select_by_index(index=1)
select.select_by_visible_text('text')
select.select_by_value(value='value')
#同样可以取消选定所有的option
select.deselect_all()
#假如我们已经填完标签,那么就可以提交了
browser.find_element_by_id('submit').click()
拖拽页面或元素
我们可以上下滑动页面,或者在某个特定时刻移动某个元素
from selenium import webdriver
browser=webdriver.Firefox()
browser.get('someurl')
element=browser.find_element_by_name('source')
target=browser.find_element_by_name('target')
from selenium.webdriver import ActionChains
action_chains=ActionChains(browser)
action_chains.drag_and_drop(element,target).perform()
在窗口和框架之间移动
现在的webapp都是多窗口或者多框架的,所以难免涉及到切换,可以使用swich_to.window方法
#切换到目标窗口
browser.switch_to.window('targetName')
#切换到目标框架
browser.switch_to.frame('targetFrame')
#完成所有的内容后,我们要回到默认的frame上。
browser.switch_to.default_content()
弹出对话框
很简单的操作,这里就不继续介绍了,可以查看API文档
alert=browser.switch_to.alert()
导航 回退和前进功能
browser.get('someurl')
browser.forward()
browser.back()
Cookies
添加和获取Cookie的方法
cookie={'name':'foo','value':'bar'}
browser.add_cookie(cookie)
browser.get_cookies()
元素定位
定位标签元素的方法
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
假如这是我们得到的pagesource
<html>
<body>
<h1>Welcome</h1>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
<p class="content">Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
#Locating by Id
#通过元素的id来定位
#form元素我们可以这么获取
login_form=driver.find_element_by_id('loginForm')
#Locating by Name
#通过元素的name属性定位
user_input=driver.find_element_by_name('username')
password_input=driver.find_element_by_name('pasword')
#Locating by XPath
#通过元素的xpath地址来定位
#这里将一个小技巧,Firefox的调试控制台,可以邮件点击要获取的元素,会出现xpath,直接复制就可以了。
#xpath的语法可以到菜鸟教程或W3C上学一下。
login_form1 = driver.find_element_by_xpath("/html/body/form[1]")
login_form2 = driver.find_element_by_xpath("//form[1]")
login_form3 = driver.find_element_by_xpath("//form[@id='loginForm']")
#Locating Hyperlinks by Link Text
#通过链接内容获取超链接
continue_link = driver.find_element_by_link_text('Continue')
continue_link1 = driver.find_element_by_partial_link_text('Conti')
#Locating Elements by Tag Name
#通过标签名来定位
heading1 = driver.find_element_by_tag_name('h1')
#Locating Elements by Class Name
#通过类名来定位
content = driver.find_element_by_class_name('content')
#Locating Elements by CSS Selectors
#通过CSS选择器来定位
#CSS选择器的语法建议学习一下,挺好玩的
content1 = driver.find_element_by_css_selector('p.content')
等待Waits
由于目前大多数网站都使用了Ajax技术,当一个页面被浏览器加载时,页面的各种元素可能在不同的事件加载下来。
所以,如果某个元素没有第一时间加载到DOM中,我们定位的代码就会失效,抛出一个ElementNotViibleException。
因而,我们需要使用waits,插入一下时间裕量。
Selenium提供了显式和隐式的方法。
显式方法
我们可以自定义一个条件,一旦满足这个条件,才能继续我们的代码。
极端的方法是使用time.sleep(seconds)方法,指定要给固定的时间来等待。
有更简单的方法来帮忙,WebDriverWait类。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
#重要语法
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
#上面的代码会等待10秒钟,除非在10s内找到了需要的元素,要不就会抛出一个Timeout一场。
#范例2
from selenium.webdriver.support import expected_conditions as EC
#把上面的语句拆分开,这样比较直观
wait = WebDriverWait(driver, 10)
element1 = wait.until(EC.element_to_be_clickable((By.ID, 'someid')))
'''这是常用的一些EC判断方法,expected_conditions:
title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
'''
隐式等待
#比较简单,就不展开介绍了
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # seconds
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
API
http://selenium-python.readthedocs.io/api.html
如果您觉得感兴趣的话,可以添加我的微信公众号:一步一步学Python

爬虫入门【6】Selenium用法简介的更多相关文章
- selenium爬虫入门(selenium+Java+chrome)
selenium是一个开源的测试化框架,可以直接在浏览器中运行,就像用户直接操作浏览器一样,十分方便.它支持主流的浏览器:chrome,Firefox,IE等,同时它可以使用Java,python,J ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- 爬虫入门四 re
title: 爬虫入门四 re date: 2020-03-14 16:49:00 categories: python tags: crawler 正则表达式与re库 1 正则表达式简介 编译原理学 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- selenium用法详解
selenium用法详解 selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题. 模拟浏览器进行网页加载,当requests,urllib无法正常获取 ...
- Docker新手入门:基本用法
Docker新手入门:基本用法 1.Docker简介 1.1 第一本Docker书 工作中不断碰到Docker,今天终于算是正式开始学习了.在挑选系统学习Docker以及虚拟化技术的书籍时还碰到了不少 ...
随机推荐
- 跟我一起透彻理解template模板模式
#include <iostream> using namespace std; //template模式. class Base { public: void DealWhat() { ...
- 基于ruby环境搭建Redmine
环境说明 系统版本 CentOS 6.9 x86_64 软件版本 ruby 2.4.4 rails 4.2 redmine-3.4.5 Redmine是一个开源的.基于Web的项目管理和缺 ...
- K-近邻算法的Python实现 : 源代码分析
网上介绍K-近邻算法的样例非常多.其Python实现版本号基本都是来自于机器学习的入门书籍<机器学习实战>,尽管K-近邻算法本身非常easy,但非常多刚開始学习的人对其Python版本号的 ...
- google兴趣点下载工具
继上次百度兴趣点版本的发布以后,发现百度只能下载本国数据,并且数据完整度还是和google的少一些,所以本次经过钻研与解密,实现了google地图下载工具,版本的主要功能如下: 1.支持多线程下载,支 ...
- node - 写返回mime类型
何为mime类型? mime.json { ".323":"text/h323" , ".3gp":"video/3gpp&qu ...
- Linux非阻塞IO(四)非阻塞IO中connect的实现
我们为客户端的编写再做一些工作. 这次我们使用非阻塞IO实现connect函数. int connect(int sockfd, const struct sockaddr *addr, sockle ...
- UVA - 434 Matty's Blocks
题意:给你正视和側视图,求最多多少个,最少多少个 思路:贪心的思想.求最少的时候:由于能够想象着移动,尽量让两个视图的重叠.所以我们统计每一个视图不同高度的个数.然后计算.至于的话.就是每次拿正视图的 ...
- Android开发环境搭建 for windows (linux类似) 详细可参考“文件”中“Android开发环境搭建.pdf ”
ADT-Bundle for Windows 是由Google Android官方提供的集成式IDE,已经包含了Eclipse,你无需再去下载Eclipse,并且里面已集成了插件,它解决了大部分新手通 ...
- dispatch_after中时间的计算
dispatch_after中用的时间是纳秒,所以需要进行转换:desDelayInSeconds(目标时间,比如2s)* NSEC_PER_SEC double delayInSeconds = 0 ...
- 排序算法 C++代码实现
插入排序: 就像摸牌,摸一张插进去,找一个哨兵.从第二个開始,和前一个比較.小的话前移一位. #include <iostream> #include<stdlib.h> us ...