《R语言实战》读书笔记 第七章--基本统计分析
在导入数据并且将数据进行组织和初步可视化以后,需要对数据进行分布探索和两两关系分析等。主要内容有描述性统计分析、频数表和列联表、相关系数和协方差、t检验、非参数统计。
7.1描述性统计分析
7.1.1方法云集
书上说,R中的描述性统计量函数“多的尴尬”。summary函数返回最大值、最小值、上下四分位数、中位数、平均值以及因子向量和逻辑向量的频数统计。还讲了apply、sapply函数,写了峰度和偏度。fivenum函数可以返回图基五数,即最小值,下分位数,中位数,上四分位数,最大值。
扩展:
Hmisc包中的describe函数可以返回变量和观测的数量,缺失值和唯一值的数目、平均值,以及最大最小的5个数。
pastecs包中有一个stat.desc函数的函数,可以计算种类繁多的统计量。
> stat.desc(mtcars[c("mpg","cyl")])
mpg cyl
nbr.val 32.0000000 32.0000000
nbr.null 0.0000000 0.0000000
nbr.na 0.0000000 0.0000000
min 10.4000000 4.0000000
max 33.9000000 8.0000000
range 23.5000000 4.0000000
sum 642.9000000 198.0000000
median 19.2000000 6.0000000
mean 20.0906250 6.1875000
SE.mean 1.0654240 0.3157093
CI.mean.0.95 2.1729465 0.6438934
var 36.3241028 3.1895161
std.dev 6.0269481 1.7859216
coef.var 0.2999881 0.2886338
另外,psych包中也包含describe函数,能够计算更多的统计量。
> describe(mtcars[c("mpg","cyl")])
vars n mean sd median trimmed mad min max range skew kurtosis se
mpg 20.09 6.03 19.2 19.70 5.41 10.4 33.9 23.5 0.61 -0.37 1.07
cyl 6.19 1.79 6.0 6.23 2.97 4.0 8.0 4.0 -0.17 -1.76 0.32
其中,mad是绝对中位差,trimmed是截尾均值(可设置参数默认为0.1),skew是峰度、kurtosis是偏度,se是均值标准误差。其他参数比较平凡。
多说一句,Hmisc和psych包中均有describe函数,那么在调用的时候是用最晚载入的包中的函数,如果想用某个特定包中的函数,需要用Hmisc::describe()即可。
7.1.2分计算组描述统计量
本节的目的RT。在第五章曾经用aggregate函数整合数据。遗憾的是,aggregate函数只会调用均值,方差等单返回值的函数。如果想返回多个统计量,需要用到by函数:
by(data, INDICES, FUN, ..., simplify = TRUE)
#这里的data是一个矩阵或者数据框,INDICES是用来分组的因子或者因子组,
#FUN是任意函数,...是FUN的参数,simplify是是否返回简单形式。
例子:
书上的例子在现在的R中是运行不出来的,因为mean和sd不能作用于数据框了,而作用于矩阵也是先拉成向量再求均值……额,不过有一些函数还是可以用的,比如sum、range.
doBY包中的summaBy函数:
summaryBy(formula, data = parent.frame(), id = NULL, FUN = mean,
keep.names=FALSE, p2d=FALSE, order=TRUE, full.dimension=FALSE,
var.names=NULL, fun.names=NULL, ...)
#这里的formula是公式,具体形式为 var1 + var2 + var3 ~ group1 +group1...,,前面的是需要分析的数值#向量,后面的事分组向量,data是数据源,id是一个公式,这个公式的计算不必依照分组,但是也需要输#出,FUN作用的函数,其他参数是辅助吧。
注意上面的函数FUN是可以同时使用多个函数的。
describe.by函数可以返回与describe相同的统计量,并且可以进行分组,但是不能自定义函数,所以应用性貌似不强。
到这里当然可以用melt和cast函数了。作者说这种方式他常用。
7.1.3数据可视化
第6章中的有关图都可以使用。
7.2频数表和列联表
本节探究类别型变量的频数表和列联表,以及相关的独立性检验、相关性度量、图形化展示等。利用vcd包中的Arthritis数据集。
7.2.1生成频数表
创建和处理列联表的函数

第1、4个用过,其他没用过,试试。
1、一维列联表
用table函数直接加向量就行,书上用的with函数,
with(Arthritis,table(Improved))
2、二维列联表
table(A,B)
> table(Arthritis$Treatment,Arthritis$Improved) None Some Marked
Placebo
Treated xtabs(formula = ~., data = parent.frame(), subset, sparse = FALSE,
na.action, exclude = c(NA, NaN), drop.unused.levels = FALSE)
#上面的参数比较直白,要说的是第一个formula.~的右边是需要进行table的量,而左边是按照右边table#以后进行求和,可以是向量或者数值矩阵.例子:
> xtabs(ID~Treatment+Improved,data = Arthritis)
Improved
Treatment None Some Marked
Placebo
Treated
> xtabs(Age~Treatment+Improved,data = Arthritis)
Improved
Treatment None Some Marked
Placebo
Treated
> xtabs(cbind(ID,Age) ~ Treatment+Improved , data = Arthritis)
, , = ID Improved
Treatment None Some Marked
Placebo
Treated , , = Age Improved
Treatment None Some Marked
Placebo
Treated
多说一句,那么这样的做法与分组归类再求和没什么区别啊.
xtabs(~A+B,data = Arthritis) 与 table(A,B)作用一样。
margin.table 和 prop.table是对边际进行求和以及转换为比例,格式为 margin.table(table,维数),prop.table(table,维数)。
mytable <- xtabs(~Treatment+Improved,data = Arthritis)
margin.table(mytable,1)
prop.table(mytable,1)
> margin.table(mytable,1)
Treatment
Placebo Treated
43 41
> prop.table(mytable,1)
Improved
Treatment None Some Marked
Placebo 0.6744186 0.1627907 0.1627907
Treated 0.3170732 0.1707317 0.5121951
当然,prop.table可以不加维度参数,那么就是对每一个单元格求一下占所有的比例,“密度函数”吧。
下面看addmargins为表格添加边际和。
addmargins(A, margin = seq_along(dim(A)), FUN = sum, quiet = FALSE)
#上面的A是table或者数组,margin是维度,FUN可修改.
#维度为空,默认所有维度都会边际求和
addmargins(prop.table(mytable))
> addmargins(prop.table(mytable))
Improved
Treatment None Some Marked Sum
Placebo 0.34523810 0.08333333 0.08333333 0.51190476
Treated 0.15476190 0.08333333 0.25000000 0.48809524
Sum 0.50000000 0.16666667 0.33333333 1.00000000
注意,table函数默认不统计NA的个数,忘了写table函数了:
table(..., exclude = if (useNA == "no") c(NA, NaN), useNA = c("no",
"ifany", "always"), dnn = list.names(...), deparse.level = )
#...可以是向量、列表等,原则就是可以转换为factor的量,注意不能是数据框或者矩阵,否者会被#拉成向量形式成为一维table表,所以要用table(A,B)这种形式,A是行,B作为列。dnn是维度名称
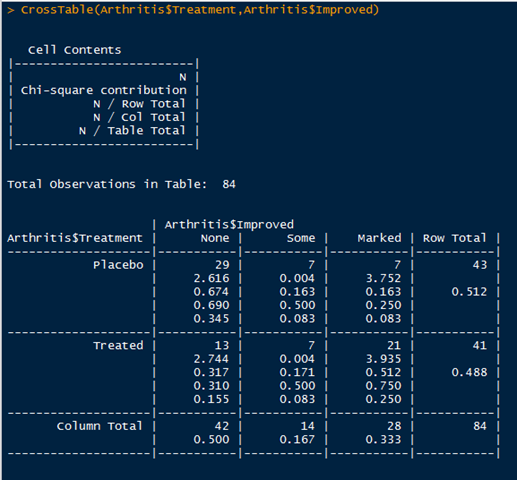
gmodels包中的CrossTable函数可以创建另一种形式的二维列联表。形式比较友好。这个函数确实比较友好,下面看一下:
CrossTable(x, y, digits=, max.width = , expected=FALSE, prop.r=TRUE, prop.c=TRUE,
prop.t=TRUE, prop.chisq=TRUE, chisq = FALSE, fisher=FALSE, mcnemar=FALSE,
resid=FALSE, sresid=FALSE, asresid=FALSE,
missing.include=FALSE,
format=c("SAS","SPSS"), dnn = NULL, ...)
#这个函数生成列联表,同时计算期望,边际百分比,进行独立性检验,计算残差,进行行列标注,输出特定风格等。
形式确实非常友好:
3、多维列联表
多维列联表可以用table、xtabs生成,ftable函数的形式更友好一些。margin.table()、prop.table()、addmargins()可以自然推广。
这里只是说一下prob.margin函数:
为了看清楚prop.margin,举个栗子: >mytable <- xtabs(~Treatment+Sex,data = Arthritis)
>ftable(prop.table(mytable))
结果为:
Sex Female Male
Treatment
Placebo 0.3809524 0.1309524
Treated 0.3214286 0.1666667 >ftable(prop.table(mytable,))
结果为:
Sex Female Male
Treatment
Placebo 0.7441860 0.2558140
Treated 0.6585366 0.3414634 >ftable(addmargins(prop.table(mytable)))
结果为:
Sex Female Male Sum
Treatment
Placebo 0.3809524 0.1309524 0.5119048
Treated 0.3214286 0.1666667 0.4880952
Sum 0.7023810 0.2976190 1.0000000 >ftable(addmargins(prop.table(mytable,)))
结果为:
Sex Female Male Sum
Treatment
Placebo 0.7441860 0.2558140 1.0000000
Treated 0.6585366 0.3414634 1.0000000
Sum 1.4027226 0.5972774 2.0000000
7.2.2独立性检验
R语言提供了多种类别型变量独立性检验的方法。本节有卡方独立性检验、Fisher精确检验和Cochran-Mantel-Haenszel检验。首先引用这里的独立性检验的知识,关于利用列联表进行独立性检验我还是第一次接触:http://www.cnblogs.com/zhangchaoyang/articles/2642032.html。
1、卡方独立性检验
可以使用chisq.test()函数进行独立性检验,下面是一个例子:
>library(vcd)
>mytable <- xtabs(~Treatment+Improved,data = Arthritis)
>chisq.test(mytable)
结果为: Pearson's Chi-squared test data: mytable
X-squared = 13.055, df = , p-value =
0.001463
我们知道,P值(P value)就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。总之,P值越小,表明结果越显著。以上,由于 p < 0.01, 那么就拒绝原假设(独立),即说明两者是不独立的。
下面:
>mytable <- xtabs(~Improved+Sex,data = Arthritis)
>chisq.test(mytable)
结果为:
Pearson's Chi-squared test
data: mytable
X-squared = 4.8407, df = , p-value = 0.08889
Warning message:
In chisq.test(mytable) : Chi-squared近似算法有可能不准
卡方检验的条件:所有类别的期望频数都要大于等于5。本例中:
> mytable
Sex
Improved Female Male
None
Some
Marked
有一个2,所以会有警告。
2、Fisher精确检验
关于Fisher精确检验,原假设是:在边界固定的列联表中行和列是相互独立的。适用于频数小的列联表:
>mytable <- xtabs(~Improved+Sex,data = Arthritis)
>fisher.test(mytable) 结果: Fisher's Exact Test for Count Data data: mytable
p-value = 0.1094
alternative hypothesis: two.sided 换句话说,应该是接受原假设的。
3、Cochran-Mantel-Haenszel检验
这个名字好长。没找到什么好的讲解,用课本上的一句话来说就好了:其原假设是,两个名义变量在第三个变量的每一层中都是条件独立的。可以用mantelhaen.test()函数进行检验,例子:
> mytable <- xtabs(~Treatment+Improved+Sex,data = Arthritis)
> mantelhaen.test(mytable) Cochran-Mantel-Haenszel test data: mytable
Cochran-Mantel-Haenszel M^ = 14.632, df =
, p-value = 0.0006647
上面的例子中,由于p值很小,说明患者接受治疗与得到改善在性别的每一水平下是不独立的(即接受治疗会得到改善)。M^2还是不知什么意思,估计类似卡方值。下面的地址:http://bbs.druggcp.net/blog-5612-10109.html,稍微讲了一些基本原理。
7.2.3相关性的度量
本节讲了几个衡量相关性强弱的“系数”:phi系数、列联系数、Cramer's V系数。关于这几个系数,下面的内容从http://www.cnblogs.com/xmdata-analysis/p/4670955.html得到:
下面是引用,原文地址:http://www.cnblogs.com/xmdata-analysis/p/4670955.html
.多个变量不同属性间相关性大小的计算
在列联表中的分类数据可能为有序分类变量和无序分类变量,二者计算相关系数是不一样的,我们暂且分为三种情况:.无序-无序 .有序-有序 .无序-有序
首先来看无序-无序的相关性大小计算:
φ-Phi系数:
用于描述2×2列联表数据相关程度最常用的一种相关系数,因为对于2×2列联表,φ系数可以保证在0-1之间,这样比较直观,方便比较,数值越大相关性越强。在相关度量法中不采用拟合优度卡方是因为拟合优度卡方过分依赖于样本数大小。将卡方除以n针对样本量n进行修正就是φ系数。
当列联表行列数大于2×2的时候,φ的取值没有上限,这导致系数之间无法比较,这是φ系数只能用于2×2列联表的原因。
对于一个具体的2×2维列联表
X1 X2
Y1 a b
Y2 c d
 C系数,也称列联系数
用于描述多于2×2列联表数据相关程度的一种相关系数,当列联表多于2×2的时候,φ系数不能保证在0-1之间,为了让多于2×2的列联表的相关系数在0-1之间,person建议使用C系数,也称为列联系数
C系数,也称列联系数
用于描述多于2×2列联表数据相关程度的一种相关系数,当列联表多于2×2的时候,φ系数不能保证在0-1之间,为了让多于2×2的列联表的相关系数在0-1之间,person建议使用C系数,也称为列联系数
 列联系数在0-1之间,数值大小取决于列联表的行数和列数,数值越大相关性越强,但是C系数无法达到1,这是C系数的一个缺点,因为作为一个相关系数,他应该具有两变量完全相关,相关系数=1的特点。
另有一些人不建议在小于5×5的列联表中使用C系数
Cramer's V 系数
V系数的在0-1之间,它修正了φ系数没有上限和V系数无法达到1的不足,数值越大相关性越强,当变量X和Y完全不相关时,V=,当两个变量完全相关时,则V=。
当列联表是2×2时,V=φ
列联系数在0-1之间,数值大小取决于列联表的行数和列数,数值越大相关性越强,但是C系数无法达到1,这是C系数的一个缺点,因为作为一个相关系数,他应该具有两变量完全相关,相关系数=1的特点。
另有一些人不建议在小于5×5的列联表中使用C系数
Cramer's V 系数
V系数的在0-1之间,它修正了φ系数没有上限和V系数无法达到1的不足,数值越大相关性越强,当变量X和Y完全不相关时,V=,当两个变量完全相关时,则V=。
当列联表是2×2时,V=φ
 φ系数、C系数、V系数之间的关系
.同一个列联表,三个系数会不同
.在对不同列联表变量之间的相关程度进行比较时,要确保使用同一种系数,并且两个列联表之间的行列数要相同
上述三个相关系数都是基于卡方的度量系数,并没有直观的有吸引力的解释。即使它们取值范围在0和1之间,也很难说0.49这么一个数值反映了什么关系。很可能这个关系是微弱的,但是没有可以操作的标准来评估他的大小。这类量度系数最早是作为通常的相关系数的近似值发展起来的,现在已经被更多的易于解释的量度系数所补充。
为了避免以卡方为基础的量度系数的弱点,统计学家已经发展出各种其他方法,其中最流行的就是减少误差比例量度法(Proportional-reduction-in-error measures,简称PRE)
PRE数值的意义就是用一个现象(如变量X)来预测另一个现象(如变量Y)时能够减除百分之几的误差。
φ系数、C系数、V系数之间的关系
.同一个列联表,三个系数会不同
.在对不同列联表变量之间的相关程度进行比较时,要确保使用同一种系数,并且两个列联表之间的行列数要相同
上述三个相关系数都是基于卡方的度量系数,并没有直观的有吸引力的解释。即使它们取值范围在0和1之间,也很难说0.49这么一个数值反映了什么关系。很可能这个关系是微弱的,但是没有可以操作的标准来评估他的大小。这类量度系数最早是作为通常的相关系数的近似值发展起来的,现在已经被更多的易于解释的量度系数所补充。
为了避免以卡方为基础的量度系数的弱点,统计学家已经发展出各种其他方法,其中最流行的就是减少误差比例量度法(Proportional-reduction-in-error measures,简称PRE)
PRE数值的意义就是用一个现象(如变量X)来预测另一个现象(如变量Y)时能够减除百分之几的误差。
PRE=(E1—E2)/E1
E1:当不知道X变量去估计Y变量时所产生的误差(全部误差)
E2:知道X变量再去估计Y变量产生的误差
E1—E2为剩余的误差
vcd()包中的assocstats()函数可以生成这几个“系数”,这几个系数越大,说明相关性越强,例子:
> mytable <- xtabs(~Treatment+Improved,data = Arthritis)
> assocstats(mytable)
X^ df P(> X^)
Likelihood Ratio 13.530 0.0011536
Pearson 13.055 0.0014626 Phi-Coefficient : NA
Contingency Coeff.: 0.367
Cramer's V : 0.394
奇怪的是这里的Phi系数为何是NA?。。。书上的不是NA 是 0.394--知道了:Phi系数只能是2x2的才可以,现在的mytable是2x3。那么,就换一个例子喽:
> mytable <- xtabs(~Treatment+Sex,data = Arthritis)
> assocstats(mytable)
X^ df P(> X^)
Likelihood Ratio 0.73748 0.39047
Pearson 0.73653 0.39078 Phi-Coefficient : 0.094
Contingency Coeff.: 0.093
Cramer's V : 0.094
这回对了!
《R语言实战》读书笔记 第七章--基本统计分析的更多相关文章
- R语言实战读书笔记(二)创建数据集
2.2.2 矩阵 matrix(vector,nrow,ncol,byrow,dimnames,char_vector_rownames,char_vector_colnames) 其中: byrow ...
- R语言实战读书笔记(三)图形初阶
这篇简直是白写了,写到后面发现ggplot明显更好用 3.1 使用图形 attach(mtcars)plot(wt, mpg) #x轴wt,y轴pgabline(lm(mpg ~ wt)) #画线拟合 ...
- R语言实战读书笔记(七)基本统计分析
summary() sapply(x,fun,options):对数据框或矩阵中的每一个向量进行统计 mean sd:标准差 var:方差 min: max: median: length: rang ...
- R语言实战读书笔记1—语言介绍
第一章 语言介绍 1.1 典型的数据分析步骤 1.2 获取帮助 help.start() help("which") help.search("which") ...
- R语言实战读书笔记2—创建数据集(上)
第二章 创建数据集 2.1 数据集的概念 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和变量(variable) ,数据库分析师则称其为记录(record)和字 ...
- R语言实战读书笔记(八)回归
简单线性:用一个量化验的解释变量预测一个量化的响应变量 多项式:用一个量化的解决变量预测一个量化的响应变量,模型的关系是n阶多项式 多元线性:用两个或多个量化的解释变量预测一个量化的响应变量 多变量: ...
- R语言实战读书笔记(五)高级数据管理
5.2.1 数据函数 abs: sqrt: ceiling:求不小于x的最小整数 floor:求不大于x的最大整数 trunc:向0的方向截取x中的整数部分 round:将x舍入为指定位的小数 sig ...
- R语言实战读书笔记(四)基本数据管理
4.2 创建新变量 几个运算符: ^或**:求幂 x%%y:求余 x%/%y:整数除 4.3 变量的重编码 with(): within():可以修改数据框 4.4 变量重命名 包reshape中有个 ...
- R语言实战读书笔记(一)R语言介绍
1.3.3 工作空间 getwd():显示当前工作目录 setwd():设置当前工作目录 ls():列出当前工作空间中的对象 rm():删除对象 1.3.4 输入与输出 source():执行脚本
随机推荐
- Spring Security 简介
本文引自:https://blog.csdn.net/xlecho/article/details/80026527 在 Web 应用开发中,安全一直是非常重要的一个方面.安全虽然属于应用的非功能性需 ...
- 彻底弄懂session,cookie,token
session,cookie和token究竟是什么 简述 我在写之前看了很多篇session,cookie的文章,有的人说先有了cookie,后有了session.也有人说先有session,后有co ...
- ABAP自定义截取字符串长度函数
SAP 中strlen()只能计算字符串的个数,不能计算含有中文字符串的长度,如字符串“SAP大波霸”,strlen('SAP大波霸') = 6,其实真实长度为3+3*2 = 9.我们可以通过cl_a ...
- python向多个邮箱发邮件--注意接收是垃圾邮件
群发邮件注意:三处标红的地方 # -*- coding: UTF-8 -*- import smtplib from email.mime.text import MIMEText from emai ...
- Androd安全——混淆技术完全解析
.前言 在上一篇Androd安全--反编译技术完全解析中介绍了反编译方面的知识,因此我们认识到为了安全我们需要对代码进行混淆. 混淆代码并不是让代码无法被反编译,而是将代码中的类.方法.变量等信息进行 ...
- mysql安装与基本管理,mysql密码破解
一.MySQL介绍 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司.MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是 ...
- 理解Queue队列中join()与task_done()的关系
在网上大多关于join()与task_done()的结束原话是这样的: Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号 ...
- [转]ANDROID JNI之JAVA域与c域的互操作
本文讲述AndroidJava域与C域互操作:Java域调用c域的函数:c域访问Java域的属性和方法:c域生成的对象的保存与使用.重点讲解c域如何访问Java域. 虽然AndroidJNI实现中,c ...
- iOS系统信息集合
在项目开发的时候,经常需要用到某些系统信息,比如手机型号(5s,6,6p), 操作系统版本(8.0 or 9.3), 当前网络类型(3/4g, wifi)等信息. 有了这些信息, 可以在出了某些bug ...
- 《数据结构》C++代码 栈与队列
线性表中,先进先出的叫队列,先进后出的叫栈.队列常用于BFS,而在函数递归层数过高时,需要手动实现递归过程,这时候便需要写一个“手动栈”. 有时候,我们会有大量数据频繁出入队列,但同时存在其内的元素却 ...