Python基础-字符编码与转码
***了解计算机的底层原理***
Python全栈开发之Python基础-字符编码与转码
需知:
1.在python2默认编码是ASCII, python3里默认是utf-8
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-8就是unicode
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
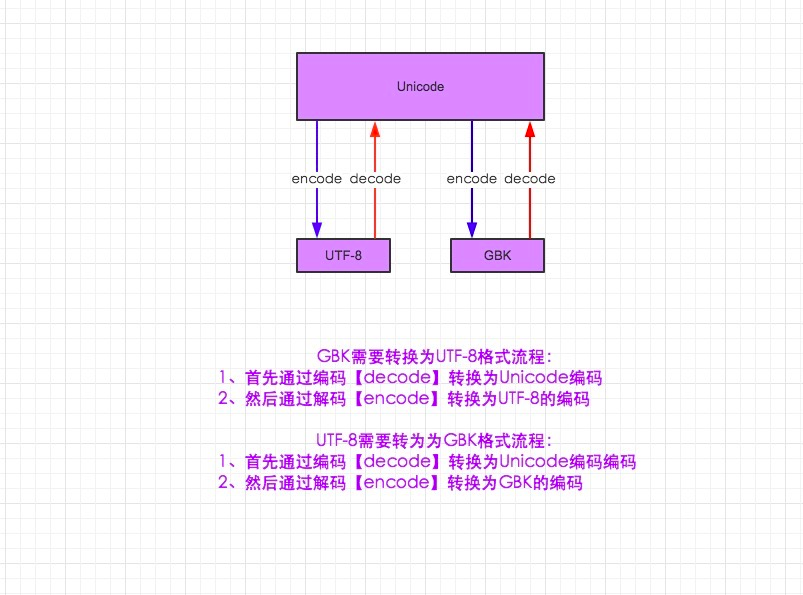
一、python2
- py2里默认编码是ascii
- 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
- 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
- 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk
二、python3
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我操,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。
- 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名,没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'\xe4\xbd\xa0\xe5\xa5\xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
最后,编码is a piece of fucking shit, noboby likes it.
ps:
python2 的用法
gbk转成utf-8
1 [root@python2 scripts]# cat encode.py
2 #!/usr/bin/env python
3 # -*- coding:utf-8 -*-
4 #Author: nulige
5
6 import sys
7 print(sys.getdefaultencoding())
8
9 s = "你好"
10 s_to_unicode = s.decode("utf-8")
11 print(s_to_unicode)
12 s_to_gbk = s_to_unicode.encode("gbk")
13 print(s_to_gbk)
14
15 gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")
16 print(gbk_to_utf8)
执行结果:
1 [root@python2 scripts]# python encode.py
2 ascii #系统默认编码
3 你好
4 ?oí
5 你好 #gbk转成utf-8
utf-8是unicode的扩展集
[root@python2 scripts]# cat encode.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: nulige import sys
print(sys.getdefaultencoding()) s = u"你好"
print(s) s_to_unicode = s.decode("utf-8")
print(s_to_unicode)
s_to_gbk = s_to_unicode.encode("gbk")
print(s_to_gbk) gbk_to_utf8= s_to_gbk.decode("gbk").encode("utf-8")
print(gbk_to_utf8)
执行结果:
[root@python2 scripts]# python encode.py
ascii
你好 #utf-8是unicode的扩展集,所以这里也是可以显示中文的
Traceback (most recent call last):
File "encode.py", line 11, in <module>
s_to_unicode = s.decode("utf-8")
File "/usr/local/lib/python2.7/encodings/utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
gbk转成utf8
[root@python2 scripts]# cat encode.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: nulige import sys
print(sys.getdefaultencoding()) s = u"你好"
print(s) s_to_gbk = s.encode("gbk")
print(s_to_gbk) gbk_to_utf8= s_to_gbk.decode("gbk").encode("utf-8")
print(gbk_to_utf8)
执行结果:
1 [root@python2 scripts]# python encode.py
2 ascii
3 你好
4 ?oí
5 你好
python3
1 #!/usr/bin/env python
2 #Author: nulige
3
4 import sys
5 print(sys.getdefaultencoding())
6
7 s = "你哈" #默认是utf-8
8 s_gbk = s.encode("gbk") #utf-8转成gbk
9
10 print(s_gbk)
11 print(s.encode())
执行结果:
1 utf-8 #python默认是utf-8
2 b'\xc4\xe3\xb9\xfe' #utf-8转成gbk
3 b'\xe4\xbd\xa0\xe5\x93\x88'
1 #!/usr/bin/env python
2 #Author: nulige
3
4 import sys
5 print(sys.getdefaultencoding())
6
7 s = "你哈"
8 s_gbk = s.encode("gbk")
9
10 print(s_gbk)
11 print(s.encode())
12
13 gbk_to_utf8 = s_gbk.decode("gbk").encode("utf-8") #gbk转成utf-8
14 print("utf8",gbk_to_utf8)
执行结果:
1 utf-8
2 b'\xc4\xe3\xb9\xfe'
3 b'\xe4\xbd\xa0\xe5\x93\x88'
4 utf8 b'\xe4\xbd\xa0\xe5\x93\x88'
总结
把PyCharm字符编码调成gbk
#!/usr/bin/env python
# -*-coding:gbk-*-
#Author: nulige #不同字符编码要先转成uncode
import sys
print(sys.getdefaultencoding()) s = '你好' #默认uncode
print(s.encode("gbk"))
print(s.encode("utf-8"))
print(s.encode("utf-8").decode("utf-8").encode("gb2312"))
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312"))
执行结果:
1 utf-8
2 b'\xc4\xe3\xba\xc3'
3 b'\xe4\xbd\xa0\xe5\xa5\xbd'
4 b'\xc4\xe3\xba\xc3'
5 你好
Python基础-字符编码与转码的更多相关文章
- Python中字符编码及转码
python 字符编码及转码 python 默认编码 python 2.X 默认的字符编码是ASCII, 默认的文件编码也是ASCII python 3.X 默认的字符编码是unicode,默认的文件 ...
- python基础-----字符编码
1.ASCII ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现 ...
- 第2章 Python基础-字符编码&数据类型 字符编码&字符串 练习题
1.简述位.字节的关系 位(bit)是计算机中最小的表示单元,数据传输是以“位”为单位的,1bit缩写为1b 字节(Byte)是计算机中最小的存储单位,1Byte缩写为1B 8bit = 1Byte ...
- Python基础(字符编码与文件处理)
一.了解字符编码的知识储备 1.计算机基础知识(三副图) 2.文本编辑器存取文件的原理(notepad++,Pycharm,word) 打开编辑器就启动了一个进程,是在内存中运行的,所以在编辑器写的内 ...
- python基础--字符编码以及文件操作
字符编码: 1.运行程序的三个核心硬件:cpu.内存.硬盘 任何一个程序要是想要运算,肯定是先从硬盘加载到当前的内存中,然后cpu根据指定的指令去执行操作 2.python解释器运行一个py文件的步骤 ...
- python(字符编码与转码)
一.字符编码演变史 二进制(0 1) """ 算机中的所有数据,不论是文字.图片.视频.还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的,再说简单点 ...
- python之字符编码与转码
说起python编码,真是句句心酸,今天终于是,终于梳理清楚了,下面我们就来一起揭开py编码的真相吧! 一,什么是编码? 其实基本概念很简单.我们都知道消息,那么消息就是人类所能理解的,简单易懂的存在 ...
- 第2章 Python基础-字符编码&数据类型 列表&元祖 练习题
1.创建一个空列表,命名为names,往里面添加old_driver,rain,jack,shanshan,peiqi,black_girl元素 names = ["old_driver&q ...
- 第2章 Python基础-字符编码&数据类型 购物车&多级菜单 作业
作业 一.三级菜单 数据结构: menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, ...
随机推荐
- Listview的使用
最近一个多月忙着使用新的技术来做项目,现在项目上线了,嗯,发现android有些生疏了,所以今天特地写了这一篇博客来相信的讲解一些基础知识,同事呢,也可以让我温故知新一下.进入正题. 什么是listv ...
- PHP无限极分类
当你学习php无限极分类的时候,大家都觉得一个字“难”我也觉得很难,所以,现在都还在看,因为工作要用到,所以,就必须得研究研究. 到网上一搜php无限极分类,很多,但好多都是一个,并且,写的很乱, ...
- hdu4632 Palindrome subsequence (区间dp)
题目链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=4632 题意:求回文串子串的的个数. 思路:看转移方程就能理解了. dp[i][j] 表示区 ...
- dedecms 按权重排序不准或BUG的处理方法
dede:list 的方法 1.找到"根目录\include\arc.listview.class.php"文件. 2.修改代码:在文件第727行处添加按weight排序判断代码( ...
- NOIP2015D1
好像来的有点晚,但我的确现在刚做这套题 T1神奇的幻方 题目描述 幻方是一种很神奇的N*N矩阵:它由数字1,2,3,……,N*N构成,且每行.每列及两条对角线上的数字之和都相同. 当N为奇数时,我们可 ...
- SRM 618 DIV1 500
非常棒的组合问题,看了好一会,无想法.... 有很多做法,我发现不考虑顺序的最好理解,也最好写. 结果一定是两种形式 A....A dp[n-1] A...A...A sgma(dp[j]*dp[ ...
- ZeroMQ接口函数之 :zmq_pgm – ØMQ 使用PGM 进行可靠的多路传输
ZeroMQ API 目录 :http://www.cnblogs.com/fengbohello/p/4230135.html ——————————————————————————————————— ...
- php正则获取html图片标签信息(采集图片)
php获取html图片标签信息(采集图片),实现图片采集及其他功能,带代码如下: <?php $str="<img src='./a.jpg'/>111111<img ...
- 试验添加RAC(ORA10G)节点
删除一个RAC节点:http://www.cnblogs.com/myrunning/p/4548624.html 1.1安装CLUSTERWARE软件 备注:在做添加删除节点时,10G版本一定要注意 ...
- F-并查集
Problem F Time Limit : 2000/1000ms (Java/Other) Memory Limit : 60000/30000K (Java/Other) Total Sub ...