SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
说说复合索引
写索引的博客太多了,一直不想动手写,有一下两个原因:
一是觉得有炒剩饭的嫌疑,有兄弟曾说:索引吗,只要在查询条件上建索引就行了,真的可以这么暴力吗?
二来觉得,索引是个非常大的话题,很难概括出所有的情况,你不整出点新意来,倒是有抄袭照搬的嫌疑
既然写了,就写一点稍微不一样的东西出来,
好了,废话打住,开搞
搭建测试环境:
创建一张表,模拟实际业务中的一个表,往里面填入数据,
时间字段上,相对按照时间均匀地填充,其他字段以GUID填充

Create table BusinessInfoTable
(
BuniessCode1 varchar(50),
BuniessCode2 varchar(50),
BuniessCode3 varchar(50),
BuniessCode4 varchar(50),
BuniessStatus1 tinyint,
BuniessStatus2 tinyint,
BuniessDateTime1 Datetime,
BuniessDateTime2 Datetime,
OtherColumn1 varchar(50),
OtherColumn2 varchar(50),
OtherColumn3 varchar(50)
) declare @i int=0
while @i<1000000
begin
insert into BusinessInfoTable
values
(
NEWID(),NEWID(),NEWID(),NEWID(),RAND()*100,RAND()*100,
DATEADD(MI,@i,GETDATE()),DATEADD(MI,@i,GETDATE()),NEWID(),NEWID(),NEWID()
)
set @i=@i+1
end
现在有这么一个查询(实际上查询远比这个复杂,我简化一点,不要说我刻意造环境)
select OtherColumn2,
BuniessStatus1,
BuniessStatus2,
BuniessDateTime1,
BuniessDateTime2
from BusinessInfoTable
where BuniessDateTime1 between '2016-6-21' and '2016-6-28'
and BuniessDateTime2 between '2016-6-21' and '2016-6-28'
and BuniessStatus1 = 55
and BuniessStatus2 = 66
郑重的说明一点:
暂时不考虑聚集索引,毕竟一个表上只能有一个聚集索引,
别人也不是傻子,不会轻易去建聚集索引,聚集索引早被占用了
既然被占用了,我的原则是一般不去动别人现有的东西的,比如别人建了聚集索引,你给人家删了,根据自己的情况建聚集索引
这不是找骂么
有经验的你一定考虑符合索引了,同时考虑到为避免Key Lookup导致的书签查找,我们把查询索要的OtherColumn2列include进来
比如这样
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable
(BuniessStatus1,BuniessStatus2,BuniessDateTime1,BuniessDateTime2)
INCLUDE(OtherColumn2)
或者这样,只是索引列顺序不一样
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable
(BuniessDateTime1,BuniessDateTime2,BuniessStatus1,BuniessStatus2)
INCLUDE(OtherColumn2)
当然可以随意调整四个列的顺序,我就不过多地做演示了,有兴趣的自己试
这里的前导列的顺序并不会影响到索引的使用,查询的时候都是非聚集索引Seek,绝对的
那么问题来了,完全一样的查询条件,结果一样,使用不同的索引,索引的区别仅仅是列顺序不一样,其代价一样吗,先猜测一下,有区别吗?
同样查询,使用不同索引的结果(分别是上面的IDX_1和IDX_2):
下面看图说话
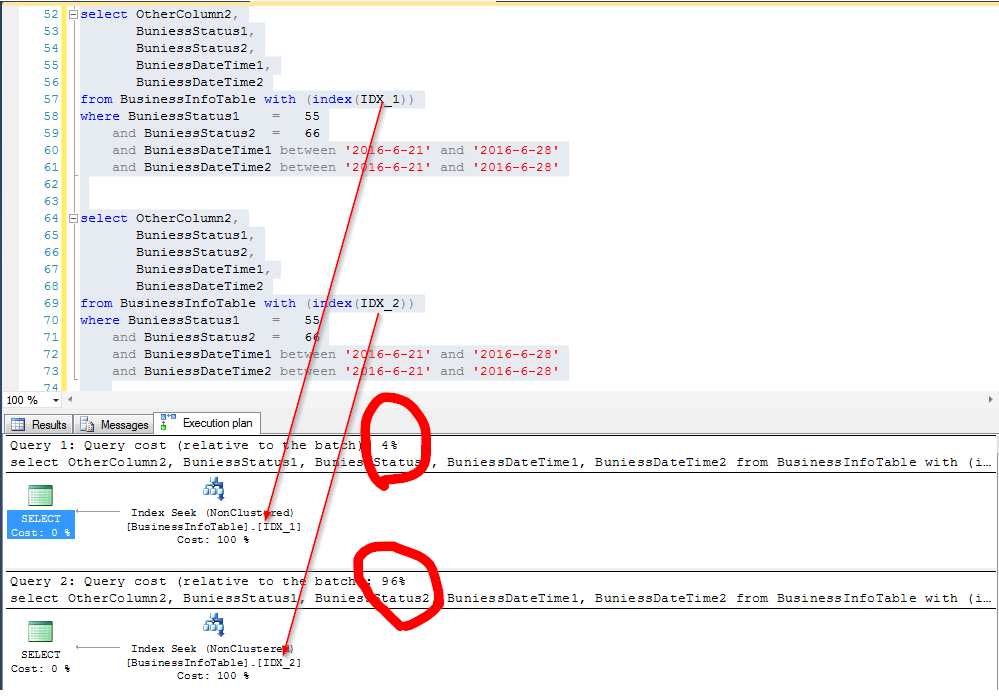
看看IO情况
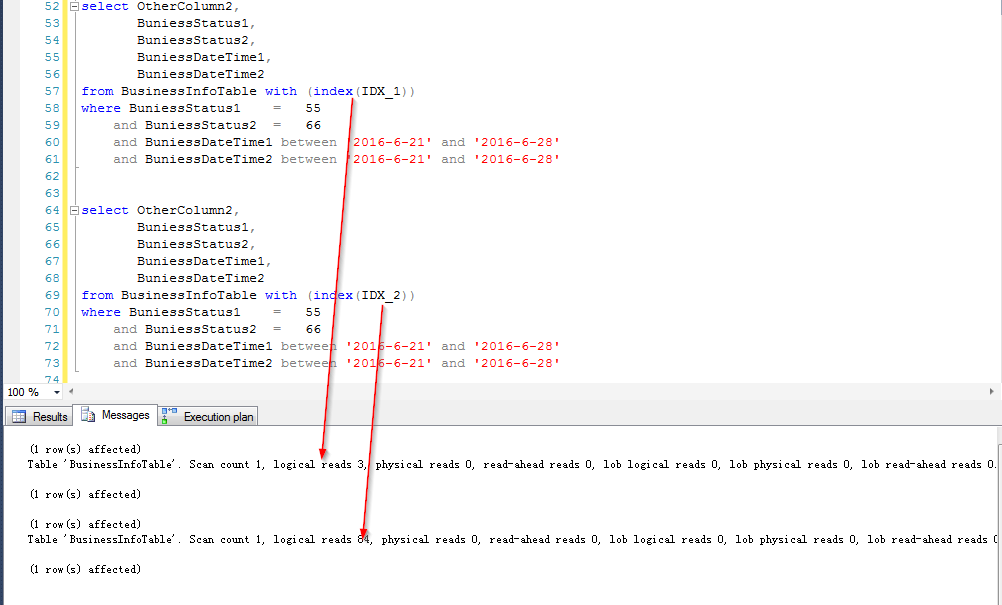
原因分析
看来是有点差别吧,好似乎这个差别还真不小(以往写文章,我测试环境弄不好,对比出来的效果不明显,感觉没啥说服力,这次对比还是比较明显的)
究竟原因在何?
索引是以平衡树(B树)的方式存在的,复合索引的列的顺序决定了B树的信息的存储的顺序
如果是以BuniessStatus1列为前导列,因为BuniessStatus1分布的范围(相对)较小,
这样在查询的时候通过BuniessStatus1=55就可以过滤出来一个比较小的结果集,后面依次用其他条件过滤就相对较快了
比如BuniessStatus1=55过滤出来符合条件的数据有5条,
加上BuniessStatus2 BuniessDateTime1 BuniessDateTime2 这三个条件再过滤,出来一条数据。
如果BuniessDateTime1 是索引的前导列,用BuniessDateTime1 between '2016-6-21' and '2016-6-28'过滤
可能会有10000条数据,然后依次再用 BuniessDateTime2,BuniessStatus1, BuniessStatus2过滤
最后也只有一条符合条件的数据。
差别就在于:一开始的过滤条件,决定了查询多少page初步确定满足条件的数据,再进一步的进行过滤
如果最开始就相对精确地确定了满足查询条件的数据范围,后面可以通过相对较小的代价来最终确认出满足条件的数据
如果最开始相对模糊地却确定了满足查询条件的数据范围,那么这个过程的代价就相对比较大,虽然后面通过每一个条件的过,结果是一样的
当然这种索引的建立跟数据分布有关,
但是,我没有下结论说,复合索引一定要按照什么什么顺序来是最好的
还是那句话:具体问题具体分析,避免经验主义,没有一刀切的手段可以解决所有的问题。
SQL Server创建复合索引时,复合索引列顺序对查询的性能影响的更多相关文章
- SQL Server 创建表 添加主键 添加列常用SQL语句
--删除主键 alter table 表名 drop constraint 主键名 --添加主键 alter table 表名 add constraint 主键名 primary key(字段名1, ...
- SQL Server 创建表 添加主键 添加列常用SQL语句【转】
--删除主键alter table 表名 drop constraint 主键名--添加主键alter table 表名 add constraint 主键名 primary key(字段名1,字段名 ...
- SQL Server创建表超出行最大限制解决方法
问题的现象在创建表A的时候,出现“信息 511,级别 16,状态 1,第 5 行 无法创建大小为 的行,该值大于允许的最大值 8060.”的信息提示.很奇怪,网上查了一下,是因为要插入表的数据类型的 ...
- SQL Server 创建索引方法
转自 <SQL Server 创建索引的 5 种方法> 地址:https://www.cnblogs.com/JiangLe/p/4007091.html 前期准备: create tab ...
- SQL Server创建索引
原文:SQL Server创建索引 什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的 ...
- SQL Server 2005 中的分区表和索引
SQL Server 2005 中的分区表和索引 SQL Server 2005 69(共 83)对本文的评价是有帮助 - 评价此主题 发布日期 : 3/24/2005 | 更新 ...
- SQL Server调优系列基础篇 - 索引运算总结
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server 调优系列基础篇 - 索引运算总结
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server的唯一键和唯一索引会将空值(NULL)也算作重复值
我们先在SQL Server数据库中,建立一张Students表: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, ) NULL, [Age] ...
随机推荐
- Git self-learning
---恢复内容开始--- 使用后的总结 git config --global user.name "" #设置和查看用户名git config --global user.ema ...
- linux dns 配置
今天线上出现一个bug,图片上传失败. 经过排查发现,上传图片接口调用失败,ping 域名提示 unknow host,ping IP正常. 猜想可能是dns的问题.解决过程如下: /etc 下没有 ...
- OC中property的有关属性
property的有关属性: (1)readwrite是可读可写特征:需要生成getter方法和setter方法: (2)readonly是只读特性只会生成getter方法不会生成setter方法: ...
- eclipse 最全快捷键 分享快乐与便捷<转发的>
Ctrl+1 快速修复(最经典的快捷键,就不用多说了) Ctrl+D: 删除当前行 Ctrl+Alt+↓ 复制当前行到下一行(复制增加) Ctrl+Alt+↑ 复制当前行到上一行(复制增加) Alt ...
- 浅析tomcat nio 配置
[尊重原创文章摘自:http://blog.csdn.net/yaerfeng/article/details/7679740] tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成 ...
- 为 Linux 应用程序编写 DLL[转]
自:http://www.ibm.com/developerworks/cn/linux/sdk/dll/index.html 在仅仅只会编写插件的时候为什么要编写整个应用程序? 插件和 DLL 通常 ...
- Linux内核分析 第二周
Linux内核分析——完成一个简单的时间片轮转多道程序内核代码 张潇月+<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-100 ...
- python几个重要的模块备忘
一:模块使用方法 二:时间模块time 三:系统接口模块os和sys 四:数据保存的几个模块json,pickle,xml,configparse 五:数据复制移动模块shutil 六:日志模块log ...
- 块级格式化上下文(block formatting context)
在CSS2.1中,有三种定位方案--普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inline元素水平排列,直到行被占满后换行,block元素则被渲染为完整的一行,除非指定,所有元素 ...
- 照片元数据信息以及在照片中写入gps信息
/// 照片元数据编码 在下面的文章里,可以看到图片所有的元数据定义信息 https://msdn.microsoft.com/zh-cn/library/system.drawing.imaging ...