Solr:文本分析
文本分析时搜索引擎的核心工作之一,对文本包含许多处理步骤,比如:分词、大写转小写、词干化、同义词转化等。简单的说,文本分析就说将一个文本字段的值转为一个一个的token,然后被保存到Lucene的索引结构中被将来搜索用。当然,文本分析不仅在建立索引时有用,在查询时对对所输入的查询串也一样可以进行文本分析。在 Solr Schema设计 中我们介绍了许多Solr中的字段类型,其中最重要的是solr.TextField,这个类型可以进行分析器配置来进行文本分析。
接下来我们先来说说什么是分析器。
分析器
<fieldType name="nametext" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.WhitespaceAnalyzer"/>
</fieldType>
<fieldType name="nametext" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
</analyzer>
</fieldType>
现在我们来看下Solr示例Schema配置中的text_en_splitting字段类型的定义,看看它用了哪些分析组件。
<!-- A text field with defaults appropriate for English, plus
aggressive word-splitting and autophrase features enabled.
This field is just like text_en, except it adds
WordDelimiterFilter to enable splitting and matching of
words on case-change, alpha numeric boundaries, and
non-alphanumeric chars. This means certain compound word
cases will work, for example query "wi fi" will match
document "WiFi" or "wi-fi".
-->
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<!--<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>-->
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
Type属性可以指定为index或是query值,分别表示是索引时用的分析器,和查询时所用的分析器。如果在索引和查询时使用相同的分析器,你可以不指定type属性值。
分析器的配置中可以选用一个或多个字符过滤器(character filter),字符过滤器是对原始文本进行字符流级别的操作。它通常可以用于大小写转化,去除字母上标等等。在字符过滤器之后是分词器(Tokenizer),它是必须要配置的。分析器会使用分词器将字符流切分成词元(Token)系列,通常用在空格处切分这种简单的算法。后面的步骤是可选的,比如token过滤器(Token Filter)会对token进行许多种操作,最后产生的词元会被称为词(Term),即用于Lucene实际索引和查询的单位。
最后,我有必须对autoGeneratePhraseQueries布尔属性补充两句,这个属性只能用于文本域。如果在查询文本分析时产生了多个词元,比如Wi-Fi分词为Wi和Fi,那么默认情况下它们只是两个不同的搜索词,它们没有位置上的关系。但如果autoGeneratePhraseQueries被设置,那么这两个词元就构造了一个词组查询,即“WiFi”,所以索引中“WiFi”必须相邻才能被查询到。在新Solr版本中,默认它被设置为false。我不建议使用它。
在Admin上对字段进行分析
在我们深入特定分析组件的细节之前,有必要去熟悉Solr的分析页面,它是一个很好的实验和查错工具,绝对不容错过。你将会用它来验证不同的分析配置,来找到你最想要的效果,你还可以用它来找到你认为应该会匹配的查询为什么没有匹配。在Solr的管理页面,你可以看到一个名为[Analysis]的链接,你进入后,会看到下面的界面。
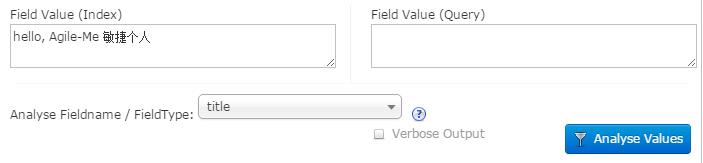
界面上的第一个选项是必选的,你可选择直接通过字段类型名称来选择类型,你也可以间接地通过一个字段的名字来选择自端类型。在上面的示例中,我选择了title字段
通过Schema Browser可以看到这个字段类型是 text_general
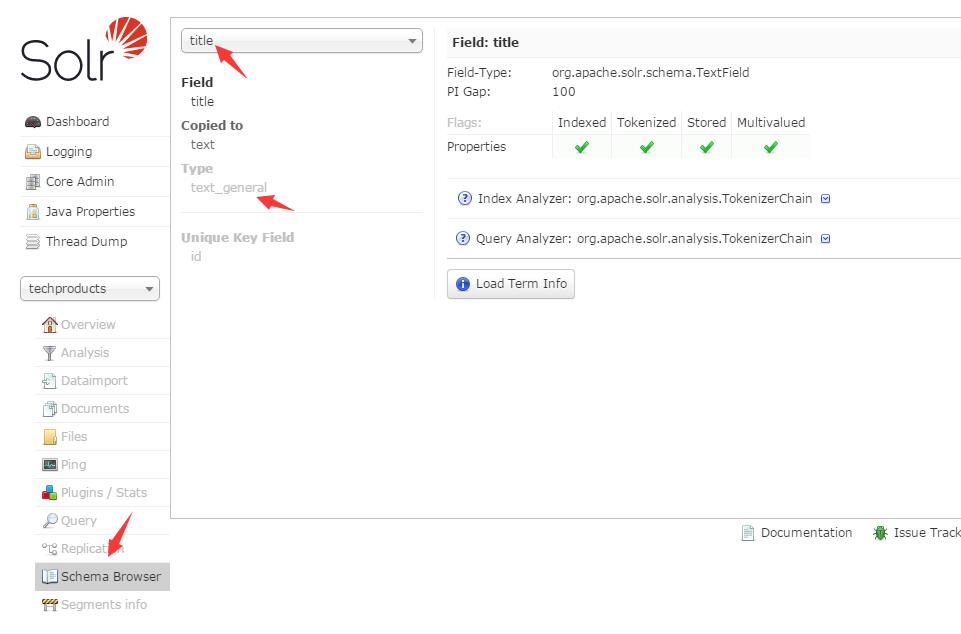
点击灰色的 text_general,可以看到这个字段的分析器中定义的分词器和过滤器
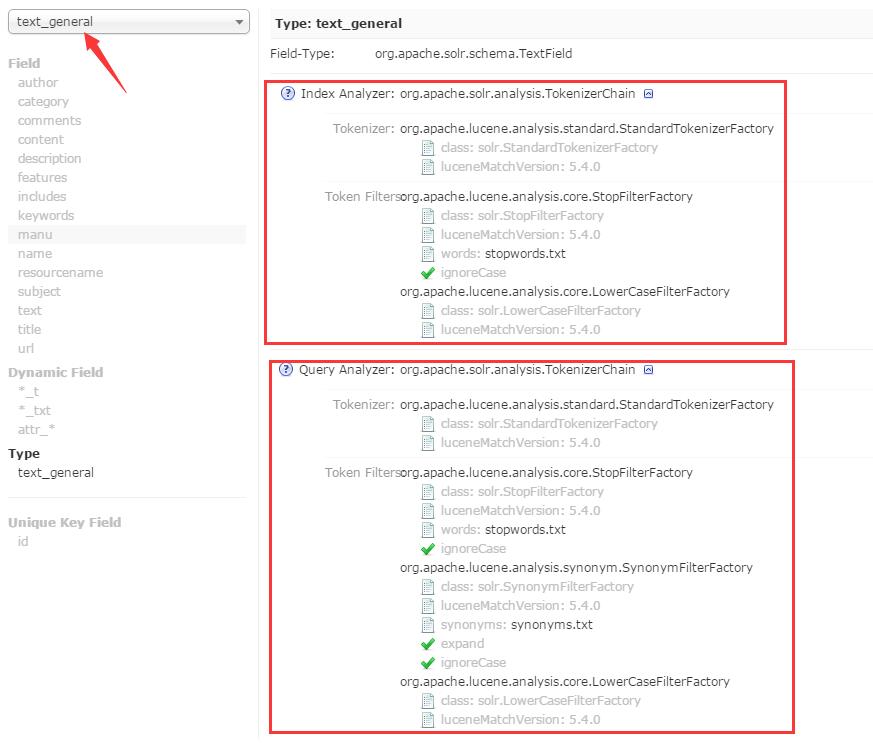
接下来,你可以分析索引或是查询文本,也可以两者同时分析。你需要输入些文本到文本框中以进行分析。将字段值放到Index文本框中,将查询文本放入Query文本框中,点击Analyze按钮看到一下文本处理结果,因为还没有中文处理,所以中文都被一个字一个字的分开处理了。
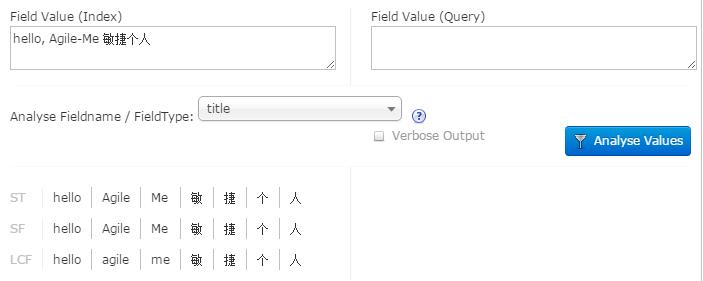
你可以选中verbose output来查看处理的详细信息,我希望你能自己试一下。
上图中每一行表示分析器处理链上的每一步的处理结果。比如第三个分析组件是LowerCaseFilter,它的处理结果就在第三行。前面的ST/SF/LCF应该是分词器和过滤器的简称。
下面我们接着来详细看看有哪些分词器和过滤器吧。
Character Filter
字符过滤器在<charFilter>元素中定义,它是对字符流进行处理。字符过滤器种类不多。这个特性只有下面第一个介绍的比较常见。
- MappingCharFilterFactory:它将一个字符(或字符串)映射到另一个,也可以映射为空。换言之,它是一个查找-替换的功能。在mapping属性中你可以指定一个配置文件。Solr的示例配置中包括了两个有用的映射配置文件:
- mapping-FoldToASCII.txt:一个丰富的将non-ASCII转化成ASCII的映射。如果想了解字符映射更多的细节,可以阅读这个文件顶部的注释。这个字符过滤器有一个类似的词元过滤器ASCIIFoldFilterFactory,这个词元过滤器运行速度更快,建议使用它。
- maping-ISOLatinAccent.txt:一个更小的映射文件子集,它只能将ISO Latin1上标映射。FoldToASCII内容更丰富,所以不建议使用这个配置。
- HTMLStripCharFilterFactory:它用于HTML和XML,它不要求它们格式完全正确。本质上它是移除所有的标记,只留下文本内容。移除脚本内容和格式元素。转义过的特殊字符被还原(比如&)。
- PatternReplaceCharFilterFactory:根据pattern属性中的正则表达式进行查找,并根据replacement属性中的值进行替换。它的实现需要一个缓冲区容器,默认设置为10000个字符,可以通过maxBlockChars进行配置。分词器和词元过滤器中也有正则表达式组件。所以你应该只在会影响分词的影响下使用它,比如对空格进行处理。
Tokenization
分词器在<tokenizer>元素中定义,它将一个字符流切分成词元序列,大部分它会去除不重要的符号,比如空字符和连接符号。
一个分析器有且只应有一个分词器,你可选的分词器如下:
- KeywordTokenizerFactory:这个分词器不进行任何分词!整个字符流变为单个词元。String域类型也有类似的效果,但是它不能配置文本分析的其它处理组件,比如大小写转换。任何用于排序和大部分Faceting功能的索引域,这个索引域只有能一个原始域值中的一个词元。
- WhitespaceTokenizerFactory:文本由空字符切分(即,空格,Tab,换行)。
- StandardTokenizerFactory:它是一个对大部分西欧语言通常的分词器。它从空白符和其它Unicode标准中的词分隔符处进行切分。空白符和分隔符会被移除。连字符也被认为是词的分隔符,这使得它不适合与WordDelimiterFilter一起用。
- UAX29URLEmailTokenizer:它表现的与StandardTokenizer相似,但它多了一个识别e-mail,URL并将它们视为单个词元的特性。
- ClassicTokenizerFactory:(曾经的StandardTokenizer)它是一个英语的通用分词器。对英语来说,它优于StandardTokenizer。它可以识别有点号的缩写词,比如I.B.M.。如果词元中包含数字它不会在连字符处分词,并可以将Email地址和主机名视为单个词元。并且ClassicFilter词元过滤器经常与这个分词器配合使用。ClassicFilter会移除缩写词中的点号,并将单引号(英语中的所有格)去除。它只能与ClassicTokenizer一起使用。
- LetterTokenizerFactory:这个分词器将相邻的字母(由Unicode定义)都视为一个词元,并忽略其它字符。
- LowerCaseTokenizerFactory:这个分词器功能上等同于LetterTokenizer加上LowerCaseFilter,但它运行更快。
- PatternTokenizerFactory:这个基于正则表达式的分词器可以以下面两种方式工作:
- 通过一个指定模式切分文本,例如你要切分一个用分号分隔的列表,你可以写:<tokenizer class="solr.PatternTokenizerFactory" pattern=";*" />.
- 只选择匹配的一个子集作为词元。比如:<tokenizer class="solr.PatternTokenizerFactory" pattern="\'([^\']+)\'" group="1" />。组属性指定匹配的哪个组将被视为词元。如果你输入的文本是aaa ‘bbb’ ‘ccc’,那么词元就是bbb和ccc。
- PathHierachyTokenizerFactory:这是一个可配置的分词器,它只处理以单个字符分隔的字符串,比如文件路径和域名。它在实现层次Faceting中很有用,或是可以过滤以某些路径下的文件。比如输入字符串是/usr/local/apache会被分词为三个词元:/usr,/usr/local,/usr/local/apache。这个分词器有下面四个选项:
- Delimiter:分隔字符:默认为/
- Replace:将分隔字符替换为另一字符(可选)
- Reverse:布尔值表明是否层次是从右边开始,比如主机名,默认:false。
- Skip:忽略开头的多少个词元,默认为0.
- WikipediaTokenizerFactory:一个用于Mediawiki语法(它用于wikipedia)的实验性质的分词器。
还有用于其它语言的分词器,比如中文和俄语,还有ICUTokenizer会检测语言。另外NGramtokenizer会在后面讨论。可以在http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters中找到更多内容。
WordDelimiterFilter
它也许不是一个正式的分词器,但是这个名为WordDeilimiterFilter的词元过滤器本质上是一个分词器。
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
上面并没有给出所有的选项,这个过滤器可以通过多种配置指定如切分和连接合成词,并有多种定义合成词的方法。这个过滤器通常与WhitespaceTokenizer配合,而不是StandardTokenizer。这个过滤器的配置中1是设置,0是重置。
WordDelimiterFilter先通过配置选项中的定义切分词元:
- 词间的分隔符切分:Agile-Me切为Agile,Me
- 字母和数据间的切分:SD500切为SD,500(如果设置splitOnNumerics)
- 忽略任何分隔符:hello,Agile-Me切为hello, Agile,Me
- 移除所有格’s:David’s切为Divid(如果设置stemEnglishPocessive)
- 在小写到大小时切分:Agile-Me切为agile,me(如果设置splitOnCaseChange)
此时,如果下面的选项没有设置,上面这些切分后的词都要被过滤掉。因为默认下面的选项设置为false,你一般至少要设置下面其中一项。
- 如果设置generateWordParts或是generateNumberParts,那么全是字母或是全是数字的词元就会不被过滤。他们还会受到连接选项的进一步影响。
- 连接多个全字母的词元,设置catenateWords(比如wi-fi连接为wifi)。如果generateWordParts设置了,这个例子还是会产生wi和fi,反过来不成立。catenateNumbers工作方式也是相似的。catenateAll会考虑连接所有的词到一起。
- 要保留原始的词,设置preserveOriginal。
下面是一个对上面选项的解释的例子:
WiFi-802.11b 切为 Wi,Fi,WiFi,802,11,80211,b,WiFi80211b, WiFi-802.11b
Stemming
词干化是去除词尾变化或是有时将派生词变回它们的词干——基本形的过程。比如,一种词干化算法可能会将Riding和Rides转化为Ride。词干化有助于提高结果召回率,但是会对准确率造成负影响。如果你是处理普通文本,你用词干化会提高你的搜索质量。但是如果你要处理的文本都是名词,比如在MusicBrainz中的艺术家名字,那么深度的词干化可能会影响结果。如果你想提高搜索的准确率,并且不降低完整率,那么你可以考虑将数据索引到两个域,其中一个进行词干化,另一个不进行词干化,在搜索时查找这两个域。
大多词干器产生的词干化的词元都不再是一个拼写合法的单词,比如Bunnies会转化为Bunni,而不是Bunny,Quote转化为Quot,你可以在Solr的文本分析页面看到这些结果。如果在索引和查找时都进行词干化,那么是不会影响搜索的。但是一个域词干化之后,就无法进行拼写检查,通配符匹配,或是输入提示,因为这些特性要直接用索引中的词。
下面是一些适用于英文的词干器:
- SnowballPorterFilterFactory:这个词干器允许选择多种词干器算法,这些词干器算法是由一个名为Snowball的程序产生的。你可以在language属性中指定你要选择的词干器。指定为English会使用Porter2算法,它比原生的Porter的算法有一点点改进。指定为Lovins会使用Lovins算法,它比起Porter有一些改进,但是运行速度太慢。
- PorterStemFIlterFactory:它是原生的英语Porter算法,它比SnowBall的速度快一倍。
- KStemFilterFactory:这个英语词干器没有Porter算法激进。也就是在很多Porter算法认为应该词干化的时候,KSterm会选择不进行词干化。我建议使用它为默认的英语词干器。
- EnglishMinimalStemFilterFactory:它是一个简单的词干器,只处理典型的复数形式。不同于多数的词干器,它词干化的词元是拼写合法的单词,它们是单数形式的。它的好处是使用这个词干器的域可以进行普通的搜索,还可以进行搜索提示。
Correcting and augmenting stemming
上面提到的词干器都是使用算法进行词干化,而不是通过词库进行词干化。语言中有许多的拼写规则,所以算法型的词干器是很难做到完美的,有时在不应该进行词干化的时候,也进行了词干化。
如果你发现了一些不应该进行词干化的词,你可以先使用KeywordMarkerFilter词干器,并在它的protected属性中指定不需要词干化的词元文件,文件中一行一个词元。还有ignoreCase布尔选项。一些词干器有或以前有protected属性有相似的功能,但这种老的方式不再建议使用。
如果你需要指定一些特定的单词如何被词干化,就先使用StemmerOverrideFilter。它的dictionary属性可以指定一个在conf目录下的UTF-8编码的文件,文件中每行两个词元,用tab分隔,前面的是输入词元,后面的是词干化后的词元。它也有ignoreCase布尔选项。这个过滤器会跳过KeywordMarkerFilter标记过的词元,并且它会标记它替换过的词元,以使后面的词干器不再处理它们。
下面是三个词干器链在分析器中配置的示例:
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" /> <filter class="solr.StemmerOverrideFilterFactory" dictionary="stemdict.txt" /> <filter class="solr.PorterStemFilterFactory" />
Synonyms
进行同义词处理的目的是很好理解的,在搜索时搜索所用的关键词可能本身并不匹配文档中的任何一个词,但文档中有这个搜索关键词的同义词,但一般来讲你还是想匹配这个文档的。当然,同义词并一定不是按字典意义上同义词,它们可以是你应该中特定领域中的同义词。
这下一个同义词的分析器配置:
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
synonyms的属性值是在conf目录下的一个文件。设置ignoreCase为true在查找同义词时忽略大小写。
在我们讨论expand选项前,我们考虑一个例子。同义词文件是一行行的。下面是一个显式映射的例子,映射用=>符号表示:
i-pod, i pod =>ipod
这表示如果在输入词元流中如果发现i-pod(一个词元)或是i pod(两个词元),都会替换为ipod。替换的同义词也可以是多个词元。逗号是分隔多个同义词之间的分隔符,同义词的词元间用空格分隔。如果你要实现自定义的不用空格分隔的格式,有一个tokenizerFactory属性,但它极少被使用。
你也可能看到配置文件里是这样的格式:
ipod, i-pod, i pod
配置文件里没有=>符号,它的意义由expand参数来决定,如果expand为true,它会被解释为下面的显式映射:
ipod, i-pod, i pod =>ipod, i-pod, i pod
如果expand设置为false,它就变为下面的显式映射,第一个同义词为替换同义词:
ipod, i-pod, i pod =>ipod
在多行中指定多个词替换为共一同义词是允许的。如果一个源同义词已经被规则替换了,另一个规则替换这个替换后词,则这两个规则可以合并。
Index-time versus query-time, and to expand or not
如果你要进行同义词扩展,你可以在索引时或是查询时进行同义处理。但不要在索引和查询时都处理,这样处理会得到正确的结果,但是会减慢处理速度。我建议在索引时进行扩展,因为在查询时进行会有下面的问题:
- 一个源同义词包含多个词元(比如:i pod)不会在查询时被查询时被识别,因为查询解析器会在分析器处理之前就对空格进行切分。
- 如果被匹配的一个同义词在所有文档中很少出现,那么Lucene打分算法中的IDF值会很高,这会使得得分不准确。
- 前缀,通配符查询不会进行文本分析,所以不会匹配同义词。
但是任何在索引时进行的分文本处理都是不灵活的。因为如果改变了同义词则需要完全重建索引才能看到效果。并且,如果在索引时进行扩展,索引会变大,如果你使用WordNet类似的同义词规则,可能索引大到你不能接受,所以你在同义词扩展规则上应该选择一个合理的度,但是我通常还是建议在索引时扩展。
你也许可以采用一种混合策略。比如,你有一个很大的索引,所以你不想对它经常重建,但是你需要使新的同义词迅速生效,所以你可以将新的同义词在查询时和索引时都使用。当全量索引重建完成后,你可以清空查询同义词文件。也许你喜欢查询时进行同义词处理,但你无法处理个别同义词有空格的情况,你可以在索引时处理这些个别的同义词。
Stop Words
StopFilterFactory是一个简单的过滤器,它是过滤掉在配置中指定的文件中的停词(stop words),这个文件在conf目录下,可以指定忽略大小写。
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
如果文档中有大量无意义的词,比如“the”,“a”,它们会使索引变大,并在使用短语查询时降低查询速度。一个简单的方法是将这些词经常出现的域中过滤掉,在包含多于一句(sentence)的内容的域中可以考虑这种作法,但是如果把停词过滤后,就无法对停词进行查询了。所以如果你要使用,应该在索引和查询分析器链中都使用。这通常是可以接受的,但是在搜索“To be or not to be”这种句子时,就会有问题。对停词理想的做法是不要去过滤它们,以后介绍CommonGramsFilterFactory来解决这个问题。
Solr自带了一个不错的英语停词集合。如果你在索引非英语的文本,你要用自己指定停词。要确定你索引中有哪些词经常出现,可以从Solr管理界面点击进入SCHEMA BROWSER。你的字段列表会在左边显示,如果这个列表没有立即出现,请耐心点,因为Solr要分析你索引里的数据,所以对于较大的索引,会有一定时间的延时。请选择一个你知道包含有大量文本的域,你可以看到这个域的大量统计,包括出现频率最高的10个词。
Phonetic sound-like analysis
语音转换(phonetic translation)可以让搜索进行语音相似匹配。语音转化的过滤器在索引和查询时都将单词编码为phoneme。有五种语音编码算法:Caverphone,DoubleMetaphone,Metaphone,RefinedSoundex和Soundex。有趣的是,DoubleMetaphone似乎是最好的选择,即使是用在非英语文本上。但也许你想通过实验来选择算法。RefinedSoundex声称是拼写检查应用中最适合的算法。然而,Solr当前无法在它的拼写检查组件中使用语音分析。
下面是在schema.xml里推荐使用的语音分析配置。
<!-- for phonetic (sounds-like) indexing --> <fieldType name="phonetic" class="solr.TextField" positionIncrementGap="100" stored="false" multiValued="true"> <analyzer> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="0" catenateWords="1" catenateNumbers="0" catenateAll="0"/> <filter class="solr.DoubleMetaphoneFilterFactory" inject="false" maxCodeLength="8"/> </analyzer> </fieldType>
注意,语音编码内部忽略大小写。
在MusicBrainz Schema中,有一个名为a_phonetic使用这个域类型,它的域值是通过copyField拷贝的Artist名字。第四章你会学习到dismax查询解析器可以让你对不同的域赋不同的boost,同时查找这几个域。你可以不仅仅搜索a_name域,你还可以用一个较低的boost来搜索a_phonenic域,这样就可以进行兼顾语音搜索了。
用Solr的分析管理页面,你可以看到这它将Smashing Pumpkins编码为SMXNK|XMXNK PMPKNS(|表示两边的词元在同一位置)。编码后的内容看起来没什么意义,实际它是为比较相似语音的效率而设计。
上面配置示例中使用的DoubleMetaphoneFilterFactory分析过滤器,它有两个选项:
- Inject:默认设置为true,为true会使原始的单词直接通过过滤器。这会影响其它的过滤器选项,查询,还可能影响打分。所以最好设置为false,并用另一个域来进行语音索引。
- maxCodeLength:最大的语音编码长度。它通常设置为4。更长的编码会被截断。只有DoubleMetaphone支持这个选项。
如果要使用其它四个语音编码算法,你必须用这个过滤器:
<filter class="solr.PhoneticFilterFactory" encoder="RefinedSoundex" inject="false"/>
其中encoder属性值是第一段中的几个算法之一。
Substring indexing and wildcards
通常,文本索引技术用来查找整个单词,但是有时会查找一个索引单词的子串,或是某些部分。Solr支持通配符查询(比如mus*ainz),但是支持它需要在索引时过行一定的处理。
要理解Lucene在索引时内部是如何支持通配符查询是很有用的。Lucene内部会在已经排序的词中先查询非通配符前缀(上例中的mus)。注意前缀的长度与整个查询的时间为指数关系,前缀越短,查询时间越长。事实上Solr配置Lucene中不支持以通配符开头的查询,就是因为效率的原因。另外,词干器,语音过滤器,和其它一些文本分析组件会影响这种查找。比如,如果running被词干化为run,而runni*无法匹配。
ReversedWildcardFilter
Solr不支持通配符开头的查询,除非你对文本进行反向索引加上正向加载,这样做可以提高前缀很短的通配符查询的效率。
下面的示例应该放到索引文本分析链的最后:
<filter class="solr.ReversedWildcardFilterFactory" />
你可以在JavaDocs中了解一些提高效率的选项,但默认的就很不错:http://lucene.apache.org/solr/api/org/apache/solr/analysis/ReversedWildcardFilterFactory.html
Solr不支持查询中同时有配置符在开头和结尾,当然这是出于性能的考虑。
N-grams
N-gram分析会根据配置中指定的子中最小最大长度,将一个词的最小到最大的子串全部得到,比如Tonight这个单词,如果NGramFilterFactory配置中指定了minGramSize为2,maxGramSize为5,那么会产生下面的索引词:(2-grams):To, on , ni, ig, gh, ht,(3-grams):ton, oni, nig, ight, ght, (4-grams):toni, onig, nigh, ight, (5-grams):tonig,onigh, night。注意Tonight完整的词不会产生,因为词的长度不能超过maxGramSize。N-Gram可以用作一个词元过滤器,也可以用作为分词器NGramTokenizerFactory,它会产生跨单词的n-Gram。
下是是使用n-grams匹配子串的推荐配置:
<fieldType name="nGram" class="solr.TextField" positionIncrementGap="100" stored="false" multiValued="true"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <!-- potentially word delimiter, synonym filter, stop words, NOT stemming --> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.NGramFilterFactory" minGramSize="2" maxGramSize="15"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <!-- potentially word delimiter, synonym filter, stop words, NOT stemming --> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
注意n-Gram只在索引时进行,gram的大小配置是根据你想进行匹配子串的长度而决定 的(示例中是最小是2,最长是15)。
N_gram分析的结果可以放到另一个用于匹配子串的域中。用dismaxquery解析器支持搜索多个域,在搜索匹配这个子串的域可以设置较小的boost。
另一个变形的是EdgeNGramTokenizerFactory和EdgeNGramFilterFactory,它会忽略输入文本开头或结尾的n-Gram。对过滤器来说,输入是一个词,对分词器来说,它是整个字符流。除了minGramSize和maxGramSize之后,它还有一个side参数,可选值为front和back。如果只需要前缀匹配或是后缀匹配,那边EdgeNGram分析是你所需要的了。
N-gram costs
n-Gram的代价很高,前面的例子中Tonight有15个子串词,而普通的文本分析的结果一般只有一个词。这种转换会产生很多词,也就需要更长的时间去索引。以MusicBrainz Schema为例,a_name域以普通方式索引并stored,a_ngram域对a_name中的值进行n-Gram分析,子串的长度为2-15。它不是一个stored域,因为Artist的名字已经保存在a_name中了。
a_name a_name + a_ngram
Increase
Indexing Time 46 seconds 479 seconds > 10x
Disk Size 11.7 MB 59.7 MB > 5x
Distinct Terms 203,431 1,288,720 > 6x
上表给出了只索引a_name和索引a_name和a_ngram的统计信息。注意索引时间增加了10倍,而索引大小增加了5倍。注意,这才只是一个域。
注意如果变大minGramSize的大小,nGram的代价会小很多。Edge nGraming也代价也会小,因为它只关心开头或结尾的nGram。基于nGram的分词器无疑会比基于nGram的过滤器代码要高,因为分词器将产生带空格的词,然而,这种方式可以支持跨词的通配符。
Sorting Text
通常,搜索结果是由神奇的score伪字段进行排序的,但是有时候也会根据某个字段的值进行排序。除了对结果进行排序,它还有许多的作用,进行区间查询和对Facet结果进行排序。
MusicBrainz提供了对Artist和Lable名称进行排序的功能。排序的版本会将原来的名字中的某些词,比如“The”移到最后,用逗号分隔。我们将排序的名字域设置为indexed,但不是stored,因为我们要对它进行排序,但不进行展示,这与MusicBrainz所实现的有所不同。记住indexed和stored默认设置为true。因为有些文本分析组件会限制text域的排序功能,所以在你的Schema中要用于排序的文本域应该拷贝到另一个域中。copyField功能会很轻松地完成这个任务。String类型不进行文本分析,所以它对我们的MusicBrainz情况是非常适合的。这样我们就支持了对Artist排序,而没有派生任何内容。
Miscellaneous token filters
Solr还包括许多其它的过滤器:
- ClassicFilterFactory:它与ClassicTokenizer配置,它会移除缩写词中的点号和末尾的’s:"I.B.M. cat's" => "IBM", "cat"
- EnglishProcessiveFilterFactory:移除’s。
- TrimFilterFactory:移除开头和结尾的空格,这对于脏数据域进行排序很有用。
- LowerCaseFilterFactory:小写化所有的文本。如果你要用WordDelimeterFilterFactory中的大小写转换切分功能,你就不要将这个过滤器放前面。
- KeepWordFilterFactory:只保留指定配置文件中的词:<filter class="solr.KeepWordFilterFactory" words="keepwords.txt" ignoreCase="true"/> 如果你想限制一个域的词汇表,你可以使用这个过滤器。
- LengthFilterFactory:过滤器会过滤掉配置长度之间的词:<filter class="solr.LengthFilterFactory" min="2" max="5" />
- LimitTokenCountFilterFactory:限制域中最多有多少个词元,数量由maxTokenCount属性指定。Solr的solrconfig.xml中还有<maxFieldLength>设置,它对所有域生效,可以将它注释掉,不限制域中的词元个数。即使没有强制限制,你还要受Java内存分配的限制,如果超过内存分配限制,就会抛出错误。
- RemoveDuplicatestTokenFilterFactory:保存重复的词不出现在同一位置。当使用同义词时这是可能发生的。如果还要进行其它的分本分析 ,你应该把这个过滤器放到最后。
- ASCIIFoldingFilterFactory:参见前面的“Character filter”一节中的MappingCharFilterFactory。
- CapitalizationFilterFactory:根据你指定的规则大写每个单词。你可以在http://lucene.apache.org/solr/api/org/apache/solr/analysis/CapitalizationFilterFactory.html中了解更多内容。
- PatternReplaceFilterFactory:使用正则表达式查找替换。比如:<filter class="solr.PatternReplaceFilterFactory" pattern=".*@(.*)" replacement="$1" replace="first" /> 这个例子是处理e-mail地址域,只取得地址中的域名。Replacement是正则表达式中的组,但它也可以是一个字符串。如果replace属性设置为first,表示只替换第一个匹配内容。如果replace设置为all,这也是默认选项,则替换全部。
- 实现你自己的过滤器:如果现有的过滤器无法满足你的需求。你可以打开Solr的代码看一下里面是如何实现的。在你深入之前,你看PatternReplaceFilterFactory的实现是如此简单。作为一个初学者,可以看一下在本书提供的补充资料中schema.xml中的rType域类型。
- 还有其它各式各样的Solr过滤器,你可以在http://lucene.apache.org/solr/api/org/apache/solr/analysis/TokenFilterFactory.html 中了解所有的过滤器。
Solr:文本分析的更多相关文章
- 使用Linux的命令行工具做简单的文本分析
Basic Text Analysis with Command Line Tools in Linux | William J Turkel 这篇文章非常清楚的介绍了如何使用Linux的命令行工具进 ...
- 用R进行文本分析初探——以《红楼梦》为例
一.写在前面的话~ 刚吃饭的时候同学问我,你为什么要用R做文本分析,你不是应该用R建模么,在我和她解释了一会儿后,她嘱咐我好好写这篇博文,嗯为了娟儿同学,细细说一会儿文本分析. 文本数据挖掘(Text ...
- 重磅︱R+NLP:text2vec包——New 文本分析生态系统 No.1(一,简介)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 词向量的表示主流的有两种方式,一种当然是耳熟能 ...
- Linux文本分析命令awk的妙用
基本用法 awk是一个强大的文本分析工具,简单来说awk就是把文件逐行读入,(空格,制表符)为默认分隔符将每行切片,切开的部分再进行各种分析处理 awk命令格式如下 awk [-F field-sep ...
- LinkedIn文本分析平台:主题挖掘的四大技术步骤
作者 Yongzheng (Tiger) Zhang ,译者 木环 ,本人只是备份一下.. LinkedIn前不久发布两篇文章分享了自主研发的文本分析平台Voices的概览和技术细节.LinkedIn ...
- R软件中 文本分析安装包 Rjava 和 Rwordseg 傻瓜式安装方法四部曲
这两天,由于要做一个文本分析的内容,所以搜索了一天R语言中的可以做文本分析的加载包,但是在安装包的过程,真是被虐千百遍,总是安装不成功.特此专门写一篇博文,把整个心塞史畅快的释放一下. ------- ...
- linux文本分析利器awk
转 快速理解linux文本分析利器awk 原文链接 杜亦舒 性能与架构 awk是什么 如果工作中需要操作linux比较多,那么awk是非常值得学习的 awk是一个极其强大的文本分析工具,把文件逐行的读 ...
- linux 文本分析工具---awk命令(7/1)
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各 ...
- Linux 之 awk文本分析工具
AWK是一种处理文本文件的语言,是一个强大的文本分析工具.Linux环境中自带. awk调用方法 命令行 awk [-F field-separator] 'commands' input-file( ...
随机推荐
- 01 选择 Help > Install New Software,在出现的对话框里,点击Add按钮,在对话框的name一栏输入“ADT”,点击Archive...选择离线的ADT文件,contact all update ....千万不要勾选点击Add按钮,在对话框的name一栏输入“ADT”,点击Archive...选择离线的ADT文件,contact all update ....千万不要勾
引言 好久没碰过android,今天重新搭建了一次环境,遇到的问题记录下载.共以后使用. 安装 软件的软件有jdk+eclipse+adt+sdk 主要记录安装adt和sdk的过程,注意,adt和sd ...
- 使用Vs2012开发Metro时在另一台win8平板上调试的步骤
需求:开发一个metro应用,因为要给平面设计师参谋, 需要将软件安装在win8平板上. 环境:开发机是win8, win8平板是win8.1rtm , 是用老的win7平板改装的. 步骤: 1:拷 ...
- PADS从原理图到PCB整体简易流程
10步完成PADS从原理图到PCB设计 图片有点大,可以点击观看. 第一步:启动PADS LOGIC 第二步:添加元器件 第三步:选择2个9脚接插头放置在原理图上 第四步:添加连线. 完成后如图 第五 ...
- Yii2中的零碎知识点
PHP最佳实践 1 PHP获取时间戳:echo time(); 时间戳转换 date('Y-m-d H:i:s', $时间戳); 2 linux 显示命令 ls 显示所有文件夹 查看命令:tail ...
- 探求网页同步提交、ajax和comet不为人知的秘密(上篇)
标题里的技术都是web开发里最常见的技术,但是我想这些常用的技术有很多细节是很多朋友不太清楚的,理解这些细节是我们深入掌握这些技术的一把钥匙,今天我就讲讲我使用这些技术时体会到的这些细节. 同步提交是 ...
- 使用后缀数组寻找最长公共子字符串JavaScript版
后缀数组很久很久以前就出现了,具体的概念读者自行搜索,小菜仅略知一二,不便讨论. 本文通过寻找两个字符串的最长公共子字符串,演示了后缀数组的经典应用. 首先需要说明,小菜实现的这个后缀数组算法,并非标 ...
- AWS re:Invent 2014回顾
亚马逊在2014年11月11-14日的拉斯维加斯举行了一年一度的re:Invent大会.在今年的大会上,亚马逊一股脑发布和更新了很多服务.现在就由我来带领大家了解一下这些新服务. 安全及规范相关 AW ...
- 连接池技术 Connection Pooling
原创地址:http://www.cnblogs.com/jfzhu/p/3705703.html 转载请注明出处 和数据库建立一个物理连接是一个很耗时的任务,所以无论是ADO.NET还是J2EE都提供 ...
- 爱上MVC系列~带扩展名的路由失效问题
回到目录 对MVC中,对URL进行重写变得非常方便,你只要设置相应的路由规则即可完成,但进行MVC3后,发现设置了以下路由,系统具体不认 routes.MapRoute( name: "De ...
- Nodejs·构建web应用
本篇的内容比较多..... 1 首先是从基本的Nodejs服务方面讲述前后端统一语言在web应用中的作用: 2 然后讲了web中基本的知识,从请求方法到路由.从查询字符串到Cookie和Session ...