Elasticsearch聚合 之 Histogram 直方图聚合
Elasticsearch支持最直方图聚合,它在数字字段自动创建桶,并会扫描全部文档,把文档放入相应的桶中。这个数字字段既可以是文档中的某个字段,也可以通过脚本创建得出的。
桶的筛选规则
举个例子,有一个price字段,这个字段描述了商品的价格,现在想每隔5就创建一个桶,统计每隔区间都有多少个文档(商品)。
如果有一个商品的价格为32,那么它会被放入30的桶中,计算的公式如下:
rem = value % interval
if (rem < 0) {
rem += interval
}
bucket_key = value - rem
通过上面的方法,就可以确定文档属于哪一个桶。
不过也有一些问题存在,由于上面的方法是针对于整型数据的,因此如果字段是浮点数,那么需要先转换成整型,再调用上面的方法计算。问题来了,正数还好,如果该值是负数,就会出现计算出错。比如,一个字段的值为-4.5,在进行转换整型时,转换成了-4。那么按照上面的计算,它就会放入-4的桶中,但是其实-4.5应该放入-6的桶中。
min_doc_count过滤
聚合的dsl如下:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50
}
}
}
}
得到的数据为:
{
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 50,
"doc_count": 4
},
{
"key": 100,
"doc_count": 0
},
{
"key": 150,
"doc_count": 3
}
]
}
}
}
上面的数据中,100-150是没有文档的,但是却显示为0.如果不想要显示count为0的桶,可以通过min_doc_count来设置。
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1
}
}
}
}
这样返回的数据,就不会出现为0的了。
{
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 50,
"doc_count": 4
},
{
"key": 150,
"doc_count": 3
}
]
}
}
}
extend_bounds,指定最小值和最大值边界
默认情况下,ES中的histogram聚合起始都是自动的,比如price字段,如果没有商品的价钱在0-5之间,0这个桶就不会显示。如果最便宜的商品是11,那么第一个桶就是10.
可以通过设置extend_bounds强制规定最小值和最大值,但是要求必须min_doc_count不能大于0,不然即便是规定了边界,也不会返回。

另外需要注意的是,如果规定的extend_bounds.min要大于文档中的最小值,那么就会按照文档中的最小值来(extend_bounds.max也是如此)。
比如下面的这个例子,规定的extend_bounds.min和max分别是40和50,但是文档中含有比40还要小的数据,因此桶的定义仍然是按照文档中的数据来。
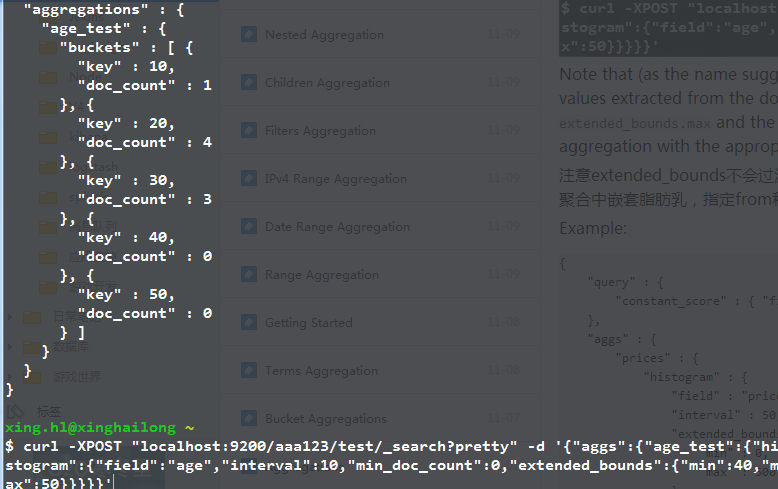
order排序
排序大同小异,可以按照_key的名字排序:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_key" : "desc" }
}
}
}
}
也可以按照文档的数目:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_count" : "asc" }
}
}
}
}
或者指定排序的聚合:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "price_stats.min" : "asc" }
},
"aggs" : {
"price_stats" : { "stats" : {} }
}
}
}
}
keyed设置返回的方式
正常返回的数据如上面所示,是按照数组的方式返回。如果要按照名字返回,可以设置keyed为true
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"keyed" : true
}
}
}
}
那么返回的数据就为:
{
"aggregations": {
"prices": {
"buckets": {
"0": {
"key": 0,
"doc_count": 2
},
"50": {
"key": 50,
"doc_count": 4
},
"150": {
"key": 150,
"doc_count": 3
}
}
}
}
}
缺省的值
缺省值通过MissingValue设置:
{
"aggs" : {
"quantity" : {
"histogram" : {
"field" : "quantity",
"interval": 10,
"missing": 0
}
}
}
}
Elasticsearch聚合 之 Histogram 直方图聚合的更多相关文章
- Elasticsearch聚合 Date Histogram聚合
转 http://www.cnblogs.com/xing901022/p/4951603.html Elasticsearch的聚合主要分成两大类:metric和bucket,2.0中新增了pipe ...
- Elasticsearch聚合 之 Range区间聚合
Elasticsearch提供了多种聚合方式,能帮助用户快速的进行信息统计与分类,本篇主要讲解下如何使用Range区间聚合. 最简单的例子,想要统计一个班级考试60分以下.60到80分.80到100分 ...
- ElasticSearch 2 (35) - 信息聚合系列之近似聚合
ElasticSearch 2 (35) - 信息聚合系列之近似聚合 摘要 如果所有的数据都在一台机器上,那么生活会容易许多,CS201 课商教的经典算法就足够应付这些问题.但如果所有的数据都在一台机 ...
- elasticsearch聚合之bucket terms聚合
目录 1. 背景 2. 前置条件 2.1 创建索引 2.2 准备数据 3. 各种聚合 3.1 统计人数最多的2个省 3.1.1 dsl 3.1.2 运行结果 3.2 统计人数最少的2个省 3.2.1 ...
- Elasticsearch学习系列四(聚合搜索)
聚合分析 聚合分析是数据库中重要的功能特性,完成对一个查询的集中数据的聚合计算.如:最大值.最小值.求和.平均值等等.对一个数据集求和,算最大最小值等等,在ES中称为指标聚合,而对数据做类似关系型数据 ...
- Flask聚合函数(基本聚合函数、分组聚合函数、去重聚合函数))
Flask聚合函数 1.基本聚合函数(sun/count/max/min/avg) 使用聚合函数先导入:from sqlalchemy import func 使用方法: sun():func.sum ...
- 把 Elasticsearch 当数据库使:聚合后排序
使用 https://github.com/taowen/es-monitor 可以用 SQL 进行 elasticsearch 的查询.有的时候分桶聚合之后会产生很多的桶,我们只对其中部分的桶关心. ...
- Elasticsearch 聚合统计与SQL聚合统计语法对比(一)
Es相比关系型数据库在数据检索方面有着极大的优势,在处理亿级数据时,可谓是毫秒级响应,我们在使用Es时不仅仅进行简单的查询,有时候会做一些数据统计与分析,如果你以前是使用的关系型数据库,那么Es的数据 ...
- Elasticsearch 第六篇:聚合统计查询
h2.post_title { background-color: rgba(43, 102, 149, 1); color: rgba(255, 255, 255, 1); font-size: 1 ...
随机推荐
- [ASE]项目介绍及项目跟进——TANK BATTLE·INFINITE
童年的记忆,大概是每周末和小伙伴们围坐在电视机前,在20来寸的电视机屏幕里守卫着这个至今都不知道是什么的白色大鸟. 当年被打爆的坦克数量估计也能绕地球个三两圈了吧. 十几年过去了,游戏从2D-3D,画 ...
- PAT/图形输出习题集
B1027. 打印沙漏 (20) Description: 本题要求你写个程序把给定的符号打印成沙漏的形状.例如给定17个"*",要求按下列格式打印 ***** *** * *** ...
- 蛙蛙推荐:WEB安全入门
信息安全基础 信息安全目标 真实性:对信息的来源进行判断,能对伪造来源的信息予以鉴别, 就是身份认证. 保密性:保证机密信息不被窃听,盗取,或窃听者不能了解信息的真实含义. 完整性:保证数据的一致性, ...
- 【视频教程】使用UIAutomation开发软件外挂
UIAutomation是.Net 3.5之后提供的“界面自动化测试”技术,本来是给测试人员用的,不过UIAutomation由于也是界面自动操作的技术,比直接使用keybd_event.GetWin ...
- 创建动态WCF服务(无配置文件)
public class WCFServer { ServiceHost host = null; public WCFServer(string addressurl, string tcpurl, ...
- ASP.NET 5系列教程 (一):领读新特性
近期微软发布了ASP.NET 5.0,本次发布的新特性需求源于大量用户的反馈和需求,例如灵活的跨平台运行时和自主部署能力使ASP.NET应用不再受限于IIS.Cloud-ready环境配置降低了云端部 ...
- InnoSetup 如何获取安装程序的路径?
两个常量可以使用: {srcexe} 安装程序执行文件的路径. {src} 安装程序所在路径. path := ExpandConstant('{srcexe}');
- 示例篇-购物车的简单示例和自定义JS
简介: 支持平台: Android4.0,iOS7.0,Windows 10, Windows 10 mobile 说明:主要是演示listview所在的ui和模板cell所在的ui之间数据的交互,点 ...
- 【吉光片羽】奇怪的Bug-细节的问题
这几天用Winform开发了一个小界面,遇到几个奇怪的问题,记录一下. 1.背景图片漏光. 当时很是奇怪,以为是图片的问题,让美工重新发,改成jpg也都存在.很是奇怪,原图这个地方肉眼看是不透明的,而 ...
- java中基本类型和包装类型实践经验
至今,小菜用java快两年了,有些事,也该有个总结. 基本类型和包装类型的概念在本文不作赘述. 如果这两种类型直接使用,倒没什么值得讨论的,无非就是自动装箱拆箱,java可以让你感觉不到他们的存在,但 ...