Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取
、SparkSQL的发展历程
1.1 Hive and Shark
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
l MapR的Drill
l Cloudera的Impala
l Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
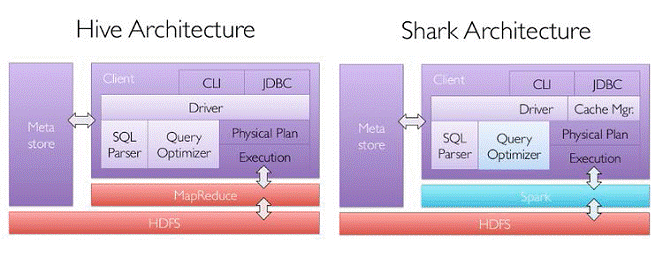
1.2 Shark和SparkSQL
但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步,海阔天空”。
l数据兼容方面 不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据;
l性能优化方面 除了采取In-Memory Columnar Storage、byte-code generation等优化技术外、将会引进Cost Model对查询进行动态评估、获取最佳物理计划等等;
l组件扩展方面 无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展。
年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark。
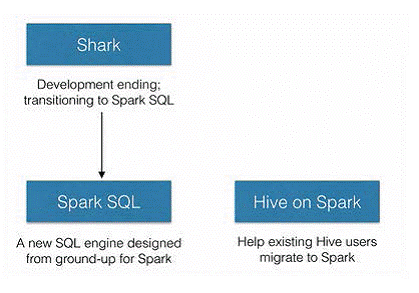
其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
1.3 SparkSQL的性能
Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高:
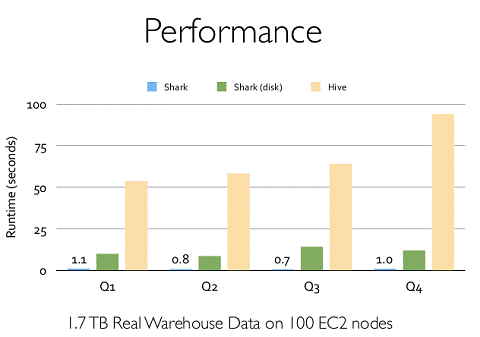
那么,摆脱了Hive的限制,SparkSQL的性能又有怎么样的表现呢?虽然没有Shark相对于Hive那样瞩目地性能提升,但也表现得非常优异:
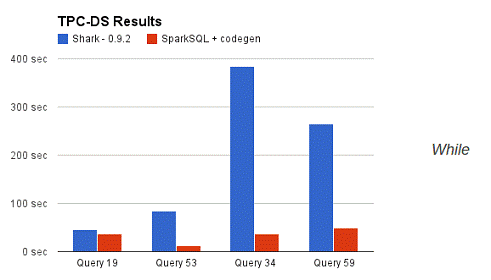
为什么SparkSQL的性能会得到怎么大的提升呢?主要SparkSQL在下面几点做了优化:
A:内存列存储(In-Memory Columnar Storage)
SparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,如下图所示。
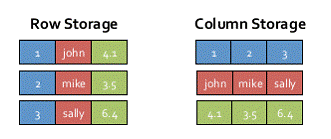
该存储方式无论在空间占用量和读取吞吐率上都占有很大优势。
~5倍于原生数据空间);另外,使用这种方式,每个数据记录产生一个JVM对象,如果是大小为200B的数据记录,32G的堆栈将产生1.6亿个对象,这么多的对象,对于GC来说,可能要消耗几分钟的时间来处理(JVM的垃圾收集时间与堆栈中的对象数量呈线性相关)。显然这种内存存储方式对于基于内存计算的Spark来说,很昂贵也负担不起。
对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。这样,每个列创建一个JVM对象,从而导致可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。
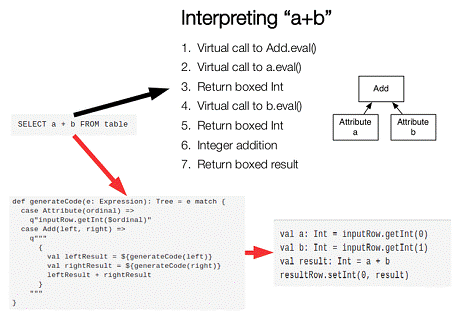
B:字节码生成技术(bytecode generation,即CG)
在数据库查询中有一个昂贵的操作是查询语句中的表达式,主要是由于JVM的内存模型引起的。比如如下一个查询:
SELECT a + b FROM table
个步骤:
1. 调用虚函数Add.eval(),需要确认Add两边的数据类型
2. 调用虚函数a.eval(),需要确认a的数据类型
3. 确定a的数据类型是Int,装箱
4. 调用虚函数b.eval(),需要确认b的数据类型
5. 确定b的数据类型是Int,装箱
6. 调用Int类型的Add
7. 返回装箱后的计算结果
其中多次涉及到虚函数的调用,虚函数的调用会打断CPU的正常流水线处理,减缓执行。
Spark1.1.0在catalyst模块的expressions增加了codegen模块,如果使用动态字节码生成技术(配置spark.sql.codegen参数),SparkSQL在执行物理计划的时候,对匹配的表达式采用特定的代码,动态编译,然后运行。如上例子,匹配到Add方法:
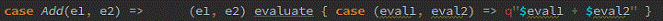
然后,通过调用,最终调用:
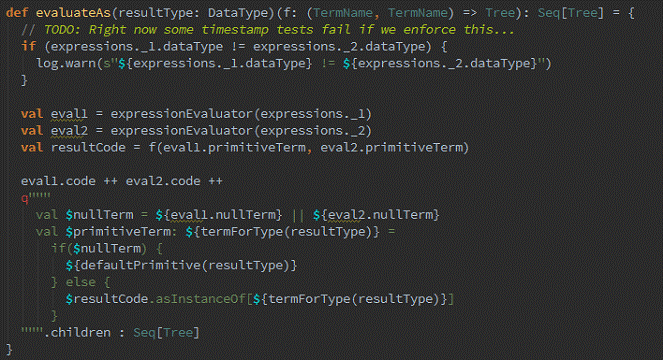
最终实现效果类似如下伪代码:
val a: Int = inputRow.getInt(0)
val b: Int = inputRow.getInt(1)
val result: Int = a + b
resultRow.setInt(0, result)
对于Spark1.1.0,对SQL表达式都作了CG优化,具体可以参看codegen模块。CG优化的实现主要还是依靠scala2.10的运行时放射机制(runtime reflection)。对于SQL查询的CG优化,可以简单地用下图来表示:
C:Scala代码优化
另外,SparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说,还是使用统一的接口,没受到使用上的困难。下图是一个Scala代码优化的示意图:

、 SparkSQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。
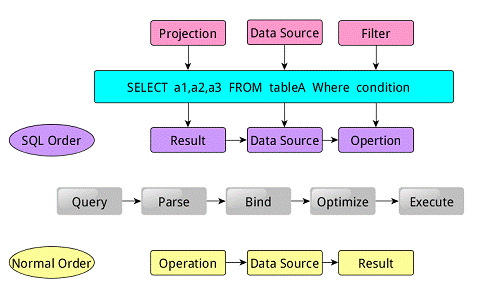
当执行SparkSQL语句的顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->Data Source-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
2.1 Tree和Rule
SparkSQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。
2.1.1 Tree
l Tree的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees
l Logical Plans、Expressions、Physical Operators都可以使用Tree表示
l Tree的具体操作是通过TreeNode来实现的
Ø SparkSQL定义了catalyst.trees的日志,通过这个日志可以形象的表示出树的结构
Ø TreeNode可以使用scala的集合操作方法(如foreach, map, flatMap, collect等)进行操作
Ø 有了TreeNode,通过Tree中各个TreeNode之间的关系,可以对Tree进行遍历操作,如使用transformDown、transformUp将Rule应用到给定的树段,然后用结果替代旧的树段;也可以使用transformChildrenDown、transformChildrenUp对一个给定的节点进行操作,通过迭代将Rule应用到该节点以及子节点。
l TreeNode可以细分成三种类型的Node:
Ø UnaryNode 一元节点,即只有一个子节点。如Limit、Filter操作
Ø BinaryNode 二元节点,即有左右子节点的二叉节点。如Jion、Union操作
Ø LeafNode 叶子节点,没有子节点的节点。主要用户命令类操作,如SetCommand
2.1.2 Rule
l Rule的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules
l Rule在SparkSQL的Analyzer、Optimizer、SparkPlan等各个组件中都有应用到
l Rule是一个抽象类,具体的Rule实现是通过RuleExecutor完成
l Rule通过定义batch和batchs,可以简便的、模块化地对Tree进行transform操作
l Rule通过定义Once和FixedPoint,可以对Tree进行一次操作或多次操作(如对某些Tree进行多次迭代操作的时候,达到FixedPoint次数迭代或达到前后两次的树结构没变化才停止操作,具体参看RuleExecutor.apply)
2.2 sqlContext和hiveContext的运行过程
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器(SQL-92语法);hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法,
2.2.1 sqlContext的运行过程
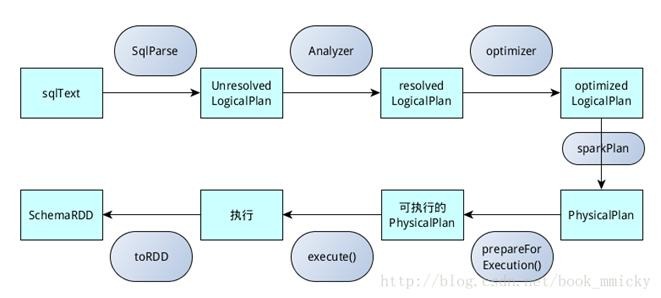
sqlContext总的一个过程如下图所示:
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
3.使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
4.使用SparkPlan将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.生成SchemaRDD。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等
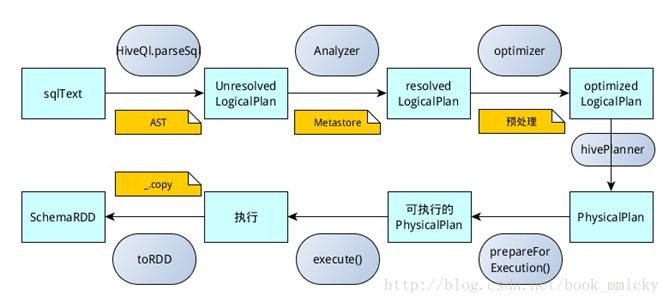
2.2.2hiveContext的运行过程
hiveContext总的一个过程如下图所示:
1.SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析;
2.使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
3.使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
4.使用hivePlanner将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.执行后,使用map(_.copy)将结果导入SchemaRDD。
2.3 catalyst优化器
SparkSQL1.1总体上由四个模块组成:core、catalyst、hive、hive-Thriftserver:
l core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
l catalyst处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
l hive对hive数据的处理
l hive-ThriftServer提供CLI和JDBC/ODBC接口
在这四个模块中,catalyst处于最核心的部分,其性能优劣将影响整体的性能。由于发展时间尚短,还有很多不足的地方,但其插件式的设计,为未来的发展留下了很大的空间。下面是catalyst的一个设计图:
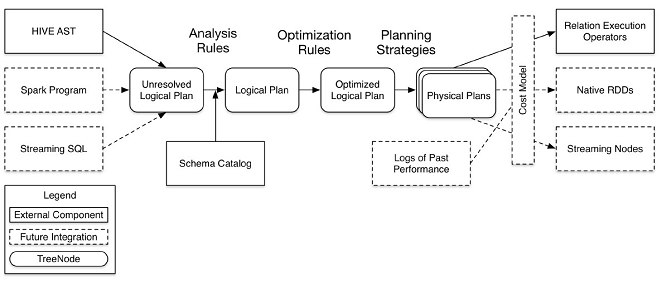
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
lsqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
lAnalyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和数据元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
loptimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan;
l Planner将LogicalPlan转换成PhysicalPlan;
l CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划
这些组件的基本实现方法:
l 先将sql语句通过解析生成Tree,然后在不同阶段使用不同的Rule应用到Tree上,通过转换完成各个组件的功能。
l Analyzer使用Analysis Rules,配合数据元数据(如hive metastore、Schema catalog),完善Unresolved LogicalPlan的属性而转换成resolved LogicalPlan;
l optimizer使用Optimization Rules,对resolved LogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan;
l Planner使用Planning Strategies,对optimized LogicalPlan
、SparkSQL CLI
CLI(Command-Line Interface,命令行界面)是指可在用户提示符下键入可执行指令的界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后予以执行。Spark CLI指的是使用命令界面直接输入SQL命令,然后发送到Spark集群进行执行,在界面中显示运行过程和最终的结果。
Spark1.1相较于Spark1.0最大的差别就在于Spark1.1增加了Spark SQL CLI和ThriftServer,使得Hive用户还有用惯了命令行的RDBMS数据库管理员较容易地上手,真正意义上进入了SQL时代。
【注】Spark CLI和Spark Thrift Server实验环境为第二课《Spark编译与部署(下)--Spark编译安装》所搭建
3.1 运行环境说明
3.1.1 硬软件环境
线程,主频2.2G,10G内存
l 虚拟软件:VMware® Workstation 9.0.0 build-812388
l 虚拟机操作系统:CentOS 64位,单核
l 虚拟机运行环境:
Ø JDK:1.7.0_55 64位
位)
Ø Scala:2.11.4
Ø Spark:1.1.0(需要编译)
Ø Hive:0.13.1
3.1.2 机器网络环境
集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下:
|
序号 |
IP地址 |
机器名 |
类型 |
核数/内存 |
用户名 |
目录 |
|
192.168.0.61 |
hadoop1 |
NN/DN/RM Master/Worker |
核/3G |
hadoop |
/app 程序所在路径 /app/scala-... /app/hadoop /app/complied |
|
|
192.168.0.62 |
hadoop2 |
DN/NM/Worker |
核/2G |
hadoop |
||
|
192.168.0.63 |
hadoop3 |
DN/NM/Worker |
核/2G |
hadoop |
3.2 配置并启动
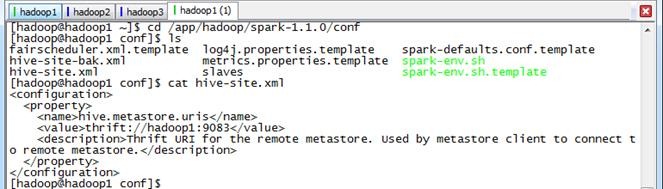
3.2.1 创建并配置hive-site.xml
在运行Spark SQL CLI中需要使用到Hive Metastore,故需要在Spark中添加其uris。具体方法是在SPARK_HOME/conf目录下创建hive-site.xml文件,然后在该配置文件中,添加hive.metastore.uris属性,具体如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
</configuration>
3.2.2 启动Hive
在使用Spark SQL CLI之前需要启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS),使用如下命令可以使Hive Metastore启动后运行在后台,可以通过jobs查询:
$nohup hive --service metastore > metastore.log 2>&1 &

3.2.3 启动Spark集群和Spark SQL CLI
通过如下命令启动Spark集群和Spark SQL CLI:
$cd /app/hadoop/spark-1.1.0
$sbin/start-all.sh
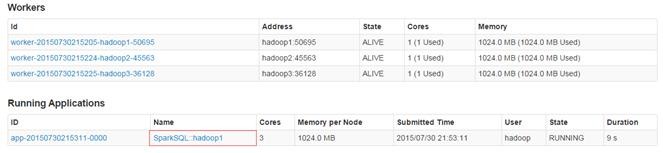
$bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g
在集群监控页面可以看到启动了SparkSQL应用程序:
个partition,可以使用如下命令修改该参数:
SET spark.sql.shuffle.partitions=20;
变成了20。
3.2.4 命令参数
通过bin/spark-sql --help可以查看CLI命令参数:
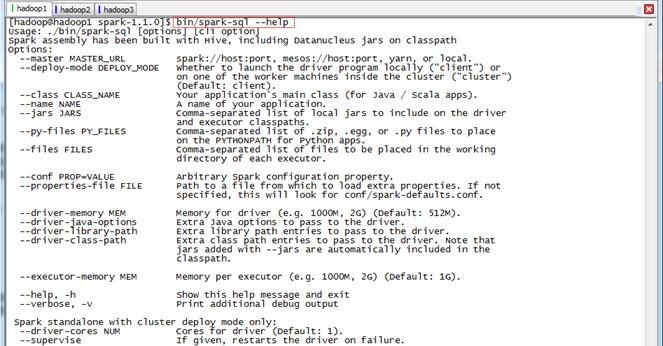
其中[options] 是CLI启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动spark-sql的机器以local方式运行,只能通过http://机器名:4040进行监控;这部分参数,可以参照Spark1.0.0 应用程序部署工具spark-submit 的参数。
[cli option]是CLI的参数,通过这些参数CLI可以直接运行SQL文件、进入命令行运行SQL命令等等,类似以前的Shark的用法。需要注意的是CLI不是使用JDBC连接,所以不能连接到ThriftServer;但可以配置conf/hive-site.xml连接到Hive的Metastore,然后对Hive数据进行查询。
3.3 实战Spark SQL CLI
3.3.1 获取订单每年的销售单数、销售总额
个
spark-sql>SET spark.sql.shuffle.partitions=20;

第二步 运行SQL语句
spark-sql>use hive;

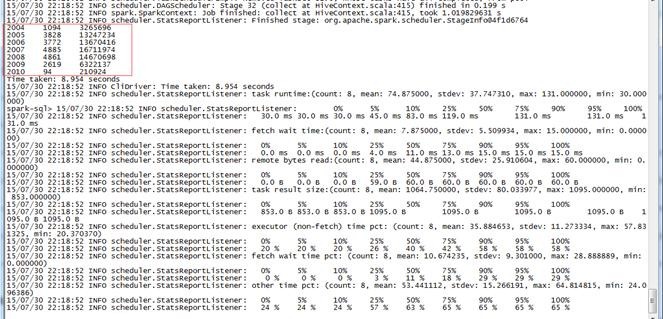
spark-sql>select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear;

第三步 查看运行结果
3.3.2 计算所有订单每年的总金额
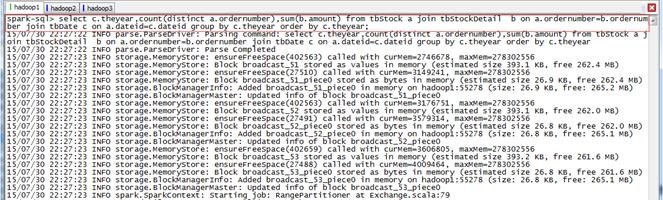
第一步 执行SQL语句
spark-sql>select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear;
第二步 执行结果
使用CLI执行结果如下:
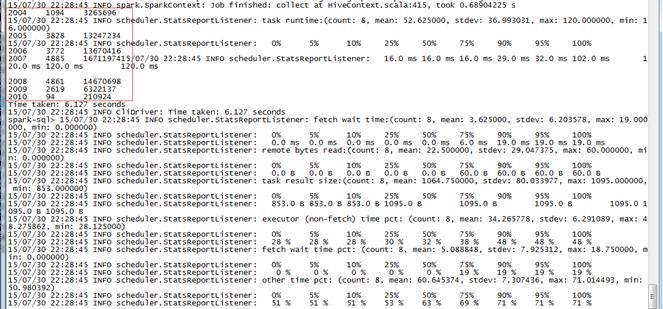
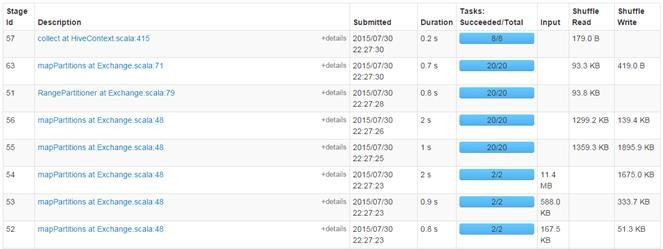
3.3.3 计算所有订单每年最大金额订单的销售额
第一步 执行SQL语句
spark-sql>select c.theyear,max(d.sumofamount) from tbDate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear;
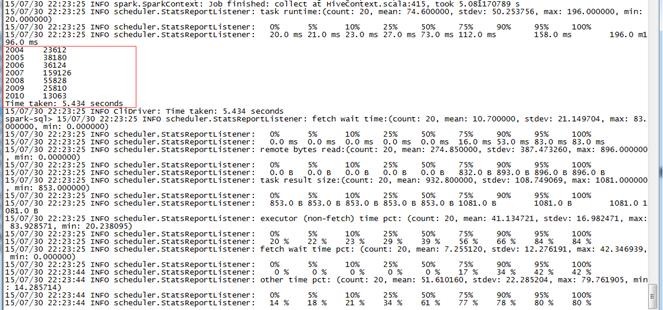
第二步 执行结果
使用CLI执行结果如下:
、Spark Thrift Server
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个SparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个SparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用Hive数据的话,还要提供Hive Metastore的uris。
【注】Spark CLI和Spark Thrift Server实验环境为第二课《Spark编译与部署(下)--Spark编译安装》所搭建
4.1 配置并启动
4.1.1 创建并配置hive-site.xml
第一步 创建hive-site.xml配置文件
在$SPARK_HOME/conf目录下修改hive-site.xml配置文件(如果在Spark SQL CLI中已经添加,可以省略):
$cd /app/hadoop/spark-1.1.0/conf
$sudo vi hive-site.xml

第二步 修改配置文件
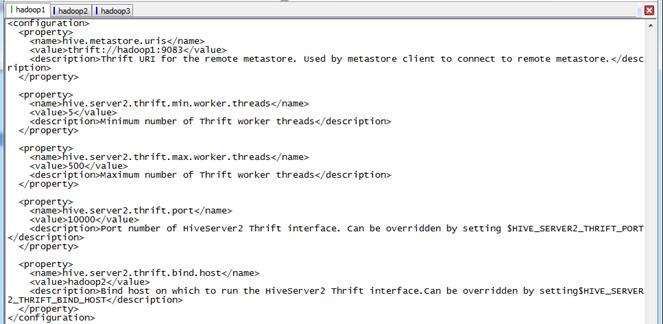
设置hadoop1为Metastore服务器,hadoop2为Thrift Server服务器,配置内容如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>5</value>
<description>Minimum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>500</value>
<description>Maximum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop2</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.Can be overridden by setting$HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
</configuration>
4.1.2 启动Hive
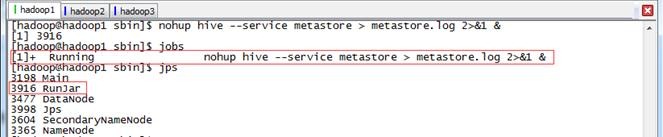
在hadoop1节点中,在后台启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS):
$nohup hive --service metastore > metastore.log 2>&1 &
4.1.3 启动Spark集群和Thrift Server
在hadoop1节点启动Spark集群
$cd /app/hadoop/spark-1.1.0/sbin
$./start-all.sh
在hadoop2节点上进入SPARK_HOME/sbin目录,使用如下命令启动Thrift Server
$cd /app/hadoop/spark-1.1.0/sbin
$./start-thriftserver.sh --master spark://hadoop1:7077 --executor-memory 1g
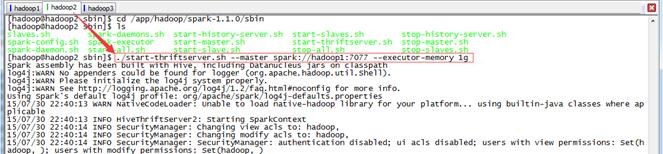
注意:Thrift Server需要按照配置在hadoop2启动!
在集群监控页面可以看到启动了SparkSQL应用程序:
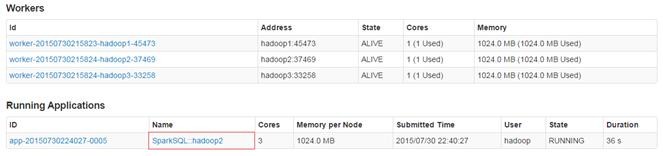
4.1.4 命令参数
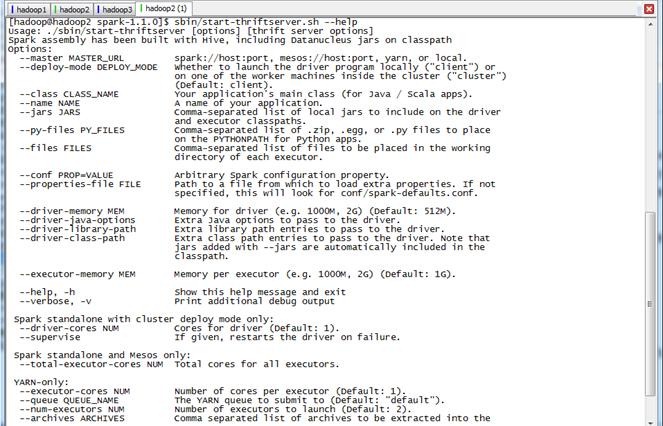
使用sbin/start-thriftserver.sh --help可以查看ThriftServer的命令参数:
$sbin/start-thriftserver.sh --help Usage: ./sbin/start-thriftserver [options] [thrift server options]
Thrift server options: Use value for given property
其中[options] 是Thrift Server启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动Thrift Server的机器以local方式运行,只能通过http://机器名:4040进行监控;这部分参数,可以参照Spark1.0.0 应用程序部署工具spark-submit 的参数。在集群中提供Thrift Server的话,一定要配置master、executor-memory等参数。
[thrift server options]是Thrift Server的参数,可以使用-dproperty=value的格式来定义;在实际应用上,因为参数比较多,通常使用conf/hive-site.xml配置。
4.2 实战Thrift Server
4.2.1 远程客户端连接
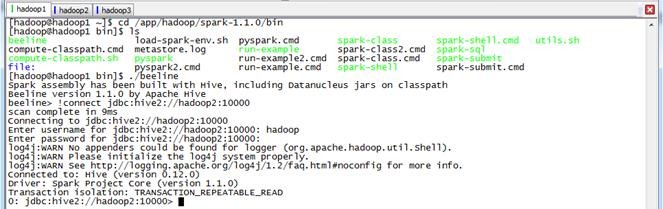
可以在任意节点启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000连接ThriftServer,因为没有采用权限管理,所以用户名用运行bin/beeline的用户hadoop,密码为空:
$cd /app/hadoop/spark-1.1.0/bin
$./beeline
beeline>!connect jdbc:hive2://hadoop2:10000
4.2.2 基本操作
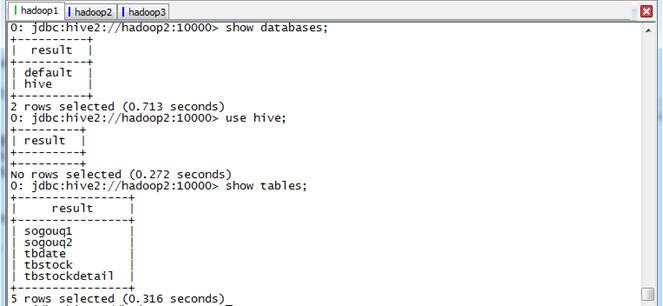
第一步 显示hive数据库所有表
beeline>show database;
beeline>use hive;
beeline>show tables;
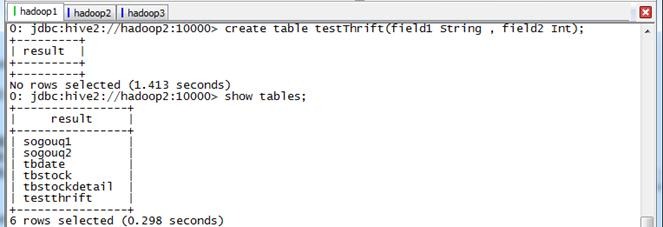
第二步 创建表testThrift
beeline>create table testThrift(field1 String , field2 Int);
beeline>show tables;
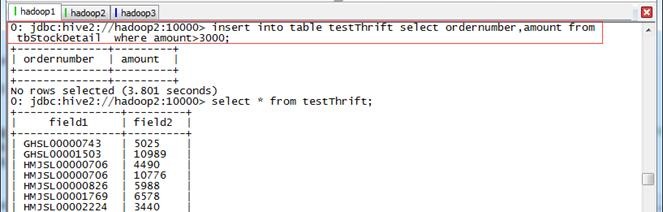
插入到testThrift表中
beeline>insert into table testThrift select ordernumber,amount from tbStockDetail where amount>3000;
beeline>select * from testThrift;
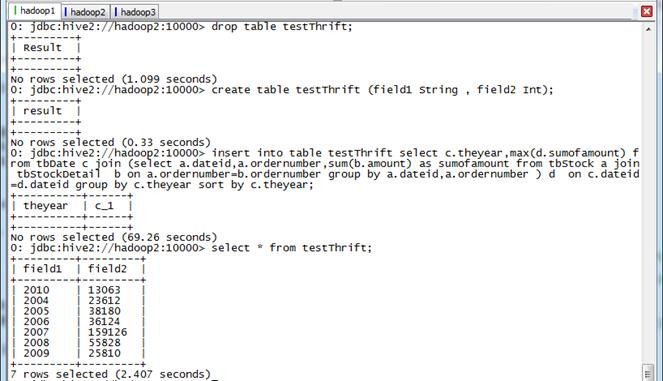
第四步 重新创建testThrift表中,把年度最大订单插入该表中
beeline>drop table testThrift;
beeline>create table testThrift (field1 String , field2 Int);
beeline>insert into table testThrift select c.theyear,max(d.sumofamount) from tbDate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear;
beeline>select * from testThrift;
4.2.3 计算所有订单每年的订单数
第一步 执行SQL语句
spark-sql>select c.theyear, count(distinct a.ordernumber) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear;
第二步 执行结果
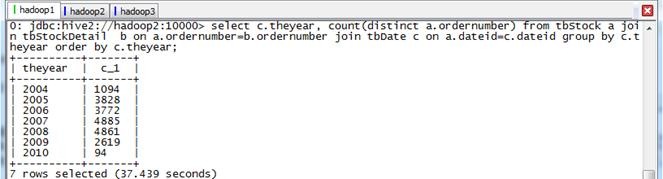
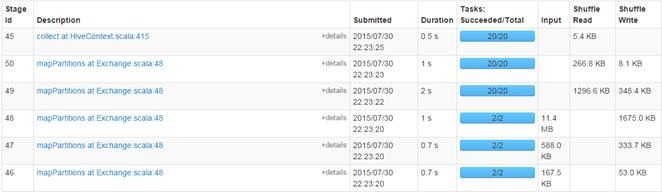
Stage监控页面:
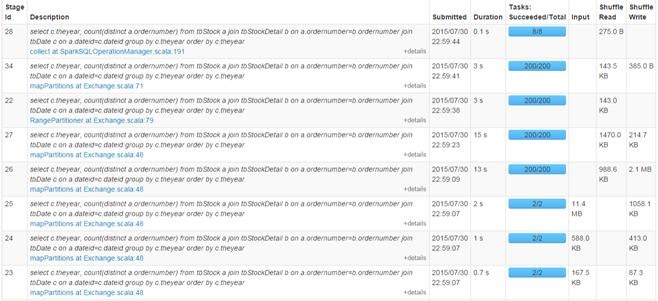
查看Details for Stage 28
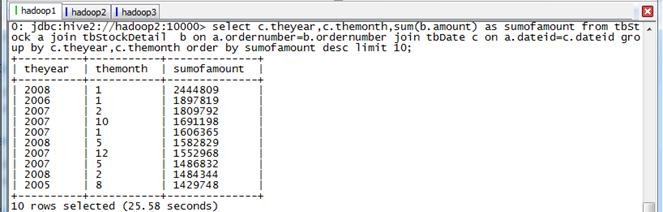
4.2.4 计算所有订单月销售额前十名
第一步 执行SQL语句
spark-sql>select c.theyear,c.themonth,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,c.themonth order by sumofamount desc limit 10;
第二步 执行结果
Stage监控页面:

在其第一个Task中,从本地读入数据
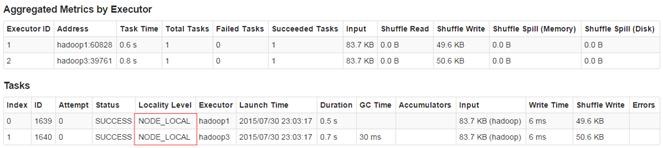
在后面的Task是从内存中获取数据
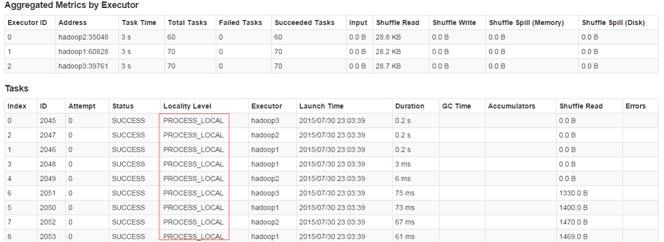
4.2.5 缓存表数据
第一步 缓存数据
beeline>cache table tbStock;
beeline>select count(*) from tbStock;
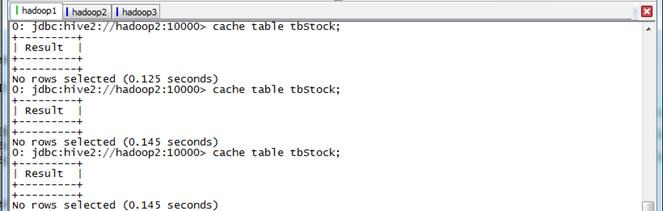
第二步 运行4.2.4中的“计算所有订单月销售额前十名”
beeline>select count(*) from tbStock;
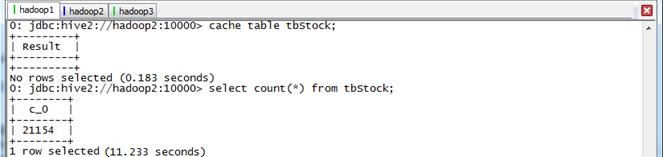
本次计算划给11.233秒,查看webUI,数据已经缓存,缓存率为100%:
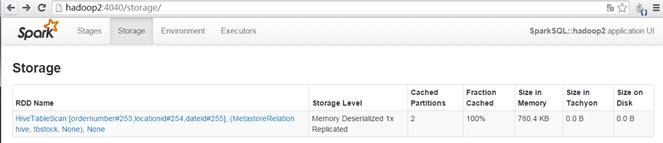
第三步 在另外节点再次运行
在hadoop3节点启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000连接ThriftServer,然后直接运行对tbStock计数(注意没有进行数据库的切换):

用时0.343秒,再查看webUI中的stage:

Locality Level是PROCESS,显然是使用了缓存表。
从上可以看出,ThriftServer可以连接多个JDBC/ODBC客户端,并相互之间可以共享数据。顺便提一句,ThriftServer启动后处于监听状态,用户可以使用ctrl+c退出ThriftServer;而beeline的退出使用!q命令。
4.2.6 在IDEA中JDBC访问
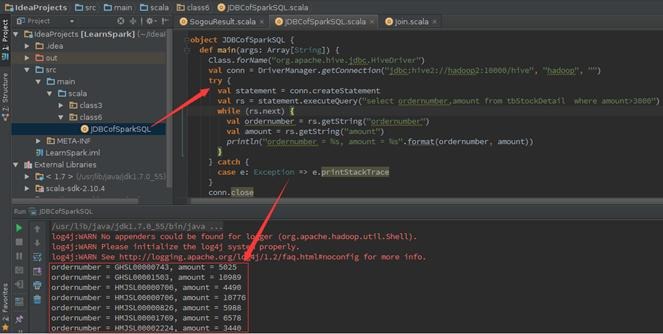
有了ThriftServer,开发人员可以非常方便的使用JDBC/ODBC来访问SparkSQL。下面是一个scala代码,查询表tbStockDetail,返回amount>3000的单据号和交易金额:
第一步 在IDEA创建class6包和类JDBCofSparkSQL
的订单:
package class6
import java.sql.DriverManager
object JDBCofSparkSQL {
def main(args: Array[String]) {
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://hadoop2:10000/hive", "hadoop", "")
try {
val statement = conn.createStatement
val rs = statement.executeQuery("select ordernumber,amount from tbStockDetail where amount>3000")
while (rs.next) {
val ordernumber = rs.getString("ordernumber")
val amount = rs.getString("amount")
println("ordernumber = %s, amount = %s".format(ordernumber, amount))
}
} catch {
case e: Exception => e.printStackTrace
}
conn.close
}
}
第二步 查看运行结果
在IDEA中可以观察到,在运行日志窗口中没有运行过程的日志,只显示查询结果
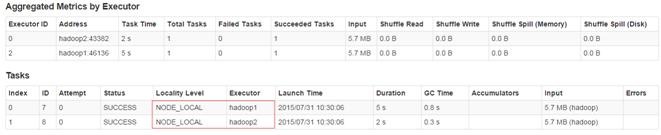
第三步 查看监控结果
的Stage,该Stage有2个Task,分别运行在hadoop1和hadoop2节点,获取数据为NODE_LOCAL方式。


在hadoop2中观察Thrift Server运行日志如下:
Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介的更多相关文章
- Spark入门实战系列--6.SparkSQL(中)--深入了解SparkSQL运行计划及调优
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.1 运行环境说明 1.1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
随机推荐
- FastCgi 与 PHP-FPM
- 如果现在请求的是 /index.php,根据配置文件,nginx 知道这个不.是静态文件,需要去找 PHP 解析器来处理,那么他会把这个请求简单处理后交给 PHP 解析器.Nginx 会传哪些数据 ...
- 【C++】自绘控件基础
由于我们对控件的功能.外观的需求,公共控件并不能很好地满足这一点,所以我们就得自绘控件. 自绘控件有许多方法,比如:处理WM_PAINT消息,设置ownDraw风格,处理WM_CTLCOLOR消息,等 ...
- Inno Setup 下载安装
Inno Setup 是一个免费的 Windows 安装程序制作软件.第一次发表是在 1997 年,Inno Setup 今天在功能设置和稳定性上的竞争力可能已经超过一些商业的安装程序制作软件. 目前 ...
- Android学习笔记之消息机制
Android的消息机制主要是指Handler的运行机制以及Handler所附带的MessageQueue和Looper的工作过程. 1.为什么要使用Handler? Android规定访问UI只 ...
- 一个简单的RMAN自动备份脚本
rman备份脚本: #!/bin/bashsource /home/oracle/.bash_profile rman target / << EOFrun {allocate chann ...
- 3年的坚持,最终造就著作——《Learninghard C#学习笔记》
前言 起初开始写博文主要是记录学习过程中对学到内容的自我总结和理解,同时也希望本人的理解可以帮助到一些走在学习路上的朋友.但是令我没有想到的是,我总结的博文得到了广大园友的评论和支持,正是博友的支持, ...
- 深入理解CSS弹性盒模型flex
× 目录 [1]版本更迭 [2]display [3]基本概念[4]伸缩容器[5]伸缩项目 前面的话 CSS3引入了一种新的布局模型——flex布局.flex是flexible box的缩写,一般称之 ...
- javascript中this指针探讨
javascript是一门类java语言有很多跟java相类似的特点,但也仅是类似而已,真正使用中还是有很大的差别.this指针常常让很多初学者抓狂,本人也曾为此困惑不解,查找过很多资料,今天在这里总 ...
- JavaScript使用DeviceOne开发实战(四)仿优酷视频应用
开发之前需要考虑系统的差异性,比如ios手机没有回退键,所以在开发时一定要考虑二级界面需要有回退键,否则ios的手机就会陷入到这个页面出不去了.安卓系统有回退键,针对这个情况需要要求用户在3秒钟之内连 ...
- 【吉光片羽】之 Web API
1.在asp项目中直接添加apiController,需要新增Global.asax文件.再增加一个webapiConfig,如果需要访问方式为"api/{controller}/{acti ...