Kettle实现MapReduce之WordCount
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载
抽空用kettle配置了一个Mapreduce的Word count,发现还是很方便快捷的,废话不多说,进入正题.
一.创建Mapper转换
如下图,mapper读取hdfs输入,进行word的切分,输出每个word和整数常量值
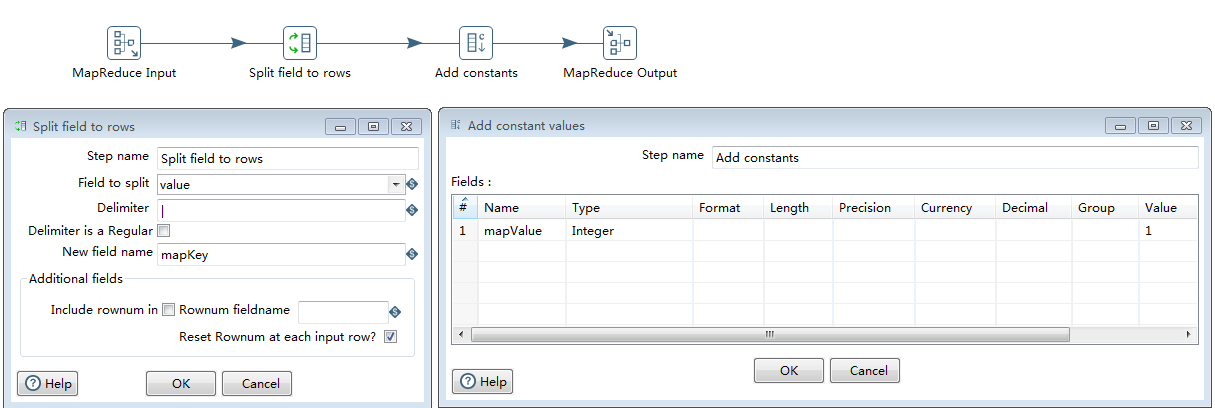
1>MapReduce Input:Mapper输入,读取HDFS上的输入文件内容以键值对存储;
2>Spit filed to rows:读取value值以分隔符 "|" 进行切分(注意我这里hdfs文件中的word是以"|"隔开的)
3>Add constants:给每次出现的word追加一个常量字段mapValue,值为整数1.
4>MapReduce Output:Mapper输出,key为每个word,这里为mapKey,value为常量值mapValue.
二.创建Reducer转换
如下图,Reducer读取mapper的输出.按照每个key值进行分组,对相应的常量值字段进行聚合,这里是做sum,然后最终输出到hdfs文件中去.
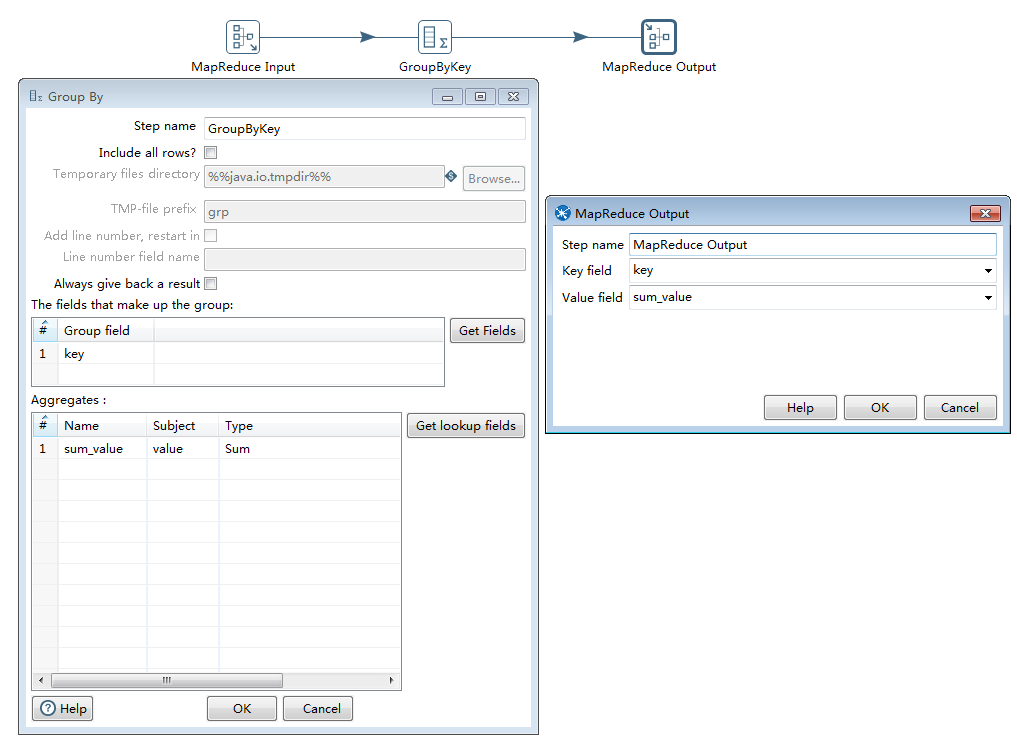
1>MapReduce input:读取Mapper中的输出作为Reducer的输入
2>GroupByKey:按照key进行分组(这里key是每个word), 然后对value进行聚合sum,求出每个word出现的总次数;
3>MapReduce Output:最终的键值对,每行以<单词,总次数>来输出到hdfs上去.
三.创建MapReduce Job.
创建最终的MapReduce Job,配置相应参数,调用Mapper和Reducer,见下图
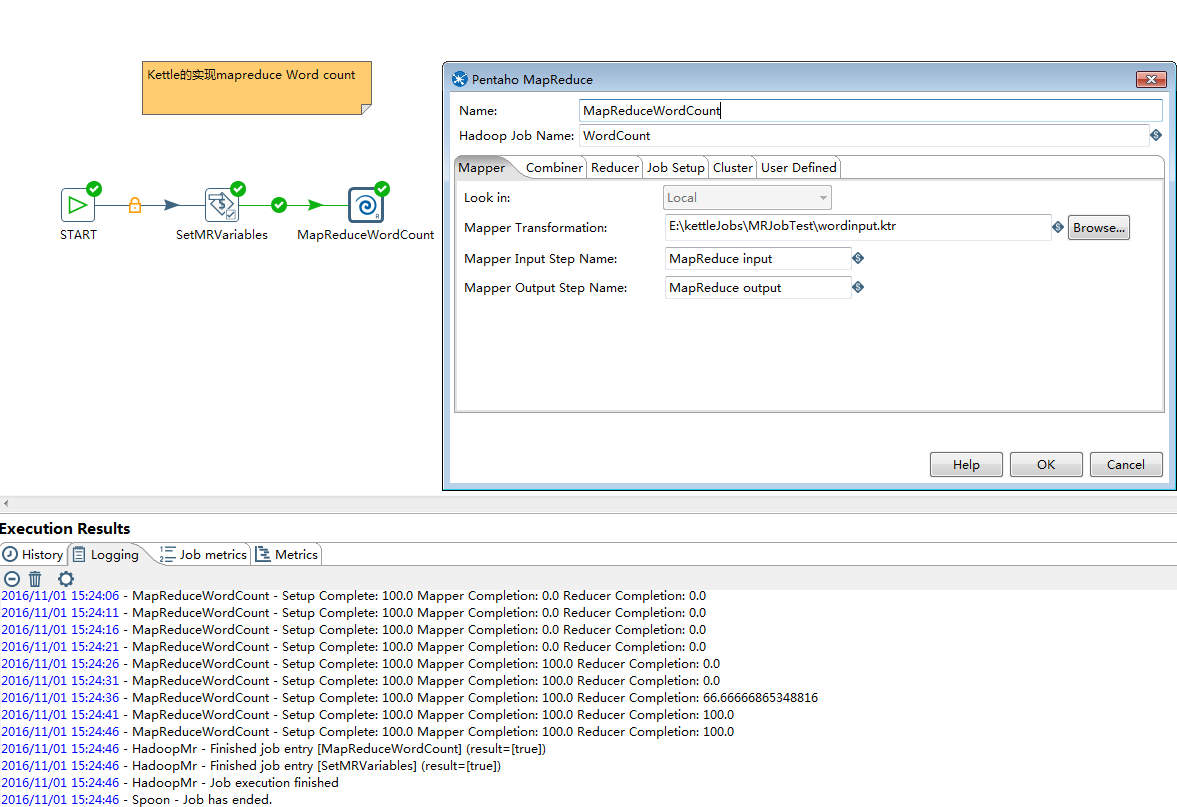
1>START:表示job的开始
2>SetMRVariables:组件是set variables,用于设置一些MapReduce执行所需要的参数的全局变量值,如hdfs input path等;
3>MapReduceWordCount:组件是Pentaho MapReduce组件,用来配置需要调用的Mapper和Reducer以及集群相关信息.
以上配置好以后执行MapReduce Job,会提交至Hadoop集群并运行成功,如上图,可以同时看到MapReduce的执行进度。
鉴于kettle能对字段做各种切分,组合以及正则等处理,还可以自定义java class,所以基本的MR程序都可以快速配置出来.
以上配置的Job下载链接:http://files.cnblogs.com/files/cssdongl/MRJobTest.7z
参考资料:http://wiki.pentaho.com/display/BAD/Understanding+How+Pentaho+works+with+Hadoop
Kettle实现MapReduce之WordCount的更多相关文章
- Java编程MapReduce实现WordCount
Java编程MapReduce实现WordCount 1.编写Mapper package net.toocruel.yarn.mapreduce.wordcount; import org.apac ...
- eclipse运行mapreduce的wordcount
1,eclipse安装hadoop插件 插件下载地址:链接: https://pan.baidu.com/s/1U4_6kLFNiKeLsGfO7ahXew 提取码: as9e 下载hadoop-ec ...
- MapReduce实现WordCount
package algorithm; import java.io.IOException; import java.util.StringTokenizer; import org.apache.h ...
- Hadoop实战5:MapReduce编程-WordCount统计单词个数-eclipse-java-windows环境
Hadoop研发在java环境的拓展 一 背景 由于一直使用hadoop streaming形式编写mapreduce程序,所以目前的hadoop程序局限于python语言.下面为了拓展java语言研 ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
- Hadoop 6、第一个mapreduce程序 WordCount
1.程序代码 Map: import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.h ...
- Hadoop Mapreduce中wordcount 过程解析
将文件split 文件1: 分割结果: hello world ...
- 三.hadoop mapreduce之WordCount例子
目录: 目录见文章1 这个案列完成对单词的计数,重写map,与reduce方法,完成对mapreduce的理解. Mapreduce初析 Mapreduce是一个计算框架,既然是做计算的框架,那么表现 ...
- 大数据技术 - 通俗理解MapReduce之WordCount(三)
上一章我们编写了简单的 MapReduce 程序,掌握这些就能编写大多数数据处理的代码.但是 MapReduce 框架提供给用户的能力并不止如此,本章我们仍然以上一章 word count 为例,继续 ...
随机推荐
- Linux下安装mysql数据库
l 检查是否已安装mysql的相关包 [root@localhost ~]# rpm -qa|grep -i mysql MySQL-server-5.6.19-1.el6.x86_64 MySQL- ...
- myrocks 之数据字典
data dictionary rocksdb作为mysql的一个新的存储引擎,在存储引擎层,会维护自已的元数据信息.在innodb存储引擎中,我们通过information_schema下的INNO ...
- SQL Saturday活动再起
SQL Saturday活动再起 时间:2015年05月09日(星期六) 地点:上海徐汇区港汇2座10楼(10.073) 我们相约港汇2座10楼(10.073),SQL PASS上海分会的SQLSat ...
- Emberjs之Observer
Observer Person.reopen({ fullNameChanged: Ember.observer('fullName', function() { // deal with the c ...
- (小常识)Dictionary的遍历
Dictionary<int, string> objDictionary = new Dictionary<int, string>(); ...
- UWP入门教程1——UWP的前世今生
目录 引言 设备族群 UI 和通用输入模式 通用控件和布局面板 工具 自适应扩展 通用输入处理 引言 在本篇文章中,可以掌握以下知识: 设备族群,如何决定目标设备 新的UI控件和新面板帮助你适应不同的 ...
- MySQL 5.7新特性之Generated Column(函数索引)
MySQL 5.7引入了Generated Column,这篇文章简单地介绍了Generated Column的使用方法和注意事项,为读者了解MySQL 5.7提供一个快速的.完整的教程.这篇文章围绕 ...
- 说说设计模式~观察者模式(Observer)
返回目录 观察者模式,也叫发布/订阅模式(publish/subscribe),监视器模式等.在此种模式中,一个目标物件管理所有相依于它的观察者物件,并且在它本身的状态改变时主动发出通知.这通常透过呼 ...
- WebApi系列~实际项目中如何使用HttpClient向web api发异步Get和Post请求并且参数于具体实体类型
回到目录 本讲比较实际,在WEB端有一个Index和Create方法,用来从web api显示实体列表数据和向api插入实体对象,这就是以往的网站,只不过是把数据持久化过程放到了web pai上面,它 ...
- [CSS]复选框单选框与文字对齐问题的研究与解决.
前言:今天碰到的这个问题, 恰好找到一个很好的博文, 在这里转载过来 学习下. 原文地址:复选框单选框与文字对齐问题的研究与解决. 目前中文网站上面的文字,就我的个人感觉而言,绝大多数网站的主流文字大 ...