SparkSql 整合 Hive
SparkSql整合Hive
需要Hive的元数据,hive的元数据存储在Mysql里,sparkSql替换了yarn,不需要启动yarn,需要启动hdfs
首先你得有hive,然后你得有spark,如果是高可用hadoop还得有zookeeper,还得有dfs(hadoop中的)
我这里有3台节点node01,node02,node03
ps:DATEDIFF(A,B)做差集
node01
先copy hive的hive-site.xml到spark 的config
cp hive-site.xml /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /export/servers/spark-2.0.2/conf/
然后在spark config目录scp到其它节点
scp hive-site.xml node02:$PWD
scp hive-site.xml node03:$PWD

拷贝mysql驱动包到spark jars目录(之前装hive因为Hive要把元数据存在mysql中,所以我之前将Mysql驱动包copy至hive/lib下)
cp /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar /export/servers/spark-2.0.2/jars/
将mysql驱动拷贝至其他节点spark目录下
首先进入到spark/jars目录
cd /export/servers/spark-2.0.2/jars/
拷贝(我配了免密登录,并且有主机名映射ip)
scp mysql-connector-java-5.1.38.jar node02:$PWD
scp mysql-connector-java-5.1.38.jar node03:$PWD

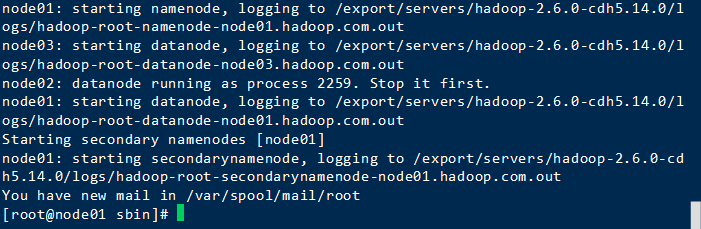
因为待会要在hdfs的文件中测试,所以需要启动dfs,不启动yarn
进入hadoop/sbin目录后,启动
./start-dfs.sh
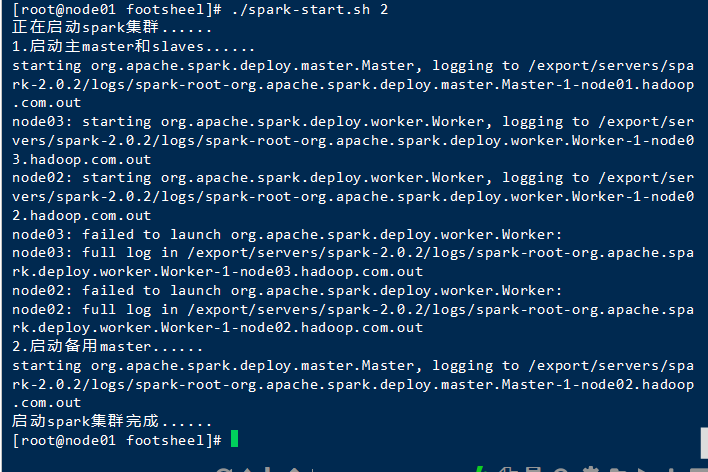
启动spark集群(我把他们封装到了一个脚本里=>如果需要,请点击我下载待定)
脚本启动
./spark-start.sh 2
测试
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
失败了

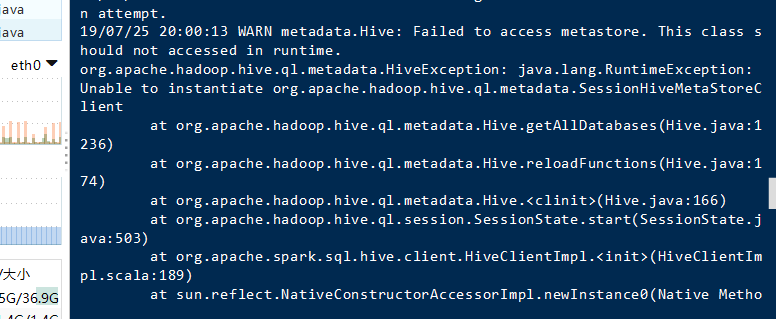
这行代码错误的原因是,因为之前我和impala整合过,但是我未启动impala。
解决方案
进入node01
hive/conf下打开hive-site.xml
注释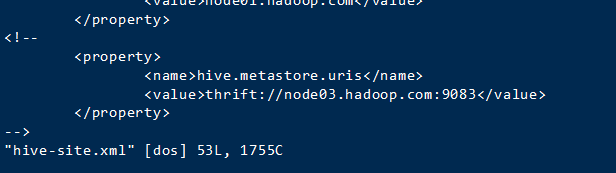
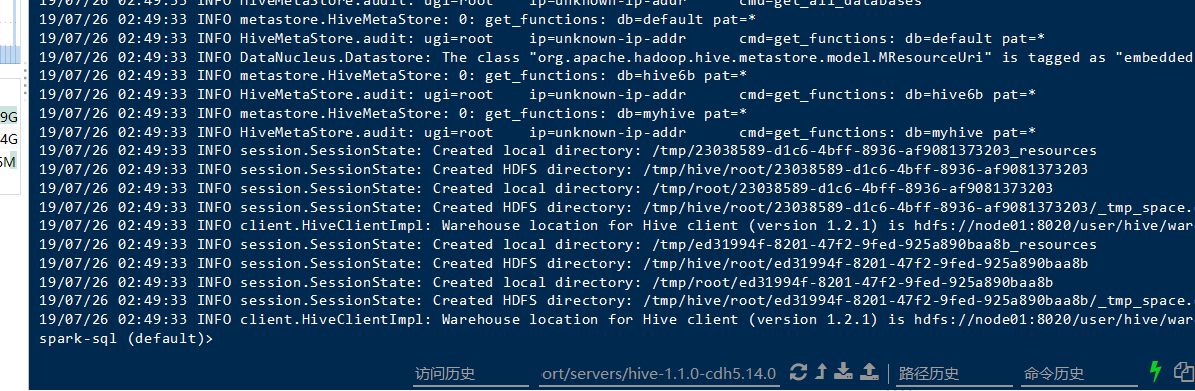
重新启动
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
成功
SparkSql 整合 Hive的更多相关文章
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- 3.sparkSQL整合Hive
spark SQL经常需要访问Hive metastore,Spark SQL可以通过Hive metastore获取Hive表的元数据.从Spark 1.4.0开始,Spark SQL只需简单的配置 ...
- 【Spark】帮你搞明白怎么通过SparkSQL整合Hive
文章目录 一.创建maven工程,导包 二.开发代码 一.创建maven工程,导包 <properties> <scala.version>2.11.8</scala.v ...
- Hive环境搭建和SparkSql整合
一.搭建准备环境 在搭建Hive和SparkSql进行整合之前,首先需要搭建完成HDFS和Spark相关环境 这里使用Hive和Spark进行整合的目的主要是: 1.使用Hive对SparkSql中产 ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- Spark整合Hive
spark-sql 写代码方式 1.idea里面将代码编写好打包上传到集群中运行,上线使用 spark-submit提交 2.spark shell (repl) 里面使用sqlContext 测试使 ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
随机推荐
- JS简单数据类型
JS数据类型 在计算机中,不同的数据所需要占用的空间是不同的,为了便于把数据分析称所需内存大小不同的数据,充分利用存储空间,于是定义了不同的数据类型 简单数据类型 简单数据类型 说明 默认值 Numb ...
- This app has crashed because it attempted to access privacy-sensitive data without a usage description. The app's Info.plist must contain an NSPhotoLibraryAddUsageDescription key with a string value
iOS10 11之后遇到这种报错的小伙伴们请注意啦: 你会发现网上一大堆博客和论坛都是让你在 Info.plist 里面要涉及隐私数据时要添加一句“提示语”.于是打开 Info.plist,点击 + ...
- IOS-dequeueReusableCellWithIdentifier的应用
这是个uitableviewcell重用的函数.当一个列表中的布局相同只是数据不同时,我们可以重用我们的cell,不需要再重复创建.上面代码的意思是,先根据identifier去重用列表中找有没有可以 ...
- mysql 查询指定数据库中的表明和字段名
SELECT TABLE_NAME,COLUMN_NAME,COLUMN_COMMENT FROM INFORMATION_SCHEMA.COLUMNS WHERE COLUMN_COMMENT LI ...
- QT--HTTP文件下载器
QT--HTTP文件下载器 1.pro文件添加 QT += core gui network 2.头文件 #include <QNetworkAccessManager> #i ...
- WPF button 图片显示
btn1.Background = new ImageBrush(new BitmapImage(new Uri(@"pack://application:,,,/Picture/PreSe ...
- 二、ITK例子-jpg图像读写
一.ITK的读写工作原理 在ITK里面,我们需要设置读取图像的像素类型,图像类型. 然后设置读取指针,将读取参数传入. 同时设置写指针,也将写入文件参数传入. 为了实现读写动作,我们需要构造一个IO工 ...
- 踩坑---vue-cli搭建的项目中localhost不能访问
只需要在config文件夹里面的index.js文件里面的module.exports下面的dev中的 host:'localhost' 改为 host:'0.0.0.0' ,然后重启服务器
- python 1 默写用递归实现无限极分类 2 默写用树实现无限极分类
data=[ {"cat_id":3,"name":"沙河","parent_id":1}, {"cat_id ...
- mysql用户数据库只读权限提升全局权限
1.只读用户登录数据库 2.执行命令: mysql> unlock tables;mysql> set global read_only=0;