《专访 RocketMQ 联合创始人:项目思路、技术细节和未来规划》
专访 RocketMQ 联合创始人:项目思路、技术细节和未来规划
阅读数:138092017 年 2 月 20 日 18:00
编者按
这些年开源氛围越来越好,各大 IT 公司都纷纷将一些自研代码开源出来。2012 年,阿里巴巴开源其自研的第三代分布式消息中间件——RocketMQ。经过几年的技术打磨,阿里称基于 RocketMQ 技术,目前双十一当天消息容量可达到万亿级。
2016 年 11 月,阿里将 RocketMQ 捐献给 Apache 软件基金会,正式成为孵化项目。阿里称会将其打造成顶级项目。这是阿里迈出的一大步,因为加入到开源软件基金会需要经过评审方的考核与观察。坦率而言,业界还对国人的代码开源参与度仍保持着刻板印象;而 Apache 基金会中的 342 个项目中,暂时还只有 Kylin、CarbonData、Eagle 和 RocketMQ 共计四个中国技术人主导的项目。
2017 年 2 月 20 日,RocketMQ 正式发布 4.0 版本,专家称新版本适用于电商领域,金融领域,大数据领域,兼有物联网领域的编程模型。
RocketMQ 项目,究竟用怎样的技术内涵?缘何赢得了基金会的初步认可?入驻基金会可以给技术圈哪些启示?InfoQ 带着这样的疑问对两位项目联合创始人进行了专访,内容整理如下。
受访者简介
王小瑞,花名誓嘉,阿里巴巴中间件消息团队负责人,具有丰富的高可用,高可靠分布式系统构建经验,主导了阿里巴巴多次双十一消息引擎的改进优化项目,拥有多项分布式领域的专利。Apache RocketMQ 联合创始人。联系方式: vintagewang@apache.org
冯嘉,花名鼬神,阿里巴巴中间件架构师,具有丰富的分布式软件架构、高并发网站设计、性能调优经验,拥有多项分布式领域的专利。开源爱好者,专注分布式、大数据领域,关注 Hbase/Hadoop/Spark/Flink 等大数据技术栈。目前负责阿里消息中间件生态输出、云上商业化,Apache RocketMQ 联合创始人。联系方式: vongosling@apache.org
RocketMQ 的由来
谈起 RocketMQ 的亮点,那不得不先提一下阿里巴巴消息引擎的演进史。阿里中间件消息引擎发展到今日,前前后后经历了三代演进。
第一代,推模式,数据存储采用关系型数据库。在这种模式下,消息具有很低的延迟特性,并且很容易支持分布式事务。尤其在阿里淘宝这种高频交易场景中,具有非常广泛地应用。典型代表包括 Notify、Napoli。
第二代,拉模式,自研的专有消息存储。在日志处理方面能够媲美 Kafka 的吞吐性能,但考虑到淘宝的应用场景,尤其是其交易链路的高可靠需求,消息引擎并没有一味的追求吞吐,而是将稳定可靠放在首位。因为采用了长连接拉模式,在消息的实时方面丝毫不逊推模式。典型代表 MetaQ。
第三代,以拉模式为主,兼有推模式的高性能、低延迟消息引擎 RocketMQ,在二代功能特性的基础上,为电商金融领域添加了可靠重试、基于文件存储的分布式事务等特性,并做了大量优化。从 2012 年开始,经历了历次双 11 核心交易链路检验。目前已经捐赠给 Apache 基金会。时至今日,RocketMQ 很好的服务了阿里集团大大小小上千个应用,在双 11 当天,更有不可思议的万亿级消息流转,为集团大中台的稳定发挥了举足轻重的作用。
不难看出,RocketMQ 其实是伴随着阿里巴巴整个生态的成长,逐渐衍生出来的高性能、低延迟能够同时满足电商领域和金融领域的极尽苛刻场景的消息中间件。
RocketMQ 的技术概览
在我们看来,它最大的创新点在于能够通过精巧的横向、纵向扩展,不断满足与日俱增的海量消息在高吞吐、高可靠、低延迟方面的要求。
目前 RocketMQ 主要由 NameServer、Broker、Producer 以及 Consumer 四部分构成,如下图所示。

所有的集群都具有水平扩展能力,无单点障碍。
NameServer 以轻量级的方式提供服务发现和路由功能,每个 NameServer 存有全量的路由信息,提供对等的读写服务,支持快速扩缩容。
Broker 负责消息存储,以 Topic 为纬度支持轻量级的队列,单机可以支撑上万队列规模,支持消息推拉模型,具备多副本容错机制(2 副本或 3 副本)、强大的削峰填谷以及上亿级消息堆积能力,同时可严格保证消息的有序性。除此之外,Broker 还提供了同城异地容灾能力,丰富的 Metrics 统计以及告警机制。这些都是传统消息系统无法比拟的。
Producer 由用户进行分布式部署,消息由 Producer 通过多种负载均衡模式发送到 Broker 集群,发送低延时,支持快速失败。
Consumer 也由用户部署,支持 PUSH 和 PULL 两种消费模式,支持集群消费和广播消息,提供实时的消息订阅机制,满足大多数消费场景。
经历双 11 洗礼的英雄
在备战 2016 年双十一时,团队重点做了两件事情,优化慢请求与统一存储引擎。
- 优化慢请求:这里主要是解决在海量高并发场景下降低慢请求对整个集群带来的抖动,毛刺问题。这是一个极具挑战的技术活,团队同学经过长达 1 个多月的跟进调优,从双十一的复盘情况来看,99.996% 的延迟落在了 10ms 以内,而 99.6% 的延迟在 1ms 以内。优化主要集中在 RocketMQ 存储层算法优化、JVM 与操作系统调优。更多的细节大家可以参考我们之前写的电子书章节《万亿级数据洪峰下的分布式消息引擎》。
- 再来看看统一存储引擎:主要解决的消息引擎的高可用,成本问题。在多代消息引擎共存的前提下,我们对 Notify 的存储模块进行了全面移植与替换。
这样下来,阿里巴巴内部的消息中间件就全面拥抱了 RocketMQ 的低延迟存储引擎。基于上述积极的技术准备,在 16 年双十一期间,阿里集团大约有 1.2 万亿级的消息流转总量,几乎是 15 年双十一大促的 2 倍。峰值期间,消息生产的吞吐在 2000 w/s 左右,消息消费的吞吐也近乎 1500 w/s 的量级。整个大促下来,用我们内部的话来说,如丝般顺滑。
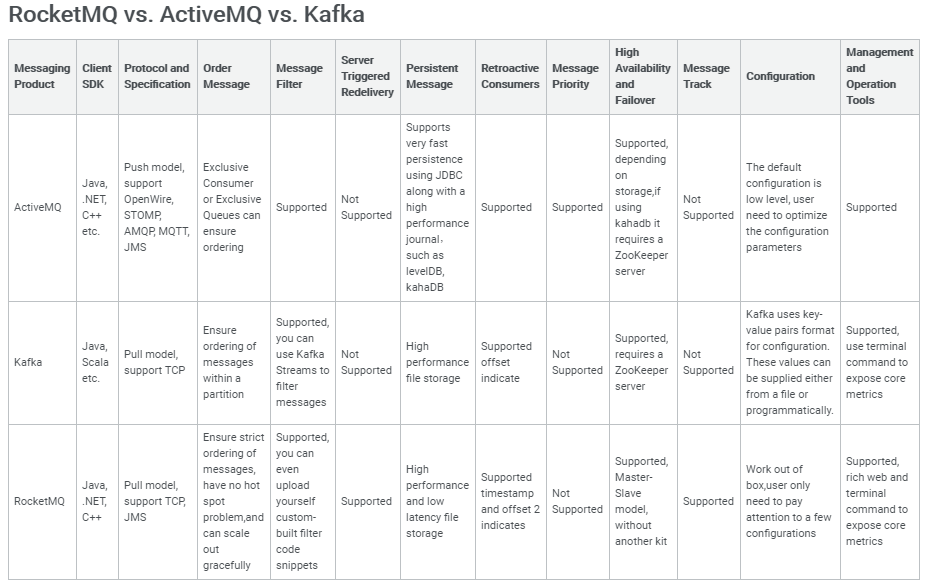
RocketMQ VS 其他几个消息中间件
请从技术构思、实践表现和适用场景三个大方向对 RocketMQ、RabbitMQ、Kafka、ActiveMQ 和 ZeroMQ 进行对比?除了技术上的较量,可否对这些中间件背后的社区运营、商业案例应用,进行对比呢?
1、是不是 CS 架构?
如果需要做同类产品之间的横向对比,我们优先拿下 ZeroMQ,ZeroMQ 正如其名 0MQ,它更像是一个嵌入式的网络类库,一个专注于 transports 层的通讯组件,而不是传统意义上的 CS 架构的 MQ。
2、实现的哪种规范 / 协议?
接下来我们来看看 RabbitMQ、ActiveMQ、Kafka 和 RocketMQ 之间的一些对比,从设计思路上来看,RabbitMQ 是 AMQP 规范的参考实现,AMQP 是一个线路层协议,面面俱到,很系统,也稍显复杂。目前 RabbitMQ 已经成为 OpenStack Iaas 平台首选的消息服务,其背后的支持力度不言而喻。
ActiveMQ 最初主要的开发者在 LogicBlaze,现在主要开发红帽,是 JMS 规范的参考实现,也是 Apache 旗下的老牌消息服务引擎。JMS 虽说是一个 API 级别的协议,但其内部还是定义了一些实现约束,不过缺少多语言支撑。ActiveMQ 的生态堪称丰富多彩,在该 Apache 顶级项目下,拥有不少子项目,包括由 HornetMQ 演变而来的 Artemis,基于 Scala 号称下一代 AMQ 的 Apollo 等。
3、适用何类场景?
而 Kafka 最初被设计用来做日志处理,是一个不折不扣的大数据通道,追求高吞吐,存在丢消息的可能。其背后的研发团队也围绕着 Kafka 进行了商业包装,目前在一些中小型公司被广泛使用,国内也有不少忠实的拥捧着。
RocketMQ 天生为金融互联网领域而生,追求高可靠、高可用、高并发、低延迟,是一个阿里巴巴由内而外成功孕育的典范,除了阿里集团上千个应用外,根据我们不完全统计,国内至少有上百家单位、科研教育机构在使用。关于这几个 MQ 产品更详细的特性对比,可以参考我们官网上的说明。

三项技术发力点
(一)消息的顺序
不可否认,顺序消息是 RocketMQ 功能特性上的一个卖点。目前我们做到了全局保序。需要重点说一下,这里的全局是有前提,针对某个唯一标识(能够被 Hash 成唯一标识),比方说大卖家账号,某类产品的订单等。其技术实现原理也相对比较简单,保证对通道的单一实例操作,如单进程、单线程写,单进程、线程读,像 ActiveMQ 的 Exclusive Consumer 也是类似的实现。
不难看出,这种实现方式实际是在吞吐上做出了一定牺牲。另外也带来了另外一个问题 - 热点。如双十一当天,如果使用简单的散列策略,像短期内就交易过亿的天猫商家的消息会发送到一个通道里面,造成单通道,甚至单机的热点问题在最新的 RocketMQ 版本里,我们将会改进目前的实现,借此改善因为顺序导致的单通道热点问题,这个特性预计今年中旬会发布。
(二)消息的去重
消息领域有一个对消息投递的 QoS 定义,分为:最多一次(At most once),至少一次(At least once),仅一次( Exactly once)。
几乎所有的 MQ 产品都声称自己做到了 At least once。既然是至少一次,那避免不了消息重复,尤其是在分布式网络环境下,而这个缺憾归根结底也可以看做是 TCP 协议的一部分,如失败重传。业务上往往对消息重复又很敏感,RocketMQ 目前的版本是不支持去重的,我们通常建议用户通过外置全局存储自己做判重处理。在下一代的特性规划里,我们会内置解决方案。先说下业界通用做法,像 Artemis,IronMQ 等,通过在服务端全局存储判重。这是一个 IO 敏感的操作,为服务端带来一定的负载。而 RocketMQ 则希望通过采取二次判重策略,有效降低服务端 IO。
(三)分布式的挑战
首先明确分布式系统这个概念:分布式系统是由一系列分散自治组件通过互联网并行并发协作,从而组成的一个 coherent 软件系统。它具备资源共享,并行并发,可靠容错,透明开放等特性。像 CAP,BASE,Paxos,事务等一起构成了分布式基础理论。
这里我们再来重温下 CAP 理论:CAP 分别代表一致性(Consistency),可用性(Availability),分区容忍性(Partition tolerance)。一致性,Eric Brewer(CAP 理论提出者)用一个服务要么被执行,要么不被执行来定义 (原文:A service that is consistent operates fully or not at all)。请注意,这里的一致性是有别于数据库 ACID 属性中的 C,数据库层面的 C 指的是数据的操作不能破坏数据之间的完整性约束,如外键约束。在分布式环境中,可以把 C 简单理解为多节点看到的是数据单一或者同一副本。可用性,意味着服务是可用的(原文:the service is available (to operate fully or not as above))。可用性又可以细分为写可用和读可用。在分布式环境中,往往指的是系统在确定时间内可返回读写操作结果,也即读写均可用。分区容忍性,除了整个网络故障外(如光纤被掘断),其它故障(如丢包、乱序、抖动、甚至是网络分区节点 crash )都不能导致整个系统无法正确响应(原文:No set of failures less than total network failure is allowed to cause the system to respond incorrectly)。
CAP 理论可以看做是探索适合不同应用的一致性与可用性平衡问题。
- 没有分区的情况:可以同时满足 C 与 A,以及完整的 ACID 事务支持。可以选择牺牲一定的 C,获得更好的性能与扩展性。
- 分区的情况:选择 A(集中关注分区的恢复),需要有分区开始前、进行中、恢复后的处理策略,应用合适的补偿处理机制。像 RocketMQ 这样的分布式消息引擎,更多的追求 AP。再强的系统也一定有容量底线,足够的容量是可用性的有效前提。通常情况下,会通过降级、限流、熔断机制来保障洪峰下的可用性。具体的技术细节可以参看电子书章节。
另外,考虑到在金融高频交易典型场景,我们也为 RocketMQ 设计了 CP 机制,在满足分布式系统的分区容错性的前提下,牺牲系统可用性来保证数据的一致性。而技术实现上,则基于 Zab 一致性协议,利用分布式锁和通知机制,以此来保障多副本数据的一致性。
开源捐赠和社区运营
目前国内外有很多公司会把一些通用问题的解决方案,尤其是那些久经考验、愈久弥坚的产品开源出来,以期望在品牌宣传、人才引进方面有所建树。把 RocketMQ 开源出来,甚至捐赠给 Apache,内部也是经过了深思熟虑,层层审批与讨论,期望能够在生态化、规范化、国际化、商业化方面深耕细作。
开源捐赠的想法实际上始于 2014 年。当时,我们甄选了几位 Apache 社区权威人士,遗憾的是反复沟通不断修改草案之后突然间失去了联系。2015 年,我们有幸结识了 Kylin Principal Architect 蒋旭和 VP Luke 以及 RedHat Principal Software Engineer 姜宁,请教了一些 Apache 禁忌事项,重新活跃起来了捐赠进程。接下来,最重要的是征集 champion 候选人,很开心的是 ActiveMQ VP Bruce 爽快地接收了我们的邀请,经过前前后后接近 100 封邮件来往,我们终于正式开启了 Apache 之旅。捐赠投票是在双十一当天,我们准备充分很好地回答了评委会的犀利问题。不过,面对“中国开发者不喜欢邮件沟通”突然刁难,还要感谢社区华人的防御性声明回应。经过很多磨难,投票结果总算出来了:还不算坏 10 票赞同,带 binding(IPMC 成员的有效投票)的 +1,无反对票,正式进入孵化期。孵化成功后有望成为国内首个互联网中间件在 Apache 上的顶级项目,成为全球继 ActiveMQ,Kafka 之后,分布式消息引擎家族中的重要成员。
接下来,我们想强调下知识产权这个对大多数工程师来说陌生的领域,尤其是专利权、著作权、商标权。在国外,每年因为这些问题导致的侵权官司不在少数。而我们在开源之初,对这块的选择、保护也是极其谨慎,包括开源许可协议的选择、授权方面,代码署名权等,这些都是很好的智力保护,也是我们产品的核心竞争力之一。尊重知识,尊重产权,才能构建一个和谐积极向上的开源氛围,打造真正的自主知识产权品牌产品。
在 Alibaba,我们基于开源引擎的 RocketMQ,为云上用户提供了商业化版本的Aliware MQ。两个产品都是由阿里中间件消息团队出品。商业版 Aliware MQ 在支持 TCP 、HTTP 和 MQTT 协议接入,功能方面增强了运维管控方面,生态集成的能力(包括可视化的消息轨迹、资源报表统计以及监控报警、Kafka 集成等)。它在公有云上本身具备多机房部署同城高可用容灾特性,目的是满足企业级要求。
关于社区的运营,我们采取了和 Apache 顶级项目基本相似的策略。首先,必须立足于高质量产品本身,从版本规划开始,我们建立了里程碑讨论,Features 设计,编码自测,结对 Review,集成测试,Release 讨论,Release 公告等等一系列规范且高效的软件研发流程。其次,在社区运营层面,则有一系列与社区互动的活动,如线下 meetup、workshop、ApacheCon、不定期的编程马拉松等,吸纳新的 Contributor 和 Committer 进来。
新一代 RocketMQ,蓄势待发
最近,团队也在着手构建下一代 RocketMQ,期望构建一套厂商无关的集线路层、API 层于一体的规范,这也是第四代消息引擎最大的亮点。目前,我们联系了 Twitter、Yahoo 等公司相关技术负责人,共同起草完善这一规范,而 RocketMQ 将会是第一批率先成为参考实现的产品。我们非常期望国内的 MQ 厂商亦或是分布式爱好者能够参与进来,积极在国际开源社区代表国人发声呐喊。
另外,本周,团队刚刚发布了第四代引擎的第一个版本,该版本也是进入 Apache 社区后的首次发版。按照我们的规划,将在今年 4 月左右完成整个引擎的升级重组,非常欢迎大家的使用、反馈以及参与。
最后,更多信息可以移步Apache RocketMQ 官网、云栖社区、中间件官方博客以及阿里巴巴电子书。
专访RocketMQ联合创始人:项目思路、技术细节和未来规划
编者按
这些年开源氛围越来越好,各大IT公司都纷纷将一些自研代码开源出来。2012年,阿里巴巴开源其自研的第三代分布式消息中间件——RocketMQ。经过几年的技术打磨,阿里称基于RocketMQ技术,目前双十一当天消息容量可达到万亿级。
2016年11月,阿里将RocketMQ捐献给Apache软件基金会,正式成为孵化项目。阿里称会将其打造成顶级项目。这是阿里迈出的一大步,因为加入到开源软件基金会需要经过评审方的考核与观察。坦率而言,业界还对国人的代码开源参与度仍保持着刻板印象;而Apache基金会中的342个项目中,暂时还只有Kylin、CarbonData、Eagle 和 RocketMQ 共计四个中国技术人主导的项目。
2017年2月20日,RocketMQ正式发布4.0版本,专家称新版本适用于电商领域,金融领域,大数据领域,兼有物联网领域的编程模型。
RocketMQ项目,究竟用怎样的技术内涵?缘何赢得了基金会的初步认可?入驻基金会可以给技术圈哪些启示?InfoQ带着这样的疑问对两位项目联合创始人进行了专访,内容整理如下。
受访者简介
王小瑞,花名誓嘉,阿里巴巴中间件消息团队负责人,具有丰富的高可用,高可靠分布式系统构建经验,主导了阿里巴巴多次双十一消息引擎的改进优化项目,拥有多项分布式领域的专利。Apache RocketMQ联合创始人。联系方式: vintagewang@apache.org
冯嘉,花名鼬神,阿里巴巴中间件架构师,具有丰富的分布式软件架构、高并发网站设计、性能调优经验,拥有多项分布式领域的专利。开源爱好者,专注分布式、大数据领域,关注Hbase/Hadoop/Spark/Flink等大数据技术栈。目前负责阿里消息中间件生态输出、云上商业化,Apache RocketMQ联合创始人。联系方式: vongosling@apache.org
RocketMQ的由来
谈起RocketMQ的亮点,那不得不先提一下阿里巴巴消息引擎的演进史。阿里中间件消息引擎发展到今日,前前后后经历了三代演进。
第一代,推模式,数据存储采用关系型数据库。在这种模式下,消息具有很低的延迟特性,并且很容易支持分布式事务。尤其在阿里淘宝这种高频交易场景中,具有非常广泛地应用。典型代表包括Notify、Napoli。
第二代,拉模式,自研的专有消息存储。在日志处理方面能够媲美Kafka的吞吐性能,但考虑到淘宝的应用场景,尤其是其交易链路的高可靠需求,消息引擎并没有一味的追求吞吐,而是将稳定可靠放在首位。因为采用了长连接拉模式,在消息的实时方面丝毫不逊推模式。典型代表MetaQ。
第三代,以拉模式为主,兼有推模式的高性能、低延迟消息引擎RocketMQ,在二代功能特性的基础上,为电商金融领域添加了可靠重试、基于文件存储的分布式事务等特性,并做了大量优化。从2012年开始,经历了历次双11核心交易链路检验。目前已经捐赠给Apache基金会。时至今日,RocketMQ很好的服务了阿里集团大大小小上千个应用,在双11当天,更有不可思议的万亿级消息流转,为集团大中台的稳定发挥了举足轻重的作用。
不难看出,RocketMQ其实是伴随着阿里巴巴整个生态的成长,逐渐衍生出来的高性能、低延迟能够同时满足电商领域和金融领域的极尽苛刻场景的消息中间件。
RocketMQ的技术概览
请配图同时对RocketMQ的架构进行说明;请对消息的产生、传输和消费流程进行说明,最好也可以配图。
在我们看来,它最大的创新点在于能够通过精巧的横向、纵向扩展,不断满足与日俱增的海量消息在高吞吐、高可靠、低延迟方面的要求。
目前RocketMQ主要由NameServer、Broker、Producer以及Consumer四部分构成,如下图所示。
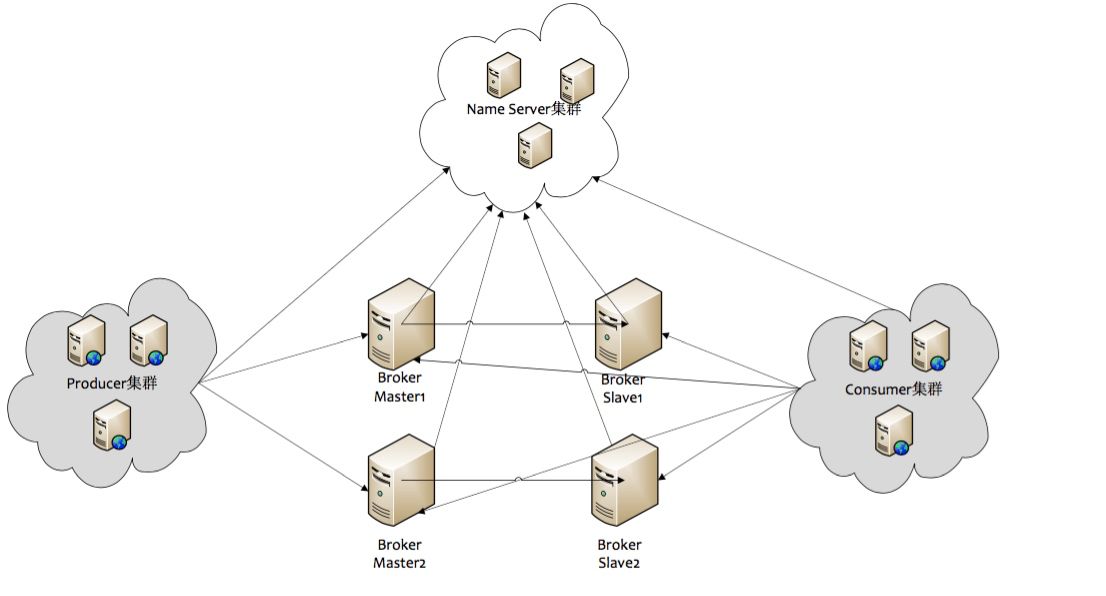
所有的集群都具有水平扩展能力,无单点障碍。
NameServer以轻量级的方式提供服务发现和路由功能,每个NameServer存有全量的路由信息,提供对等的读写服务,支持快速扩缩容。
Broker负责消息存储,以Topic为纬度支持轻量级的队列,单机可以支撑上万队列规模,支持消息推拉模型,具备多副本容错机制(2副本或3副本)、强大的削峰填谷以及上亿级消息堆积能力,同时可严格保证消息的有序性。除此之外,Broker还提供了同城异地容灾能力,丰富的Metrics统计以及告警机制。这些都是传统消息系统无法比拟的。
Producer由用户进行分布式部署,消息由Producer通过多种负载均衡模式发送到Broker集群,发送低延时,支持快速失败。
Consumer也由用户部署,支持PUSH和PULL两种消费模式,支持集群消费和广播消息,提供实时的消息订阅机制,满足大多数消费场景。
经历双11洗礼的英雄
在备战2016年双十一时,团队重点做了两件事情,优化慢请求与统一存储引擎。
- 优化慢请求:这里主要是解决在海量高并发场景下降低慢请求对整个集群带来的抖动,毛刺问题。这是一个极具挑战的技术活,团队同学经过长达1个多月的跟进调优,从双十一的复盘情况来看,99.996%的延迟落在了10ms以内,而99.6%的延迟在1ms以内。优化主要集中在RocketMQ存储层算法优化、JVM与操作系统调优。更多的细节大家可以参考我们之前写的电子书章节《万亿级数据洪峰下的分布式消息引擎》[1]。
- 再来看看统一存储引擎:主要解决的消息引擎的高可用,成本问题。在多代消息引擎共存的前提下,我们对Notify的存储模块进行了全面移植与替换。
这样下来,阿里巴巴内部的消息中间件就全面拥抱了RocketMQ的低延迟存储引擎。基于上述积极的技术准备,在16年双十一期间,阿里集团大约有1.2万亿级的消息流转总量,几乎是15年双十一大促的2倍。峰值期间,消息生产的吞吐在2000 w/s左右,消息消费的吞吐也近乎1500 w/s的量级。整个大促下来,用我们内部的话来说,如丝般顺滑。
RocketMQ VS 其他几个消息中间件
请从技术构思、实践表现和适用场景三个大方向对RocketMQ、RabbitMQ、Kafka、ActiveMQ和ZeroMQ进行对比?除了技术上的较量,可否对这些中间件背后的社区运营、商业案例应用,进行对比呢?
1、是不是CS架构?
如果需要做同类产品之间的横向对比,我们优先拿下ZeroMQ,ZeroMQ正如其名0MQ,它更像是一个嵌入式的网络类库,一个专注于transports层的通讯组件,而不是传统意义上的CS架构的MQ。
2、实现的哪种规范 / 协议?
接下来我们来看看RabbitMQ、ActiveMQ、Kafka和RocketMQ之间的一些对比,从设计思路上来看,RabbitMQ是AMQP规范的参考实现,AMQP是一个线路层协议,面面俱到,很系统,也稍显复杂。目前RabbitMQ已经成为OpenStack Iaas平台首选的消息服务,其背后的支持力度不言而喻。
ActiveMQ最初主要的开发者在LogicBlaze,现在主要开发红帽,是JMS规范的参考实现,也是Apache旗下的老牌消息服务引擎。JMS虽说是一个API级别的协议,但其内部还是定义了一些实现约束,不过缺少多语言支撑。ActiveMQ的生态堪称丰富多彩,在该Apache顶级项目下,拥有不少子项目,包括由HornetMQ演变而来的Artemis,基于Scala号称下一代AMQ的Apollo等。
3、适用何类场景?
而Kafka最初被设计用来做日志处理,是一个不折不扣的大数据通道,追求高吞吐,存在丢消息的可能。其背后的研发团队也围绕着Kafka进行了商业包装,目前在一些中小型公司被广泛使用,国内也有不少忠实的拥捧着。
RocketMQ天生为金融互联网领域而生,追求高可靠、高可用、高并发、低延迟,是一个阿里巴巴由内而外成功孕育的典范,除了阿里集团上千个应用外,根据我们不完全统计,国内至少有上百家单位、科研教育机构在使用。关于这几个MQ产品更详细的特性对比,可以参考我们官网上的说明[2]。
三项技术发力点
(一)消息的顺序
不可否认,顺序消息是RocketMQ功能特性上的一个卖点。目前我们做到了全局保序。需要重点说一下,这里的全局是有前提,针对某个唯一标识(能够被Hash成唯一标识),比方说大卖家账号,某类产品的订单等。其技术实现原理也相对比较简单,保证对通道的单一实例操作,如单进程、单线程写,单进程、线程读,像ActiveMQ的Exclusive Consumer也是类似的实现。
不难看出,这种实现方式实际是在吞吐上做出了一定牺牲。另外也带来了另外一个问题 - 热点。如双十一当天,如果使用简单的散列策略,像短期内就交易过亿的天猫商家的消息会发送到一个通道里面,造成单通道,甚至单机的热点问题在最新的RocketMQ版本里,我们将会改进目前的实现,借此改善因为顺序导致的单通道热点问题,这个特性预计今年中旬会发布。
(二)消息的去重
消息领域有一个对消息投递的QoS定义,分为:最多一次(At most once),至少一次(At least once),仅一次( Exactly once)。
几乎所有的MQ产品都声称自己做到了At least once。既然是至少一次,那避免不了消息重复,尤其是在分布式网络环境下,而这个缺憾归根结底也可以看做是TCP协议的一部分,如失败重传。业务上往往对消息重复又很敏感,RocketMQ目前的版本是不支持去重的,我们通常建议用户通过外置全局存储自己做判重处理。在下一代的特性规划里,我们会内置解决方案。先说下业界通用做法,像Artemis,IronMQ等,通过在服务端全局存储判重。这是一个IO敏感的操作,为服务端带来一定的负载。而RocketMQ则希望通过采取二次判重策略,有效降低服务端IO。
(三)分布式的挑战
首先明确分布式系统这个概念:分布式系统是由一系列分散自治组件通过互联网并行并发协作,从而组成的一个coherent软件系统。它具备资源共享,并行并发,可靠容错,透明开放等特性。像CAP,BASE,Paxos,事务等一起构成了分布式基础理论。
这里我们再来重温下CAP理论:CAP分别代表一致性(Consistency),可用性(Availability),分区容忍性(Partition tolerance)。一致性,Eric Brewer(CAP理论提出者)用一个服务要么被执行,要么不被执行来定义(原文:A service that is consistent operates fully or not at all)。请注意,这里的一致性是有别于数据库ACID属性中的C,数据库层面的C指的是数据的操作不能破坏数据之间的完整性约束,如外键约束。在分布式环境中,可以把C简单理解为多节点看到的是数据单一或者同一副本。可用性,意味着服务是可用的(原文:the service is available (to operate fully or not as above))。可用性又可以细分为写可用和读可用。在分布式环境中,往往指的是系统在确定时间内可返回读写操作结果,也即读写均可用。分区容忍性,除了整个网络故障外(如光纤被掘断),其它故障(如丢包、乱序、抖动、甚至是网络分区节点 crash )都不能导致整个系统无法正确响应(原文:No set of failures less than total network failure is allowed to cause the system to respond incorrectly)。
CAP理论可以看做是探索适合不同应用的一致性与可用性平衡问题。
- 没有分区的情况:可以同时满足C与A,以及完整的ACID事务支持。可以选择牺牲一定的C,获得更好的性能与扩展性。
- 分区的情况:选择A(集中关注分区的恢复),需要有分区开始前、进行中、恢复后的处理策略,应用合适的补偿处理机制。像RocketMQ这样的分布式消息引擎,更多的追求AP。再强的系统也一定有容量底线,足够的容量是可用性的有效前提。通常情况下,会通过降级、限流、熔断机制来保障洪峰下的可用性。具体的技术细节可以参看电子书章节[1]
另外,考虑到在金融高频交易典型场景,我们也为RocketMQ设计了CP机制,在满足分布式系统的分区容错性的前提下,牺牲系统可用性来保证数据的一致性。而技术实现上,则基于Zab一致性协议,利用分布式锁和通知机制,以此来保障多副本数据的一致性。
开源捐赠和社区运营
目前国内外有很多公司会把一些通用问题的解决方案,尤其是那些久经考验、愈久弥坚的产品开源出来,以期望在品牌宣传、人才引进方面有所建树。把RocketMQ开源出来,甚至捐赠给Apache,内部也是经过了深思熟虑,层层审批与讨论,期望能够在生态化、规范化、国际化、商业化方面深耕细作。
开源捐赠的想法实际上始于2014年。当时,我们甄选了几位Apache社区权威人士,遗憾的是反复沟通不断修改草案之后突然间失去了联系。2015年,我们有幸结识了Kylin Principal Architect蒋旭和VP Luke以及RedHat Principal Software Engineer姜宁,请教了一些Apache禁忌事项,重新活跃起来了捐赠进程。接下来,最重要的是征集champion候选人,很开心的是ActiveMQ VP Bruce爽快地接收了我们的邀请,经过前前后后接近100封邮件来往,我们终于正式开启了Apache之旅。捐赠投票是在双十一当天,我们准备充分很好地回答了评委会的犀利问题。不过,面对“中国开发者不喜欢邮件沟通”突然刁难,还要感谢社区华人的防御性声明回应。经过很多磨难,投票结果总算出来了:还不算坏10票赞同,带binding(IPMC成员的有效投票)的+1,无反对票,正式进入孵化期。孵化成功后有望成为国内首个互联网中间件在Apache上的顶级项目,成为全球继ActiveMQ,Kafka之后,分布式消息引擎家族中的重要成员。
接下来,我们想强调下知识产权这个对大多数工程师来说陌生的领域,尤其是专利权、著作权、商标权。在国外,每年因为这些问题导致的侵权官司不在少数。而我们在开源之初,对这块的选择、保护也是极其谨慎,包括开源许可协议的选择、授权方面,代码署名权等,这些都是很好的智力保护,也是我们产品的核心竞争力之一。尊重知识,尊重产权,才能构建一个和谐积极向上的开源氛围,打造真正的自主知识产权品牌产品。
在Alibaba,我们基于开源引擎的RocketMQ,为云上用户提供了商业化版本的Aliware MQ。两个产品都是由阿里中间件消息团队出品。商业版Aliware MQ 在支持 TCP 、HTTP 和MQTT 协议接入,功能方面增强了运维管控方面,生态集成的能力(包括可视化的消息轨迹、资源报表统计以及监控报警、Kafka集成等)。它在公有云上本身具备多机房部署同城高可用容灾特性,目的是满足企业级要求。
关于社区的运营,我们采取了和Apache顶级项目基本相似的策略。首先,必须立足于高质量产品本身,从版本规划开始,我们建立了里程碑讨论,Features设计,编码自测,结对Review,集成测试,Release讨论,Release公告等等一系列规范且高效的软件研发流程。其次,在社区运营层面,则有一系列与社区互动的活动,如线下meetup、workshop、ApacheCon、不定期的编程马拉松等,吸纳新的Contributor和Committer进来。
新一代RocketMQ,蓄势待发
最近,团队也在着手构建下一代RocketMQ,期望构建一套厂商无关的集线路层、API层于一体的规范,这也是第四代消息引擎最大的亮点。目前,我们联系了Twitter、Yahoo等公司相关技术负责人,共同起草完善这一规范,而RocketMQ将会是第一批率先成为参考实现的产品。我们非常期望国内的MQ厂商亦或是分布式爱好者能够参与进来,积极在国际开源社区代表国人发声呐喊。
另外,本周,团队刚刚发布了第四代引擎的第一个版本,该版本也是进入Apache社区后的首次发版。按照我们的规划,将在今年4月左右完成整个引擎的升级重组,非常欢迎大家的使用、反馈以及参与。
最后,更多信息可以移步Apache RocketMQ官网、云栖社区、中间件官方博客以及阿里巴巴电子书。
原文发表于 InfoQ
企业级互联网架构Aliware,让您的业务能力云化:https://www.aliyun.com/aliware
《专访 RocketMQ 联合创始人:项目思路、技术细节和未来规划》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- Flipcart 爬取流程
第一步:爬取分类url from requests_html import HTMLSession session =HTMLSession() #https://www.flipkart.com/l ...
- Java生鲜电商平台-高可用微服务系统如何设计?
Java生鲜电商平台-高可用微服务系统如何设计? 说明:Java生鲜电商平台高可用架构往往有以下的要求: 高可用.这类的系统往往需要保持一定的 SLA,7*24 时不间断运行不代表完全不挂,而是有一定 ...
- Git问题汇总
1.fatal: refusing to merge unrelated histories $git pull origin master --allow-unrelated-histories 2 ...
- Tornado—接口调用时方法执行顺序
import tornado.web # web服务 import tornado.ioloop # I/O 时间循环 class MainHandler(tornado.web.RequestHan ...
- Centos8 配置静态IP
安装centos 8之后,重启启动网络时,会出现以下报错 报错信息如下: Failed to start network.service: Unit network.service not found ...
- Python的map方法的应用
Map方法,第一个参数要写一个匿名函数表达式,或者是一个函数引用,第二个第三个往后都是表达式用到的参数,参数一般是可迭代的 1.比如下面这个map方法,两个参数,第一个 lambda x: x*x是匿 ...
- vue.set( target, key, value ) this.$set(对象获数组,要更改的具体数据,重新赋值)用法
调用方法:Vue.set( target, key, value ) target:要更改的数据源(可以是对象或者数组) key:要更改的具体数据 value :重新赋的值 具体用法js代码: //设 ...
- git 删除文件/移动文件
1.git rm 删除文件 git restore --file (git老版本:git checkout) git rm --file(本地和管理都已删除) git rm --cached file ...
- Linux目录详解,软件应该安装到哪个目录
原文地址:https://www.w3h5.com/post/336.html 我们应该知道 Windows 有一个默认的安装目录专门用来安装软件.Linux 的软件安装目录也应该是有讲究的,遵循这一 ...
- Vue小练习 02
用table标签渲染下面的数据, 最后一列为总分, 第一列为排名 scores = [ {name: 'Bob', math: 97, chinese: 89, english: 67}, {name ...