Python分页爬取数据的分析
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 向右奔跑
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
对爬虫爬取数据时的分页进行一下总结。分页是爬取到所有数据的关键,一般有这样几种形式: 1、已知记录数,分页大小(pagesize, 一页有多少条记录)
已知总页数(在页面上显示出总页数)
页面上没有总记录数,总页数,但能从分页条中找到总页数
滚动分页,知道总页数
滚动分页,不知道总页数
以上前三种情况比较简单,基本上看一下加载分页数据时的地址栏,或者稍微用Chrome -- network分析一下,就可以了解分页的URL。
一、页面分析,获取分页URL
典型的如豆瓣图书、电影排行榜的分页。
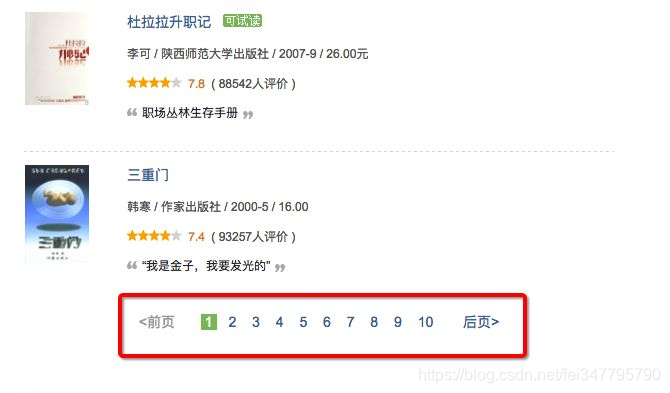
对于像以下这种分页,没有显示总记录数,但从分页条上看到有多少页的,一般的处理方法有两种:一是先把最后一页的页码抓取下来;二是一页一页的访问抓取,直到没有“下一页”。 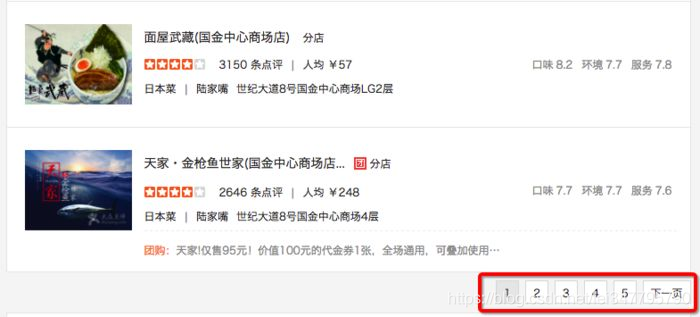
二、用抓包工具,查看分页URL
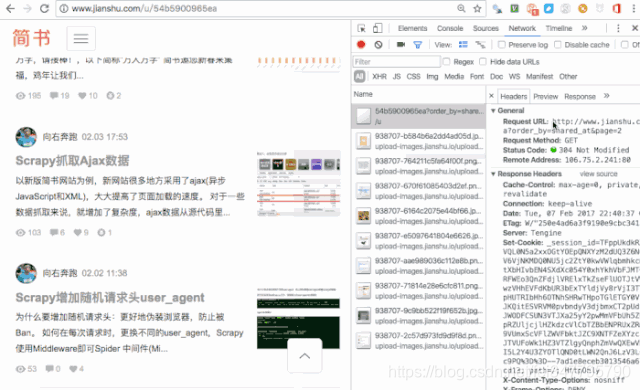
通过抓包工具,获取了分页的URL,再进行总页数的分析,一般是进行计算,如这里,有文章总数量,每页显示的文章数(页大小),就可以计算出总页数。 看一下这个,七日热门文章的分页,比较有意思。这么一长串,是不是比较崩溃。
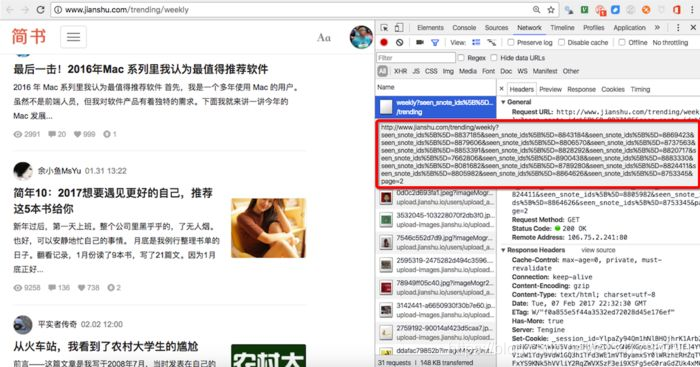
这时候一般要缩短参数,确定关键参数。分页关键的参数是page=2,直接把url减少成这样:

看到就是我们所需要的数据。 再回过头来理解一下,为什么采用了这样一串的URL,可以通过查看response,发现响应的是xml数据(一段网页数据),也就是这里采用了异步加载(AJAX)。
三、抓包分析,需要构造分页URL
这时候,通过抓包分析,还不能获取分页的URL。有时候是抓包到的URL直接放到地址栏也查看不到所要的分页数据,还有时候是分页的URL中有其他参数。
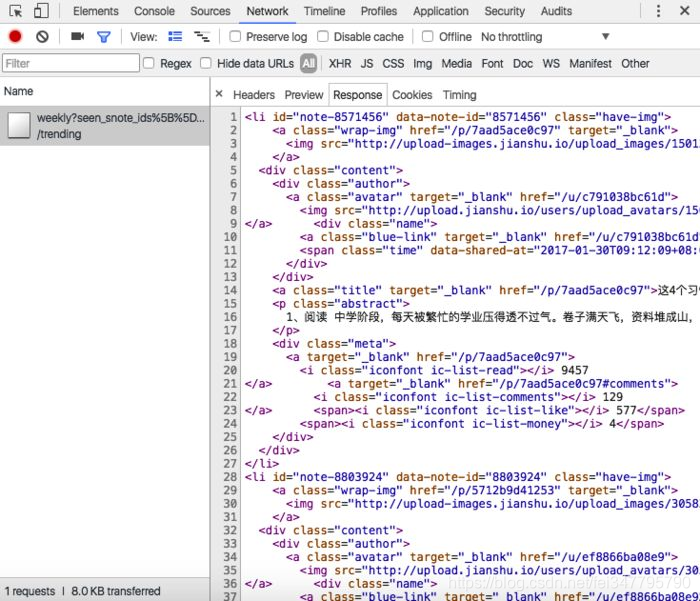
如简书用户“动态”数据分页url,抓包到的是

这里就要了解如何获取max_id这个值。还有一个问题就是要判断是否到了最后一页。 如简书“投稿请求”数据的分页:
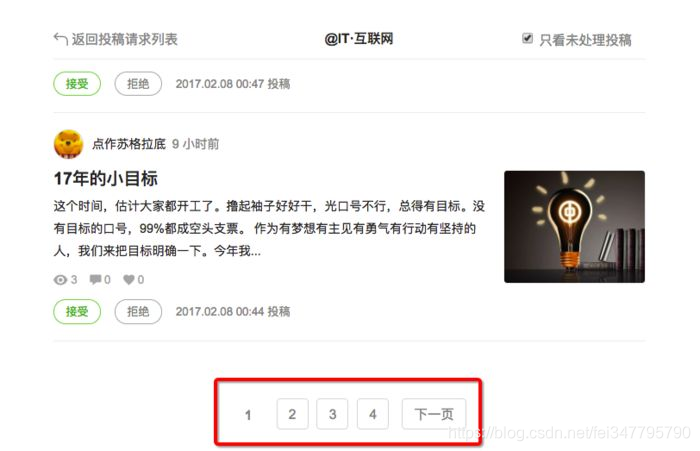
从抓包拿到的分页URL,访问时发现看到的不是我们所要的页面、数据。这时就是根据经验进行分析。基本方法还是结合网页源代码,查看chrome中的response。
Python分页爬取数据的分析的更多相关文章
- 如何分页爬取数据--beautisoup
'''本次爬取讲历史网站'''#!usr/bin/env python#-*- coding:utf-8 _*-"""@author:Hurrican@file: 分页爬 ...
- Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python 网页爬取数据生成文字云图
1. 需要的三个包: from wordcloud import WordCloud #词云库 import matplotlib.pyplot as plt #数学绘图库 import jieba; ...
- python requests 爬取数据
import requests from lxml import etree import time import pymysql import json headers={ 'User-Agent' ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- Python scrapy爬取带验证码的列表数据
首先所需要的环境:(我用的是Python2的,可以选择python3,具体遇到的问题自行解决,目前我这边几百万的数据量爬取) 环境: Python 2.7.10 Scrapy Scrapy 1.5.0 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫爬取天气数据并图形化显示
前言 使用python进行网页数据的爬取现在已经很常见了,而对天气数据的爬取更是入门级的新手操作,很多人学习爬虫都从天气开始,本文便是介绍了从中国天气网爬取天气数据,能够实现输入想要查询的城市,返回该 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
随机推荐
- CSS画一个三角形,CSS绘制空心三角形,CSS实现箭头
壹 ❀ 引 这两天因为项目工作较少,闲下来去看了GitHub上关于面试题日更收录的文章,毕竟明年有新的打算.在CSS收录中有一题是 用css创建一个三角形,并简述原理 .当然对于我来说画一个三角形是 ...
- VSCode 使用 ESLint + Prettier 来统一 JS 代码
环境: VSCode 1.33.1 Node.js 8.9.1 一.ESLint 1.介绍 ESLint是最流行的JavaScript Linter. Linter 是检查代码风格/错误的小工具.其他 ...
- NFS客户端挂载及永久生效
1.NFS客户端挂载的命令格式: 挂载命令 挂载的格式类型 NFS服务器提供的共享目录 NFS客户端要挂载的目录mount -t nfs 服务器IP:/共享目录 /本地的挂载点(必须存在) 重启失效 ...
- Vue 从入门到进阶之路(十四)
之前的文章我们对 vue 的基础用法已经有了很直观的认识,本章我们来看一下 vue 中的生命周期函数. 上图为 Vue官方为我们提供的完整的生命周期函数的流程图,下面的案例我们只是走了部分情况流程,但 ...
- 【HNOI 2017】礼物
Problem Description 我的室友最近喜欢上了一个可爱的小女生.马上就要到她的生日了,他决定买一对情侣手环,一个留给自己,一个送给她.每个手环上各有 \(n\) 个装饰物,并且每个装饰物 ...
- 通过修改VAD属性破除锁页机制
Windows内核分析索引目录:https://www.cnblogs.com/onetrainee/p/11675224.html 技术学习来源:火哥(QQ:471194425) 注释:因为自己的知 ...
- java基础(6):方法
1. 方法 1.1 方法概述 在我们的日常生活中,方法可以理解为要做某件事情,而采取的解决办法. 如:小明同学在路边准备坐车来学校学习.这就面临着一件事情(坐车到学校这件事情)需要解决,解决办法呢?可 ...
- Python3 进程、线程和协程
Infi-chu: http://www.cnblogs.com/Infi-chu/ 进程.线程和协程的对比 1.定义对比 进程:是系统进行资源分配的基本单位,每启动一个进程,操作系统都需要为其分配运 ...
- 【转载】XSS攻击和sql注入
XSS攻击: https://www.cnblogs.com/dolphinX/p/3391351.html 跨站脚本攻击(Cross Site Script为了区别于CSS简称为XSS)指的是恶意攻 ...
- Liu Junqiao:Raid 0 1 5 6 特性
Raid工作原理及优缺点 Raid工作原理及优缺点Raid 0Raid 1Raid 5Raid 6Raid 1 0Raid 5 0Raid 6 0 Raid 0 特点 采用剥离,数据将在几个磁盘上进行 ...